简易爬虫实现校园网剩余流量查询
Posted zero9988
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简易爬虫实现校园网剩余流量查询相关的知识,希望对你有一定的参考价值。
学校公众号要用爬虫查询校园网流量,记录一下实现这个简易爬虫的过程。
开发工具:
Eclipse,Chrome/Firefox
第三方库”:
jsoup:用来解析网页数据,用法传送门:http://www.open-open.com/jsoup/,HttpClient用来连接web页面,模拟get和post请求
Step 1:明确目标
简单的理解爬虫的过程就是模拟网页操作的过程,GET网页数据,POST数据请求的模拟。
So,第一部先明确查询校园网流量的步骤:
1:确认目标网页:http://zyzfw.xidian.edu.cn/ 我们查询校园网流量用户登录界面
2:输入 学号,密码,验证码,作为post的数据,然后点击登录
3:登录后转向页面地址:http://zyzfw.xidian.edu.cn/home/base/index 流量信息查询页面
4:记录所查看到的流量信息

Step 2:java编程
java文件列表
HttpClientManager.java: 获取一个HttpClient的单例,通过这个单例来连接网站
HttpOperate.java: HttpClient相关网络请求的函数
1,获取网页cookies信息与验证码的GET方法;
2,账户登录POST请求方法;
3,获取登录后网页中流量信息的get方法。
DocHandle.java : 对通过jsoup库获得到的网页的html源码的document类进行分析处理获取网页内容并保存
1,获取网页错误信息方法,
2,获取流量信息方法,
3,获取令牌token方法,
4,验证码获取分析方法
ImageOP.java 根据url和cookies下载验证码图片
NetConstans.java 网址等常量
PictureOperate.java 对下载来的验证码图片进行操作
1,读取图片方法(返回int[][]二维数组);
2,裁剪图片方法(使得验证码图片的4个数字变成4张图片可以单独处理);
3,保存图片方法
4,简单的识别图片数字方法
UserInfo.java 用户信息的保存
1,用户基本信息
2,cookies信息
3,图片路径信息
4,令牌信息
5,流量信息
6,错误信息
MainRunning.java 主程序
MainRunning.java
public class MainRunning
public static void main(String[] args)
// TODO Auto-generated method stub
HttpClientManager.init();
UserInfo user = new UserInfo("0000000001","000000001");
if(user.getUserName().equals(""))
System.out.println("输入用户名");
//login
boolean loginOk=false;
int cc=0;
do
cc++;
if(cc>5)
System.out.println("login error!tyr late.");
break;
if(HttpOperate.getLoginInfo(user))
loginOk=HttpOperate.loginFlowQuery(user);
if(!loginOk&&!user.codeError.equals(""))
System.out.println(user.userError);
break;
else
System.out.println("getLoginInfo error!!");
break;
while(!loginOk);
if(loginOk&&HttpOperate.getFlowInfo(user))
user.printFlowInfo();
else
System.out.println("get FlowInfo error!");
</span>从Main方法中可以发现,逻辑十分的简单:
1,初始化:
HttpClientManager.init();UserInfo user = new UserInfo("0000000001","000000001");初始化用户的账号和密码
2,账户登录:
do……while(……)尝试5次登录(原谅我的验证码识别函数有点low),如果5次都没有登录成功,提示用户稍后再试。
HttpOperate.getLoginInfo(user)获取网页cookies信息与验证码,模拟用户在地址栏输入了目标网页:http://zyzfw.xidian.edu.cn/ 的GET请求,然后获取目标网站的内容,主要是要获取cookies,token令牌(稍后说明),验证码图片
loginOk=HttpOperate.loginFlowQuery(user);
3,登录成功,查询登录界面的流量信息
HttpOperate.getFlowInfo(user)
三个步骤的详细说明:
1,初始化
HttpClientManager.java的代码
public class HttpClientManager
private static HttpClient httpClient = null;
private HttpClientManager()
public static void init()
httpClient = null;
if(httpClient == null)
synchronized (HttpClientManager.class)
if (httpClient == null)
httpClient = HttpClients.createDefault();
public static HttpClient getInstance()
return httpClient;
UserInfo.java中的UesrInfo类没什么好说明的,就是简单各种成员属性,用来保存网页中获得的数据。
2,账户登录
2-1:获取网页cookies信息与验证码,模拟用户在地址栏输入了目标网页:http://zyzfw.xidian.edu.cn/ 的GET请求,然后获取目标网站的内容,主要是要获取cookies,token令牌(稍后说明),验证码图片
先通过Chrome浏览器来看一看,浏览器浏览(GET)网页内容是如何发送请求的。
打开Chrome浏览器,按F12打开 开发者工具,选择NETWORK(可以查看所有来往的网络数据包,里面包含了请求信息和网页的所有信息),可以看到来自地址http://zyzfw.xidian.edu.cn/的数据包,点击选择headers,查看http头文件
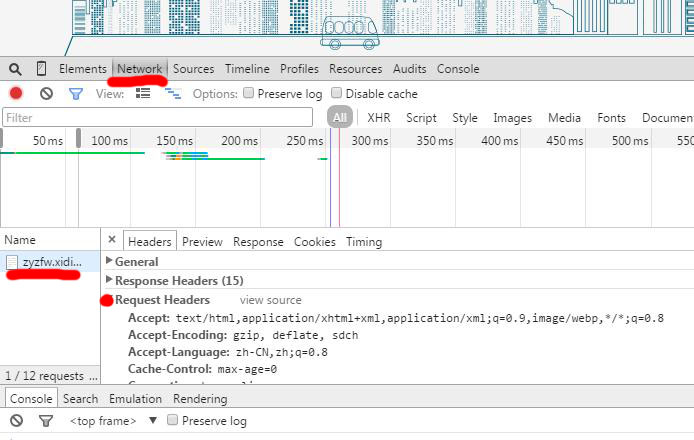
可以看到Requst Headers 就是为了打开一个web页面,向目标地址服务器发送的请求的头信息。可以看到头信息里有一些设置。
再点开Response Headers,

