InnoDB底层存储结构探秘
Posted bruce128
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了InnoDB底层存储结构探秘相关的知识,希望对你有一定的参考价值。
一 innoDB 为什么不用平衡二叉树
计算机存储层次结构
计算机存储设备一般分为两种:内存储器(main memory)和外存储器(external memory)。
内存储器为内存,内存存取速度快,但容量小,价格昂贵,而且不能长期保存数据(在不通电情况下数据会消失)。
外存储器即为磁盘读取,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500GHz的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
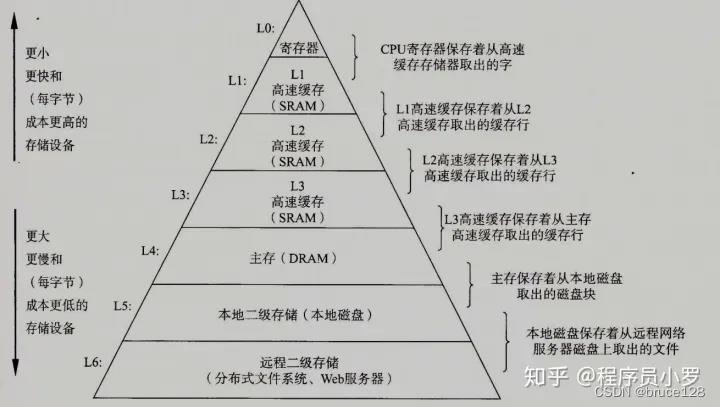
不同介质的访问时间好事,数据来源于google大神Jeff dean
| 存储介质 | 速度 |
|---|---|
| L1 cache reference 读取CPU的一级缓存 | 0.5 ns |
| Branch mispredict(转移、分支预测) | 5 ns |
| L2 cache reference 读取CPU的二级缓存 | 7 ns |
| Mutex lock/unlock 互斥锁\\解锁 | 100 ns |
| Main memory reference 读取内存数据 | 100 ns |
| Compress 1K bytes with Zippy 1k字节压缩 | 10,000 ns |
| Send 2K bytes over 1 Gbps network 在1Gbps的网络上发送2k字节 | 20,000 ns |
| Read 1 MB sequentially from memory 从内存顺序读取1MB | 250,000 ns |
| Round trip within same datacenter 从一个数据中心往返一次,ping一下 | 500,000 ns |
| Disk seek 磁盘搜索 | 10,000,000 ns |
| Read 1 MB sequentially from network从网络上顺序读取1兆的数据 | 10,000,000 ns |
| Read 1 MB sequentially from disk 从磁盘里面读出1MB | 30,000,000 ns |
| Send packet CA->Netherlands->CA 一个包的一次远程访问 | 150,000,000 ns |
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
假定一张表有1023个记录,用平衡二叉树存储高度是10.访问一行数据需要磁盘搜索10个磁盘块。磁盘块随机读取一次是10ms,也就是访问一行需要10个10ms。为了提速,需要尽可能少的访问磁盘块。一个n叉平衡排序树,节点数量N相同的情况下,它的高度是logn(N)。想降低磁盘访问次数,需要增大n。如果是10叉排序树,那么这张表只需要3到4次磁盘随机访问。

本文讲解辅助用表:
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
5亿条记录,表空间20GB的test表只有3层
➜ mysql git:(stable) innodb_space -s ibdata1 -T identity/test -I PRIMARY -l 0 index-level-summary | wc -l
1146555
➜ mysql git:(stable) innodb_space -s ibdata1 -T identity/test -I PRIMARY -l 1 index-level-summary | wc -l
1093
➜ mysql git:(stable) innodb_space -s ibdata1 -T identity/test -I PRIMARY -l 2 index-level-summary
page index level data free records min_key
3 97 2 15288 418 1092 id=1
应用上述公式计算:

1到4层B+树能装填的最大记录数, 数据来源 https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
| Height | Non-leaf pages | Leaf pages | Rows | Size in bytes |
|---|---|---|---|---|
| 1 | 0 | 1 | 468 | 16.0 KiB |
| 2 | 1 | 1203 | > 563 thousand | 18.8 MiB |
| 3 | 1204 | 1447209 | > 677 million | 22.1 GiB |
| 4 | 1448413 | 1740992427 | > 814 billion | 25.9 TiB |
二 B+树数据结构
B+树是一种数据结构,是一个N叉排序树,每个节点通常有多个孩子,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点, 也可能是一个包含两个或两个以上孩子节点的节点。
B+树通常用于数据库和操作系统的文件系统中。NTFS、ReiserFS、NSS、XFS、JFS、ReFS和BFS等文件系统都在使用B+树作为元数据索引。B+树的特点是能够保持数据稳定有序, 其插入与修改拥有较稳定的对数时间复杂度。B+树元素自底向上插入。

