142.如何个性化推荐系统设计-2
Posted 大勇若怯任卷舒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了142.如何个性化推荐系统设计-2相关的知识,希望对你有一定的参考价值。
142.1 离线训练
- 离线训练流程
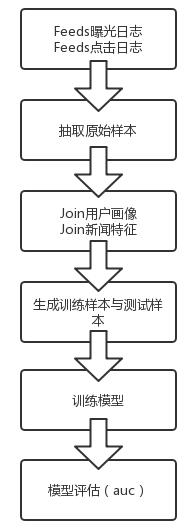
- 如何线上实时反馈特征?
- 在线计算,与曝光日志一起上报,离线直接使用
- 如何解决曝光不足问题?
- 使用CTR的贝叶斯平滑(CTR = 曝光次数 / 点击次数)
- 所有新闻自身CTR®服从Beta分布:
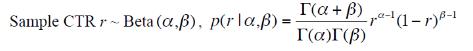
- 某一新闻,给定展示次数时和自身CTR,点击次数服从伯努利分布,曝光次数为I,点击次数为C:
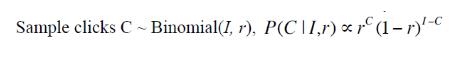
- 对最大似然函数求解参数α,β,则i新闻CTR后验估计:
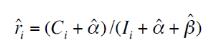
- 对曝光不足的做平滑,曝光充分的影响不大
- 所有新闻自身CTR®服从Beta分布:
- 使用CTR的贝叶斯平滑(CTR = 曝光次数 / 点击次数)
142.2 用户画像
- 用户标签
- 统计方法
- 用户feeds内行为,标签 计数(点击率),缺点:无法加入更多特征,不方便后续优化
- 基于机器学习的方法
- 对用户长期兴趣建模
- LR模型
- 用户标签作为特征
142.3 GBDT粗排
- 为什么需要粗排?
- 快速筛选高质量的候选集
- 方便利用在线实时反馈特征
- 如何做粗排的特征设计?
- 特征要相对稠密
- 如何选择合适的算法模型?
- lightgbm
- xgboost
- lightgbm比xgboot速度更快;在线预测时,线程更安全
142.4 在线FM精排
- 为什么需要在线学习?
- feeds内容更新快
- 用户兴趣会随时间变化
- 排序模型需要快速反应用户的兴趣变化
- FM模型
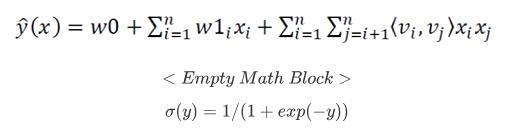
- 采用FTRL(Follow The Regularized Leader)更新模型
- 算法概述
- FTRL是一种适用于处理超大规模数据的,含大量稀疏特征的在线学习的常见优化算法,方便实用,而且效果很好,常用于更新在线的CTR预估模型。
- FTRL算法兼顾了FOBOS和RDA两种算法的优势,既能同FOBOS保证比较高的精度,又能在损失一定精度的情况下产生更好的稀疏性。
- FTRL在处理带非光滑正则项(如L1正则)的凸优化问题上表现非常出色,不仅可以通过L1正则控制模型的稀疏度,而且收敛速度快。
- 算法要点与推导

- 算法特性及优缺点
- 在线学习,实时性高;可以处理大规模稀疏数据;有大规模模型参数训练能力;根据不同的特征特征学习率 。
- FTRL-Proximal工程实现上的tricks:
1.saving memory
方案1)Poisson Inclusion:对某一维度特征所来的训练样本,以p的概率接受并更新模型。
方案2)Bloom Filter Inclusion:用bloom filter从概率上做某一特征出现k次才更新。
2.浮点数重新编码
1)特征权重不需要用32bit或64bit的浮点数存储,存储浪费空间。
2)16bit encoding,但是要注意处理rounding技术对regret带来的影响(注:python可以尝试用numpy.float16格式)
3.训练若干相似model
1)对同一份训练数据序列,同时训练多个相似的model。
2)这些model有各自独享的一些feature,也有一些共享的feature。
3)出发点:有的特征维度可以是各个模型独享的,而有的各个模型共享的特征,可以用同样的数据训练。
4.Single Value Structure
1)多个model公用一个feature存储(例如放到cbase或redis中),各个model都更新这个共有的feature结构。
2)对于某一个model,对于他所训练的特征向量的某一维,直接计算一个迭代结果并与旧值做一个平均。
5.使用正负样本的数目来计算梯度的和(所有的model具有同样的N和P)
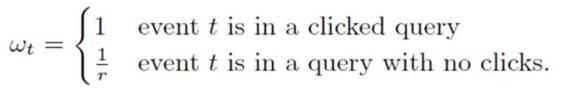
6.subsampling Training Data
1)在实际中,CTR远小于50%,所以正样本更加有价值。通过对训练数据集进行subsampling,可以大大减小训练数据集的大小。
2)正样本全部采(至少有一个广告被点击的query数据),负样本使用一个比例r采样(完全没有广告被点击的query数据)。但是直接在这种采样上进行训练,会导致比较大的biased prediction。
3)解决办法:训练的时候,对样本再乘一个权重。权重直接乘到loss上面,从而梯度也会乘以这个权重。
- 适合场景
- 点击率模型
- 如何选择精排特征?
- 新增特征需保证已有特征索引不变
- 定期离线训练淘汰无用特征,防止特征无线膨胀
- 使用GBDT粗排预测的CTR分段结果作为特征
大数据视频推荐:
网易云课堂
CSDN
人工智能算法竞赛实战
AIops智能运维机器学习算法实战
ELK7 stack开发运维实战
PySpark机器学习从入门到精通
AIOps智能运维实战
腾讯课堂
大数据语音推荐:
ELK7 stack开发运维
企业级大数据技术应用
大数据机器学习案例之推荐系统
自然语言处理
大数据基础
人工智能:深度学习入门到精通
以上是关于142.如何个性化推荐系统设计-2的主要内容,如果未能解决你的问题,请参考以下文章