Java 代码编译和执行的整个过程
Posted chun_soft
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 代码编译和执行的整个过程相关的知识,希望对你有一定的参考价值。
1、JDK/JRE/JVM之间的关系
JVM:Java Virtual Machine(Java虚拟机),包含了Java最核心的类库。
JRE:java runtime environment (java运行环境),包含了JVM和一些常见的Java运行类库,即JRE=JVM+常见运行类库。最大特点:安装了JRE之后,只能运行java程序,但不能开发java程序。因为JRE中没有包含开发者编译Java的相关工具。安装好的JRE文件夹内包含bin和lib两个文件夹,其中bin就是JVM,lib是Java核心类库。
JDK:java development kit (Java 开发工具),包含了JRE和Java开发工具,即JDK=JRE+java开发工具。安装了jdk后,既能运行JAVA程序,又能开发。
参考链接:https://docs.oracle.com/javase/8/docs/index.html
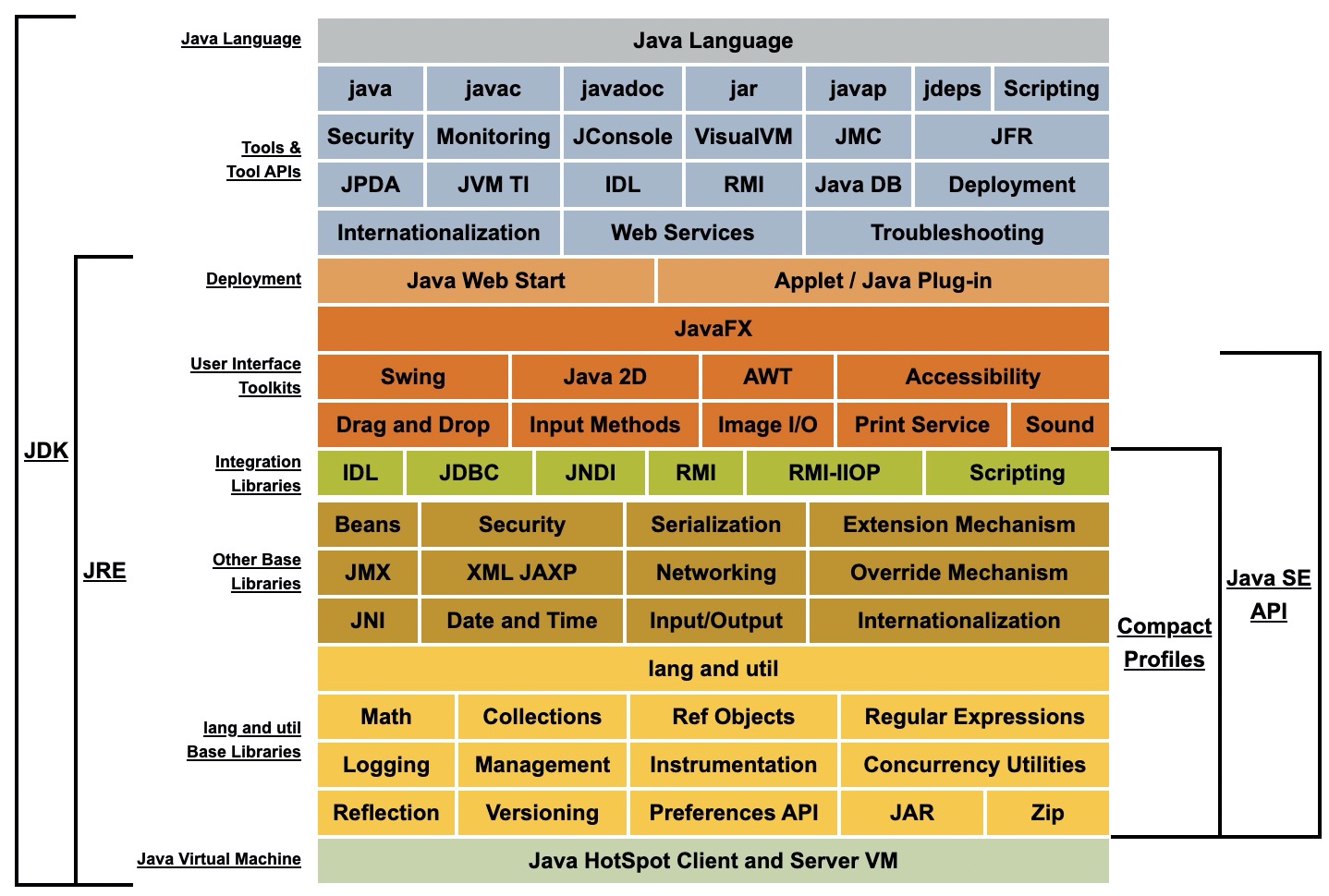
从包含的角度上讲,三者就是JDK包含JRE,JRE包含JVM。
2、源码到类文件
2.1 源码
class Person
private String name;
private int age;
private static String address;
private final static String hobby="Programming";
public void say()