这个就是向服务器发送GET请求,服务器发送给一个response,Response主要包含两个部分,一个是ResponseHeaders(http头信息)和ResponseEntity(就是看到的网站页面的html源码)
然后看HttpOperate.getLoginInfo(user)方法如下:
HttpOperate.getLoginInfo(user)在HttpOperate.java中
public static boolean getLoginInfo(UserInfo user)
HttpGet httpGet = new HttpGet(NetConstans.LOGIN_URL);
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:39.0) Gecko/20100101 Firefox/39.0");
httpGet.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
httpGet.setHeader("Accept-Language", "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3");
httpGet.setHeader("Accept-Encoding", "gzip, deflate");
httpGet.setHeader("Connection", "keep-alive");
httpGet.setHeader("Host","zyzfw.xidian.edu.cn");
httpGet.setHeader("Cache-Control","max-age=0");
httpGet.setHeader("Referer","http://pay.xidian.edu.cn/");
try
HttpResponse response = HttpClientManager.getInstance().execute(httpGet);
Header[] headers = response.getHeaders("Set-Cookie");
StringBuilder sb=new StringBuilder();
for(int i=0;i<headers.length;i++)
sb.append(headers[i].toString());
user.setCookiesString(sb.toString());
//System.out.println(user.getCookiesString());
//System.out.println(user.getUserCookies().toString());
String loginWebStr = EntityUtils.toString(response.getEntity());
Document document = Jsoup.parse(loginWebStr);
DocHandle.getCsrfToken(document, user);
DocHandle.getVerifyCode(document, user);
return true;
catch (IOException e)
e.printStackTrace();
return false;
设置完信息后,通过获取HttpClient的实例,执行GET请求操作: HttpResponse response = HttpClientManager.getInstance().execute(httpGet);
然后这个执行结果返回值就是我们的Response了:
1,先获取Response的headers部分,主要是要获取headers中的Set-Cookie中的内容,之前可以看到有3个set-cookie项,所以循环处理一下并分别保存一下这3个cookie(不一定会用到,因为你之后的操作已经默认你保存这些Cookies)
2,在获取Response的Entity部分,即网页内容。先把html内容保存成字符串的形式,然后通过Jsoup.parse(String)方法把html字符串转换成可以识别的Document的形式。
然后我们主要获取这个html页面中的两样信息:验证码 和token令牌(其实我也不知道为什么我要叫这个是令牌。。总好像有点什么印象。。)
1,token令牌,DocHandle.getCsrfToken(document, user);在文件DocHandle.java中
public static void getCsrfToken(Document document,UserInfo user)
Elements es=document.select("meta");
for (Element element : es)
if(element.attr("name").equals("csrf-token"))
user.setCsrf_token(element.attr("content"));
return;
System.out.print("token error");
这个token令牌是等会POST提交表单数据时要用到的。刚开始,我发现提交POST时有一个_csrf参数,我一直不知道这个参数的数值是哪里来。。。。所以一直无法成功提交post请求,因此我查看了一下http://zyzfw.xidian.edu.cn/的html的源代码,我看到了html源代码中<head>标签中有一个name="csrf-token"的标签。因此,我们需要获取这个标签的内容。
<metaname="csrf-token"content="YUt1dfdtgno4KDcyaRUHDhczTRBaIzIDFikXT0woDhEVAx0xXjAKDw==">
Document的select方法选择所有的meta标签,然后遍历这个标签数组,去meta标签的name属性,当这个meta的name属性是"csrf-tosen"时,获取content属性中的内容 保存到user中,即获得了这个token令牌。
Document的操作都是Jsoup中的内容,很简单的一些操作 ,传送门:http://www.open-open.com/jsoup/
2,验证码
DocHandle.getVerifyCode(document, user);在文件DocHandle.java中
public static void getVerifyCode(Document document,UserInfo user)
Element eee = document.getElementById(NetConstans.VERIFYCODEID);
String url = NetConstans.LOGIN_URL+eee.attr("src");
user.imagePath=eee.attr("src").split("=")[1];
user.imagePath=user.imagePath;
//System.out.println(url);
ImageOP.downloadImageByURL(url,user);
int[][] data=PictureOperate.readPic2IntArray(user.imagePath+".png");
