Excel每一列导出为HTML文件?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Excel每一列导出为HTML文件?相关的知识,希望对你有一定的参考价值。
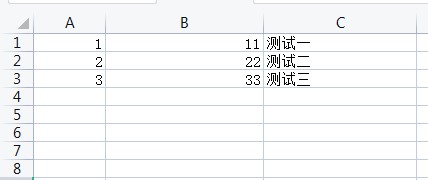
例如我有表格<测试.xls>需要将每一行的C列导出为html文件,文件名为A列导出的结果为1.html 内容为测试一2.html 内容为测试一3.html 内容为测试一
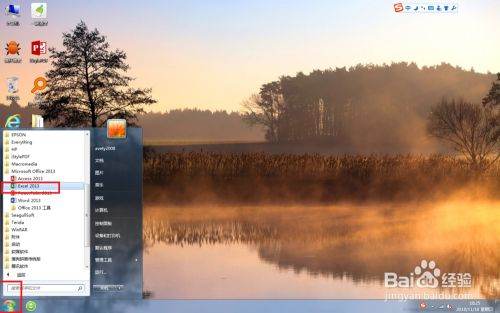
点击任务栏上的【开始】-【新建excel 2013文档】,在弹出的信息中,选择空白工作簿,如图。
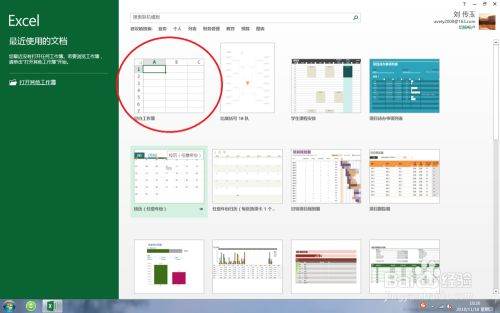
请点击输入图片描述
请点击输入图片描述
在单元格中输入内容,用于演示,如图。
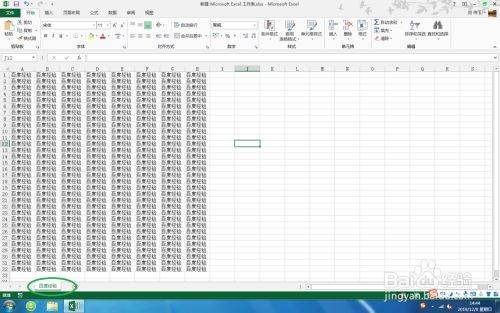
请点击输入图片描述
点击左上角的【文件】图标,如图。
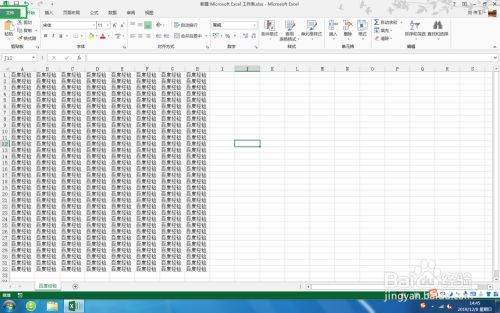
请点击输入图片描述
在【文件】列表中,选择【另存为】-【计算机】-【浏览】,如图。
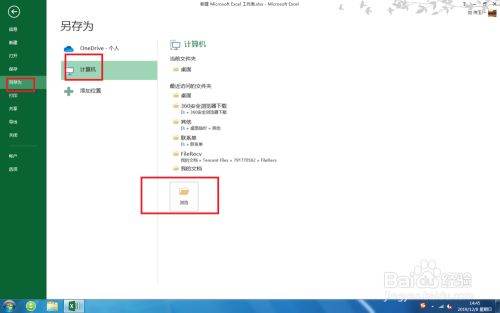
请点击输入图片描述
选择合适的位置,在保存列表中,选择【html】文件,点击【保存】,如图。
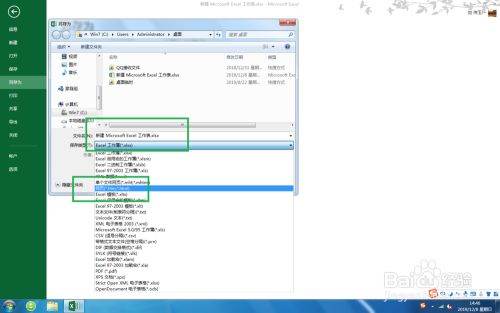
请点击输入图片描述
打开保存的html文件进行查看,如图。
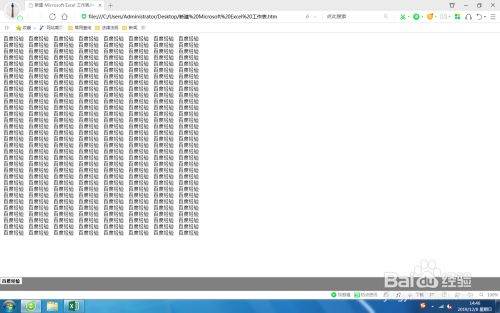
请点击输入图片描述
Python脚本——excel文件按列导出
将一个excel文件每一列的内容分别导出到一个txt文件中,txt文件名为excel的列名。
1 #!/usr/bin/python 2 # -*- coding: UTF-8 -*- 3 import xlrd #导入xlrd模块 4 5 6 def is_number(s): #判断是否为数字 7 try: 8 float(s) 9 return True #是数字返回True 10 except ValueError: 11 pass 12 13 def main(): 14 workbook = xlrd.open_workbook(excel_path) #打开xlsx文件 15 sheet = workbook.sheet_by_index(0) 16 ncols = sheet.ncols #获取工作表列数 17 for i in range(0,ncols): 18 l1 = sheet.col_values(i) #将每一列数据存放在列表中 19 name = sheet.cell(0,i).value #获取列名 20 if is_number(name) == True: #判断name是否为数字 21 txt = open(txt_path + str(name) + ‘.txt‘,‘w‘) #新建文本文件 22 else: 23 txt = open(txt_path + name + ‘.txt‘,‘w‘) 24 while ‘‘ in l1: #列表元素去空 25 l1.remove(‘‘) 26 l2 = l1[1:] #从第二个元素开始截取列表 27 new_list = list(set(l2)) #用集合过滤重复元素 28 new_list.sort(key = l2.index) #将新列表元素按原列表元素排序 29 for q in new_list: #将列表中的元素写入文本文件中 30 if is_number(q) == True: #判断列表中元素是否为数字 31 txt.write(str(q) + ‘\n‘) 32 else: 33 txt.write(q.encode(‘utf-8‘) + ‘\n‘) 34 txt.close() #关闭文本文件 35 if __name__ ==‘__main__‘: 36 excel_path = raw_input (unicode(‘请输入excel文件路径:‘,‘utf-8‘).encode(‘gbk‘)) #输入excel文件路径 37 txt_path = raw_input (unicode(‘请输入txt文件保存路径:‘,‘utf-8‘).encode(‘gbk‘)) #输入txt文件保存目录 38 main()
以上是关于Excel每一列导出为HTML文件?的主要内容,如果未能解决你的问题,请参考以下文章