System.out.println("person say...");
public int calc(int op1, int op2)
return op1+op2;
编译命令:javac Person.java ---> Person.class
2.2 编译过程
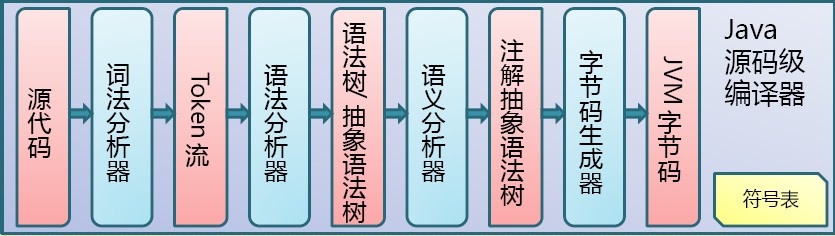
Person.java -> 词法分析器 -> tokens流 -> 语法分析器 -> 语法树/抽象语法树 -> 语义分析器 -> 注解抽象语法树 -> 字节码生成器 -> Person.class文件
Java 源码编译由以下三个过程组成:
(1)分析和输入到符号表;
(2)注解处理;
(3)语义分析和生成 class 文件。
流程图如下所示:

最后生成的 class 文件由以下部分组成:
结构信息:包括 class 文件格式版本号及各部分的数量与大小的信息。
元数据:对应于 Java 源码中声明与常量的信息。包含类/继承的超类/实现的接口的声明信息、域与方法声明信息和常量池。
方法信息:对应 Java 源码中语句和表达式对应的信息。包含字节码、异常处理器表、求值栈与局部变量区大小、求值栈的类型记录、调试符号信息。
2.3 类文件(Class文件)
cafe babe 0000 0034 0027 0a00 0600 1809
0019 001a 0800 1b0a 001c 001d 0700 1e07
001f 0100 046e 616d 6501 0012 4c6a 6176
612f 6c61 6e67 2f53 7472 696e 673b 0100
0361 6765 0100 0149 0100 0761 6464 7265
......