//File f1 = new File(user.imagePath+".png");
//if(f1.exists())
//f1.deleteOnExit();
String newPath2=user.imagePath+"-";
PictureOperate.cutPicture(data,newPath2);
StringBuilder sb=new StringBuilder();
for(int i=0;i<4;i++)
String newPath3=user.imagePath+"-"
+Integer.toString(i+1)+".png";
data = PictureOperate.readPic2IntArray(newPath3);
float[] f=PictureOperate.changeDataToInt9(data);
double res;
double minRes=9999;
int val=-1;
//0..9 = 10numbers
for(int j =0;j<10;j++)
res=0;
//9 blocks
for(int k =0;k<9;k++)
res=res+Math.abs(f[k]-PictureOperate.training[j][k]);
if(res<minRes)
minRes=res;
val=j;
sb.append(Integer.toString(val));
//String s=HttpOperate.recognizeCodeByORCKingWebsite(url);
user.setCode(sb.toString());
System.out.println(sb.toString());
for(int i=1;i<=4;i++)
File ff=new File(user.imagePath+"-"+Integer.toString(i)+".png");
ff.delete();
File fx = new File(user.imagePath+".png");
if(fx.exists())
if(!fx.delete())
System.gc();
fx.delete();
File fx = new File(user.imagePath+".png");
if(fx.exists())
if(!fx.delete())
System.gc();
fx.delete();
这段代码,是由于奇怪的占用导致文件打开了无法顺利删除,保证能删除掉这个图片。
先是根据验证码图片的<img>标签的特定的id号NetConstans.VERIFYCODEID="loginform-verifycode-image"来得到这个标签,然后获取这个img的对应src地址,然后根据这个地址调用downloadImageByURL方法下载这个验证码图片。
验证码下载到本地以后是一张图片的形式,接下来就开始
门外汉的图像识别验证码数字
简单说一下处理思路,
1,训练样本------这个操作是提前完成的,只要做一次就够了,以后不用做了
1-1,获取足够多验证码图片,一直刷新目标网页,并每次保存验证码图片

1-2,分割图片,把每张图片变成4个单独的数字图片,(这里有个难的地方在于很多数字是粘连在一起的。。不好分割。。反正我的分割思路很low。。)

1-3,然后按0-9每个数字单独分类,每种数字有足够多的样本
1-4,接着就是样本分析了。。提取0123456789他们分别的特征,我是把每张图片分成九宫格,找出九宫格每一格中黑点占全部黑点的百分作为一个数字的特征。
1-5,把训练得到的结果保存成一个数组9(格)*10(类)的数组
2:把下载来的验证码也划分成4个单独数字,然后进行比较,看数字最就近哪个样本特征,就是哪个数字。最后把数字连起来就得到了验证码了。。。。。。。。。。
ImageOP.downloadImageByURL(url,user);在文件ImageOP.java中
public static void downloadImageByURL(String s,UserInfo user)
URL url;
try
url = new URL(s);
//HttpURLConnection uc= (HttpURLConnection)url.openConnection();
URLConnection uc = url.openConnection();
uc.setRequestProperty("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
uc.setRequestProperty("accept", "*/*");
uc.setRequestProperty("connection", "Keep-Alive");
uc.setRequestProperty("user-agent","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)");
uc.setRequestProperty("Cookie",user.getUserCookies().toString());
uc.connect();
File file = new File(user.imagePath+".png");
FileOutputStream out = new FileOutputStream(file);
int i=0;
InputStream is = uc.getInputStream();
while ((i=is.read())!=-1)
out.write(i);
is.close();
catch (MalformedURLException e)
// TODO Auto-generated catch block
e.printStackTrace();
catch (IOException e)
// TODO Auto-generated catch block
e.printStackTrace();
2-2:根据用户名,密码,验证码,token令牌 进行登录,即模拟一次post请求
同样先看看点击 登录 时 Chrome浏览器和网站服务器之间传送的数据包
同样的方式,可以看到来自目标网站的数据包我们先看看Request Headers和Response Headers
Request Headers
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:max-age=0
Connection:keep-alive
Content-Length:180
Content-Type:application/x-www-form-urlencoded
Cookie:safedog-flow-item=C864AD7C523216AFDE4807601B; lzstat_uv=118312236|3401870; phpSESSID=21sa2hufe124312aswrwqhghvcxc3; _csrf=f4559712aba7b9sadasda5d7655fcf96ede5b1df95febc673124452ca%3A2%3A%7Bi%3A0%3Bs%3A5%3A%22_csrf%22%3Bi%3A1%3Bs%3A32%3A%22YcBDPpAtvx8fcFtywbb9uMHktHhGgULu%22%3B%7D; BIGipServerzyzfw.xidian.edu.cn=13412690.24610.0000