B+树的定义
B+树是应文件系统所需而出的一种B-树的变型树。一棵m阶的B+树和m阶的B-树的差异在于:
1) 有n棵子树的节点中含有n个关键字(即每个关键字对应一棵子树);
2) 所有叶子节点中包含了全部关键字的信息, 及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接;
3) 所有的非终端节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
4) 除根节点外,其他所有节点中所含关键字的个数必须>=⌈m/2⌉(注意: B-树是除根以外的所有非终端节点至少有⌈m/2⌉棵子树)
上图是所示为一棵3阶的B+树,通常在B+树上有两个指针头, 一个指向根节点,另一个指向关键字最小的叶子节点。因此,可以对B+树进行两种查找运算: 一种是从最小关键字起顺序查找,另一种是从根节点开始,进行随机查找。
innodb_space -s ibdata1 -T identity/identity_app_token -I PRIMARY -l 0 index-level-summary | wc -l
innodb_space -s ibdata1 -T identity/test -I PRIMARY -l 2 index-level-summary
三 Page结构
页是InnoDB存储引擎磁盘管理的最小单位,每个页默认16KB;磁盘读取的最小单位,即使只需要读一行记录,也需要载入一个page的数据。基本页结构概览:
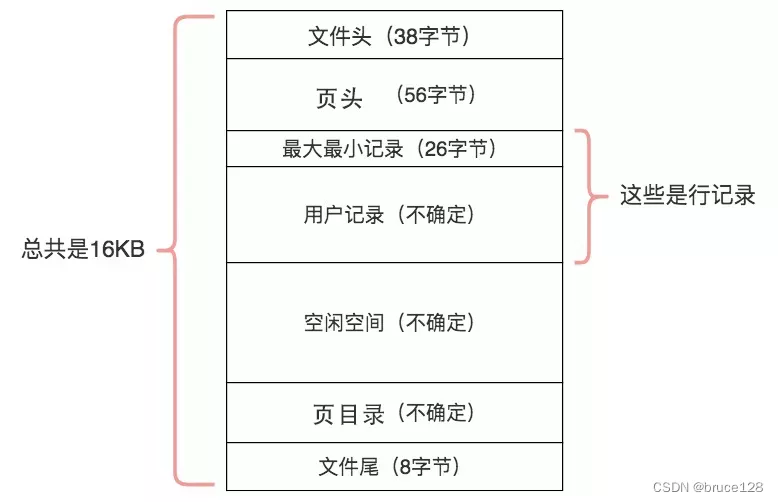
文件头数据结构:

根据页号可以算出一张表最大可以占用多大的物理空间。前驱指针和后继指针让同一个层级的Page构成一个双向链表,让范围查找变成可能。
用户记录数据结构:

所有的记录已单链表的逻辑结构存储。
页目录:用户记录(User Records)链表的辅助指针数组。每4-8个连续记录一组,页目录里的Slot(槽)指向这一组的最后一个记录的偏移地址。
空间换时间,让二分查找在单链表上变为可能:
innodb_space -s ibdata1 -T identity/identity_app_token -p 3 page-records
innodb_space -s ibdata1 -T identity/identity_app_token -p 3 page-dump | more
innodb_space -s ibdata1 -T identity/identity_app_token -p 3 page-illustrate

一个简单SQL的查找过程
select *
from identity_app_token
where id = 787123
四 聚集索引 & 二级索引
在MySQL中,创建一张表时会默认为主键创建聚簇索引,B+树将表中所有的数据组织起来,即数据就是索引主键所以在InnoDB里,主键索引也被称为聚簇索引,索引的叶子节点存的是整行数据。而除了聚簇索引以外的所有索引都称为二级索引,二级索引的叶子节点内容是主键的值。
-
聚集(一级索引)
- 聚集索引根据数据行的键值在表或视图中排序和存储这些数据行。 索引定义中包含聚集索引列。 每个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
- 只有当表包含聚集索引时,表中的数据行才按排序顺序存储。 如果表具有聚集索引,则该表称为聚集表。 如果表没有聚集索引,则其数据行存储在一个称为堆的无序结构中。
-
非聚集(也称二级索引)
- 非聚集索引具有独立于数据行的结构。 非聚集索引包含非聚集索引键值,并且每个键值项都有指向包含该键值的数据行的指针。
- 除了主键索引以外的索引都是非聚集索引
B+Tree的叶子节点存放主键索引值和行记录就属于聚簇索引;如果索引值和行记录分开存放就属于非聚簇索引。

| id(Primary key) 聚集索引 | Name (key)非聚集索引 | Companay |
|---|---|---|
| 5 | Gates | Microsoft |
| 7 | Bezos | Amazon |
| 11 | Jobs | Apple |
| 14 | Ellison | Oracle |
二级索引的查找过程:二级索引满足查询需求,则直接返回,即为覆盖索引,反之则需要回表去主键索引(聚簇索引)查询
参考资料
- https://blog.jcole.us/innodb/ mysql公司第14号员工的innodb系列博客
- https://github.com/jeremycole/innodb_ruby innodb底层存储分析工具
- 《高性能mysql》
- MySQL技术内幕:InnoDB存储引擎(第2版)
以上是关于InnoDB底层存储结构探秘的主要内容,如果未能解决你的问题,请参考以下文章