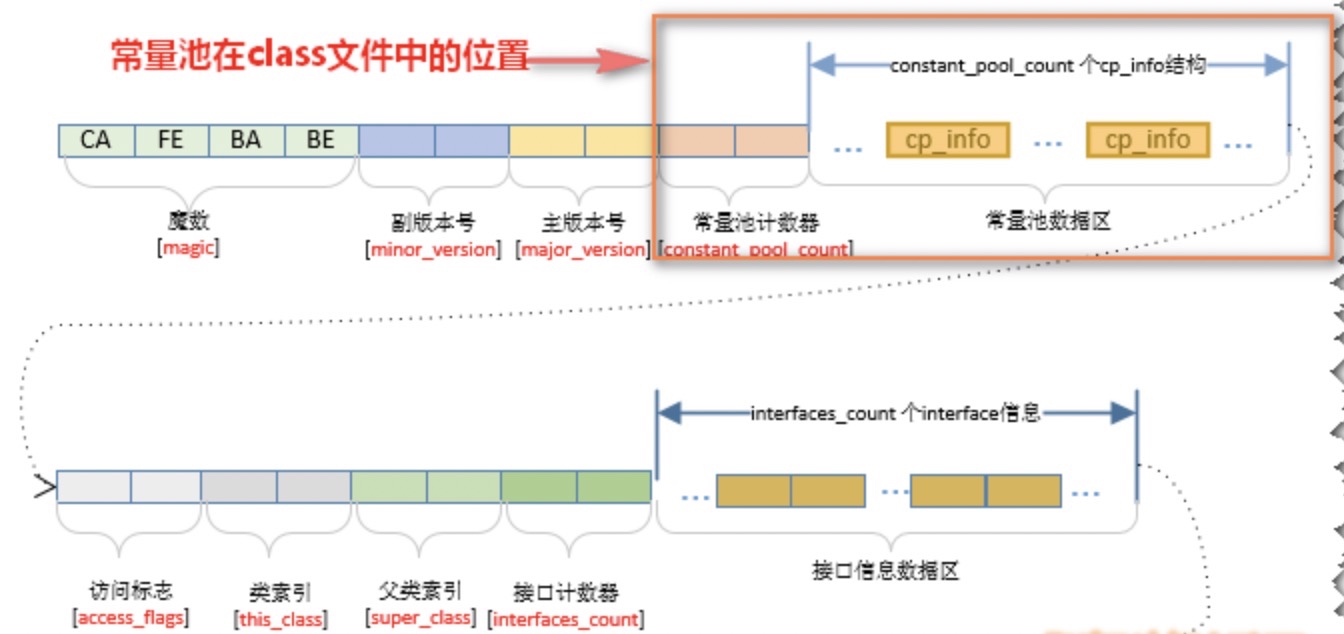
.class字节码文件:
ClassFile
u4 magic; 魔数
u2 minor_version; class文件次版本
u2 major_version; class文件主版本
u2 constant_pool_count; 常量池大小
cp_info constant_pool[constant_pool_count-1]; 常量池信息
u2 access_flags; 访问标志
u2 this_class; 类索引
u2 super_class; 父类索引
u2 interfaces_count; 接口计数器
u2 interfaces[interfaces_count]; 接口信息
u2 fields_count; 字段计数器
field_info fields[fields_count]; 字段信息
u2 methods_count; 方法计算器
method_info methods[methods_count]; 方法信息
u2 attributes_count; 属性计数器
attribute_info attributes[attributes_count]; 属性信息
2.3.1 magic(魔数)
一个文件能否被Java虚拟机接受,不是通过文件的扩展名来进行识别的,而是通过魔数来进行识别.这主要是基于安全方面的考虑,因为文件的扩展名可以随意改动。而且在很多文件存储标准中都使用魔数来进行身份识别,例如图片格式。
每个Class文件的头4个字节称为魔数,它的唯一作用就是确定这个文件是否为一个能被虚拟机接受的Class文件。
Class文件的魔数,值为:cafe babe(咖啡宝贝!)。
2.3.2 minor_version(次版本号), major_version(主版本号)
0000 0034 对应10进制的52,代表JDK 8中的一个版本。
2.3.4 constant_pool_count(常量池计数器)和cp_info(常量池项)
常量池计数器(constant_pool_count),它记录着常量池的组成元素。
0027 对应十进制39,代表常量池中38个常量。
常量池的组织很简单,前端的两个字节占有的位置叫做常量池计数(constant_pool_count),它记录着常量池的组成元素 常量池项(cp_info)的个数。紧接着会排列着constant_pool_count-1个常量池项(cp_info)。如下图所示:

3、类文件到虚拟机
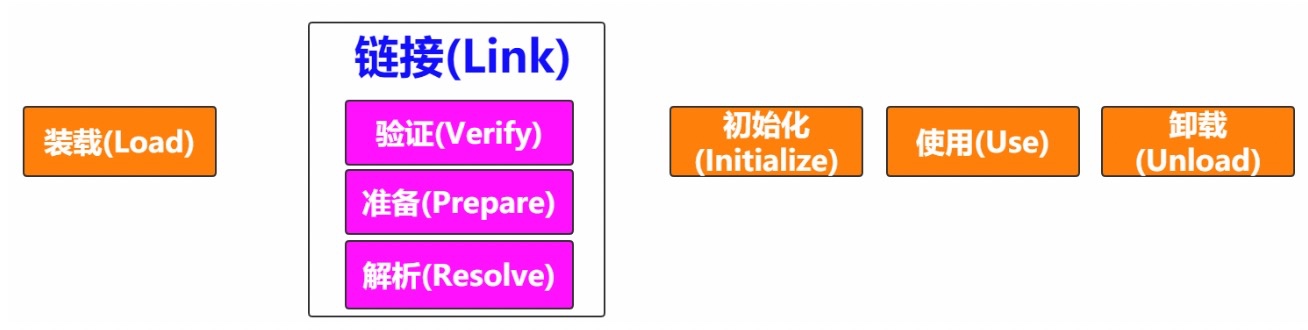
使用和卸载不算是类加载过程中的阶段,只是画完整了一下。
- 类加载的时机
(1)隐式加载 new 创建类的实例;
(2)显式加载:loaderClass,forName等;
(3)访问类的静态变量,或者为静态变量赋值;
(4)调用类的静态方法;