Host:zyzfw.xidian.edu.cn
Origin:http://zyzfw.xidian.edu.cn
Referer:http://zyzfw.xidian.edu.cn/
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36
Response Headers
Cache-Control:no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Connection:Keep-Alive
Content-Length:0
Content-Type:text/html; charset=UTF-8
Date:Fri, 29 Apr 2016 12:47:32 GMT
Expires:Thu, 19 Nov 1981 08:52:00 GMT
Keep-Alive:timeout=1, max=250
Location:http://zyzfw.xidian.edu.cn/home/base/index
Pragma:no-cache
Server:Apache/2.4.12 (Unix) OpenSSL/1.0.1g-fips PHP/5.5.23
Set-Cookie:PHPSESSID=a3c2f1p3rnf94ktcvfgi0vrvs4; path=/; HttpOnly
X-Powered-By:PHP/5.5.23Location:http://zyzfw.xidian.edu.cn/home/base/index代表了登录成功后转向的地址。即流量信息查看的地址。
除了Resquest和Response,我们继续往下拉,我们发现Form Data 这就是POST请求时,所需要的传递的参数,
我们发现除了用户名,密码,和验证码,还有一个关键的_csrf参数,因此就有了之前的获取这个参数需求
Form Data
_csrf:U3NMOVJpWFcKEA59AhkZIyULdF8xLywuJBEuACckEDwnOyR.NTwUIg==
LoginForm[username]:00000001
LoginForm[password]:00000001
LoginForm[verifyCode]:7567
login-button:
public static boolean loginFlowQuery(UserInfo user)
HttpPost httpPost = new HttpPost(NetConstans.LOGIN_URL);
httpPost.setHeader("Host", "zyzfw.xidian.edu.cn");
httpPost.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0");
httpPost.setHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
httpPost.setHeader("Accept-Language", "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3");
httpPost.setHeader("Accept-Encoding", "gzip, deflate");
httpPost.setHeader("Referer", "http://zyzfw.xidian.edu.cn/");
httpPost.setHeader("Origin", "http://zyzfw.xidian.edu.cn");
httpPost.setHeader("Connection", "keep-alive");
// set param
List<BasicNameValuePair> formparams = new ArrayList<BasicNameValuePair>();
formparams.add(new BasicNameValuePair("_csrf", user.getCsrf_token()));
formparams.add(new BasicNameValuePair("LoginForm[username]", user.getUserName()));
formparams.add(new BasicNameValuePair("LoginForm[password]", user.getPassword()));
formparams.add(new BasicNameValuePair("LoginForm[verifyCode]", user.getCode()));
formparams.add(new BasicNameValuePair("login-button", ""));
UrlEncodedFormEntity encodedFormEntity = new UrlEncodedFormEntity(formparams, Consts.UTF_8);
httpPost.setEntity(encodedFormEntity);
//System.out.println("Bfore Login");
HttpResponse response = null;
try
response = HttpClientManager.getInstance().execute(httpPost);
if(response == null)
System.out.println("null");
return false;
String loginWebStr = EntityUtils.toString(response.getEntity());
//System.out.println(loginWebStr);
if(loginWebStr.equals("")||loginWebStr==null)
return true;//无返回值代表登陆成功
else
Document document = Jsoup.parse(loginWebStr);
DocHandle.getErrorInfo(document, user);
return false;//有返回值代表出错,查看错误信息
catch (IOException e)
e.printStackTrace();
return false;
3:登录成功后,就是在转向后的网址内容GET网页内容,通过jsoup获取内容,保存在user中即可。
Form Data
_csrf:U3NMOVJpWFcKEA59AhkZIyULdF8xLywuJBEuACckEDwnOyR.NTwUIg==
LoginForm[username]:00000001
LoginForm[password]:00000001
LoginForm[verifyCode]:7567
login-button:以上是关于简易爬虫实现校园网剩余流量查询的主要内容,如果未能解决你的问题,请参考以下文章