(5)使用反射方式创建某个类或者接口对象的Class对象;
(6)初始化某个类的子类;
(7)直接使用java.exe命令来运行某个主类。
3.1 装载(Load)
查找和导入class文件。ClassLoader通过一个类的完全限定名查找此类字节码文件,并利用字节码文件创建一个class对象。
3.2 链接(Link)
3.2.1 验证(Verify)
目的在于确保class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身的安全,主要包括四种验证:
(1)文件格式验证
(2)元数据验证
(3)字节码验证
(4)符号引用验证
3.2.2 准备(Prepare)
为类变量(static修饰的字段变量)分配内存并且设置该类变量的初始值,(如static int i = 5 这里只是将 i 赋值为0,在初始化的阶段再把 i 赋值为5),这里不包含final修饰的static ,因为final在编译的时候就已经分配了。这里不会为实例变量分配初始化,类变量会分配在方法区中,实例变量会随着对象分配到Java堆中。
3.2.3 解析(Resolve)
将常量池内的符号引用替换为直接引用的过程。
两个重点:
符号引用。即一个字符串,但是这个字符串给出了一些能够唯一性识别一个方法,一个变量,一个类的相关信息。
直接引用。可以理解为一个内存地址,或者一个偏移量。比如类方法,类变量的直接引用是指向方法区的指针;而实例方法,实例变量的直接引用则是从实例的头指针开始算起到这个实例变量位置的偏移量。
举个例子来说,现在调用方法hello(),这个方法的地址是1234567,那么hello就是符号引用,1234567就是直接引用。
在解析阶段,虚拟机会把所有的类名,方法名,字段名这些符号引用替换为具体的内存地址或偏移量,也就是直接引用。
3.3 初始化(Initialize)
对类的静态变量,静态代码块执行初始化操作。这里是类记载的最后阶段,如果该类具有父类就进行对父类进行初始化,执行其静态初始化器(静态代码块)和静态初始化成员变量。(前面已经对static 初始化了默认值,这里我们对它进行赋值,成员变量也将被初始化)
4、类装载器
在装载(Load)阶段,其中第(1)步:通过类的全限定名获取其定义的二进制字节流,需要借助类装载器完成,顾名思义,就是用来装载Class文件的。
(1)通过一个类的全限定名获取定义此类的二进制字节流
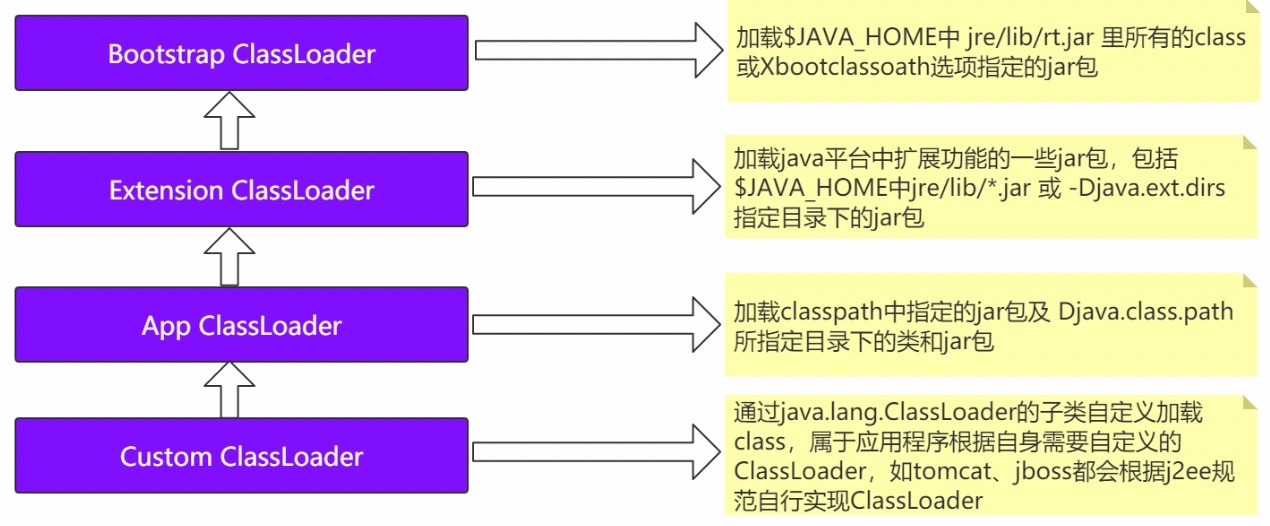
4.1 分类
1)Bootstrap ClassLoader 负责加载$JAVA_HOME中 jre/lib/rt.jar 里所有的class或 Xbootclassoath选项指定的jar包。由C++实现,不是ClassLoader子类。
2)Extension ClassLoader 负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中 jre/lib/*.jar 或 -Djava.ext.dirs指定目录下的jar包。
3)App ClassLoader 负责加载 classpath 中指定的jar包及 Djava.class.path 所指定目录下的类和 jar 包。
4)Custom ClassLoader 通过java.lang.ClassLoader的子类自定义加载class,属于应用程序根据 自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader。
4.2 图解
4.3 加载原则
检查某个类是否已经加载:顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检查,只要某个Classloader已加载,就视为已加载此类,保证此类只所有ClassLoader加载一次。
加载的顺序:加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
- 双亲委派机制:
定义:如果一个类加载器在接到加载类的请求时,它首先不会自己尝试去加载这个类,而是把这个请求任务委托给父类加载器去完成,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
优势:Java类随着加载它的类加载器一起具备了一种带有优先级的层次关系。比如,Java中的 Object类,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型 最顶端的启动类加载器进行加载,因此Object在各种类加载环境中都是同一个类。如果不采用 双亲委派模型,那么由各个类加载器自己取加载的话,那么系统中会存在多种不同的Object 类。
破坏:可以继承ClassLoader类,然后重写其中的loadClass方法,其他方式大家可以自己了解 拓展一下。
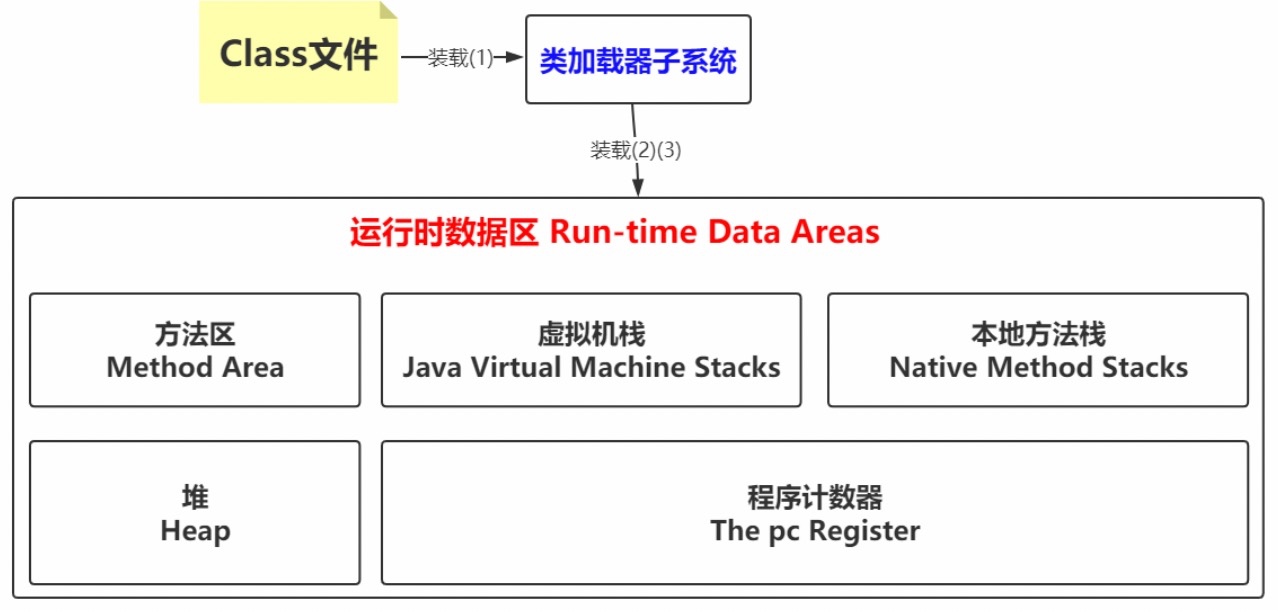
5、运行时数据区(Run-Time Data Areas)
在装载阶段的第(2),(3)步可以发现有运行时数据,堆,方法区等名词
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构;
(3)在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
说白了就是类文件被类装载器装载进来之后,类中的内容(比如变量,常量,方法,对象等这些数 据得要有个去处,也就是要存储起来,存储的位置肯定是在JVM中有对应的空间)
5.1 官方定义
https://docs.oracle.com/javase/specs/jvms/se8/html/index.html
The Java Virtual Machine defines various run-time data areas that are used during execution of a program. Some of these data areas are created on Java Virtual Machine start-up and are destroyed only when the Java Virtual Machine exits. Other data areas are per thread. Per-thread data areas are created when a thread is created and destroyed when the thread exits.
JVM定义了我们执行程序时的运行时数据区。其中一些数据区是在JVM启动的时候创建并在JVM退出的时候才会销毁的。还有一些数据区是每个线程都有的。每个线程都有的数据区(per-thread data areas)在每个线程创建的时候创建并在线程结束的时候销毁.
5.2 图解

5.3 数据区各个区域含义
5.3.1 Method Area(方法区)
方法区是各个线程共享的内存区域,在虚拟机启动时创建。
用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做Non-Heap(非堆),目的是与Java堆区分开来。
当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
此时回看装载阶段的第2步:(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据 结构。如果这时候把从Class文件到装载的第(1)和(2)步合并起来理解的话,可以画个图:

值得说明的:
(1)方法区在JDK 8中就是Metaspace,在JDK6或7中就是Perm Space
(2)Run-Time Constant Pool
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,用于存放编译时期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
5.3.2 Heap(堆)
Java堆是Java虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享。
Java对象实例以及数组都在堆上分配。
此时回看装载阶段的第3步:(3)在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
此时装载(1)(2)(3)的图可以改动一下
5.3.3 Java Virtual Machine Stacks(虚拟机栈)
经过上面的分析,类加载机制的装载过程已经完成,后续的链接,初始化也会相应的生效。
假如目前的阶段是初始化完成了,后续做啥呢?肯定是Use使用咯,那怎样才能被使用到?换句话说里面内容怎样才能被执行?
比如通过主函数main调用其他方法,这种方式实际上是main线程执行之后调用的方法,即要想使用里面的各种内容,得要以线程为单位,执行相应的方法才行。
那一个线程执行的状态如何维护?一个线程可以执行多少个方法?这样的关系怎么维护呢?
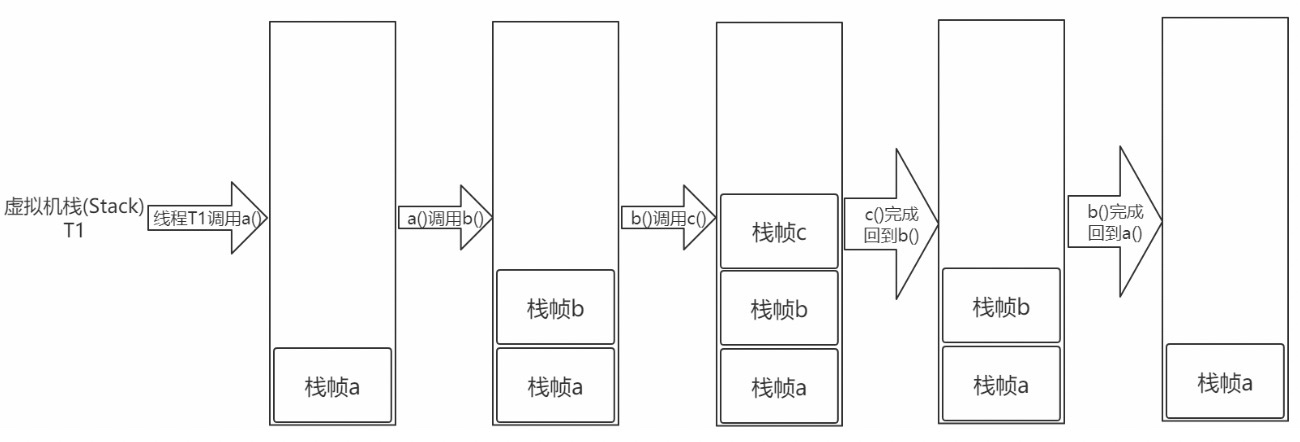
虚拟机栈是一个线程执行的区域,保存着一个线程中方法的调用状态。换句话说,一个Java线程的运行状态,由一个虚拟机栈来保存,所以虚拟机栈肯定是线程私有的,独有的,随着线程的创建而创建。
每一个被线程执行的方法,为该栈中的栈帧,即每个方法对应一个栈帧。调用一个方法,就会向栈中压入一个栈帧;一个方法调用完成,就会把该栈帧从栈中弹出。
画图理解栈和栈帧:
5.3.4 The pc Register(程序计数器)
我们都知道一个JVM进程中有多个线程在执行,而线程中的内容是否能够拥有执行权,是根据 CPU调度来的。
假如线程A正在执行到某个地方,突然失去了CPU的执行权,切换到线程B了,然后当线程A再获 得CPU执行权的时候,怎么能继续执行呢?这就是需要在线程中维护一个变量,记录线程执行到的位置。
程序计数器占用的内存空间很小,由于Java虚拟机的多线程是通过线程轮流切换,并分配处理器执行时间的方式来实现的,在任意时刻,一个处理器只会执行一条线程中的指令。因此,为了线程切换后能够恢复到正确的执行位置,每条线程需要有一个独立的程序计数器(线程私有)。
如果线程正在执行Java方法,则计数器记录的是正在执行的虚拟机字节码指令的地址; 如果正在执行的是Native方法,则这个计数器为空。
5.3.5 Native Method Stacks(本地方法栈)
如果当前线程执行的方法是Native类型的,这些方法就会在本地方法栈中执行。
以上是关于Java 代码编译和执行的整个过程的主要内容,如果未能解决你的问题,请参考以下文章