POJ 3261 Milk Patterns(后缀数组[可重叠的k次最长重复子串])
Posted queuelovestack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了POJ 3261 Milk Patterns(后缀数组[可重叠的k次最长重复子串])相关的知识,希望对你有一定的参考价值。
此文章可以使用目录功能哟↑(点击上方[+])
 POJ 3261 Milk Patterns
POJ 3261 Milk Patterns
Accept: 0 Submit: 0
Time Limit: 5000 MS Memory Limit : 65536 K
 Problem Description
Problem Description
Farmer John has noticed that the quality of milk given by his cows varies from day to day. On further investigation, he discovered that although he can't predict the quality of milk from one day to the next, there are some regular patterns in the daily milk quality.
To perform a rigorous study, he has invented a complex classification scheme by which each milk sample is recorded as an integer between 0 and 1,000,000 inclusive, and has recorded data from a single cow over N (1 ≤ N ≤ 20,000) days. He wishes to find the longest pattern of samples which repeats identically at least K (2 ≤ K ≤ N) times. This may include overlapping patterns -- 1 2 3 2 3 2 3 1 repeats 2 3 2 3 twice, for example.
Help Farmer John by finding the longest repeating subsequence in the sequence of samples. It is guaranteed that at least one subsequence is repeated at least K times.
Input
Line 1: Two space-separated integers: N and K
Lines 2..N+1: N integers, one per line, the quality of the milk on day i appears on the ith line.
Output
Line 1: One integer, the length of the longest pattern which occurs at least K times
Sample Input
8 2
1
2
3
2
3
2
3
1
Sample Output
4
Problem Idea
解题思路:
【题意】
给你一个长度为N的序列,以及一个整数k
问序列中可重叠的k次最长重复子串为多少
例如
8 2
1 2 3 2 3 2 3 1
可重叠的k次最长重复子串为2 3 2 3,故长度为4
【类型】
后缀数组[可重叠的k次最长重复子串]
【分析】
此题是一道裸的后缀数组题
"可重叠的k次最长重复子串"解法(摘自罗穗骞的国家集训队论文):
先二分答案(即二分[可重叠的k次最长重复子串的]长度),把题目变成判定性问题,然后将后缀分成若干组。其中每组的后缀之间的height值都不小于mid。例如,字符串为“ aabaaaab”,当mid=2时,后缀分成了4组,如图所示。
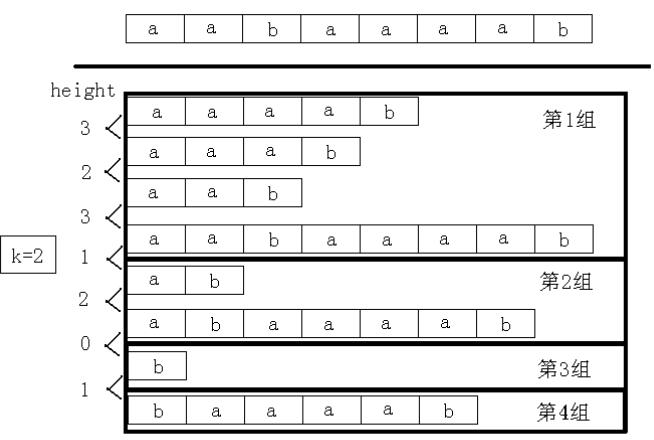
判断有没有一个组的后缀个数不小于k。如果有,那么存在k个相同的子串满足条件,否则不存在。这个做法的时间复杂度为O(nlogn)。
ps:只要有一个组里存在k个后缀,就说明当前二分情况有解
【时间复杂度&&优化】
O(nlogn)
Source Code
/*Sherlock and Watson and Adler*/
#pragma comment(linker, "/STACK:1024000000,1024000000")
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<queue>
#include<stack>
#include<math.h>
#include<vector>
#include<map>
#include<set>
#include<bitset>
#include<cmath>
#include<complex>
#include<string>
#include<algorithm>
#include<iostream>
#define eps 1e-9
#define LL long long
#define PI acos(-1.0)
#define bitnum(a) __builtin_popcount(a)
using namespace std;
const int N = 10;
const int M = 100005;
const int inf = 1000000007;
const int mod = 1000000007;
const int MAXN = 100010;
//rnk从0开始
//sa从1开始,因为最后一个字符(最小的)排在第0位
//height从1开始,因为表示的是sa[i - 1]和sa[i]
//倍增算法 O(nlogn)
int wa[MAXN], wb[MAXN], wv[MAXN], ws_[MAXN];
//Suffix函数的参数m代表字符串中字符的取值范围,是基数排序的一个参数,如果原序列都是字母可以直接取128,如果原序列本身都是整数的话,则m可以取比最大的整数大1的值
//待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n
//为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小
//同上,为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0
//函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]
void Suffix(int *r, int *sa, int n, int m)
int i, j, k, *x = wa, *y = wb, *t;
//对长度为1的字符串排序
//一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序
//如果r的最大值很大,那么把这段代码改成快速排序
for(i = 0; i < m; ++i) ws_[i] = 0;
for(i = 0; i < n; ++i) ws_[x[i] = r[i]]++;//统计字符的个数
for(i = 1; i < m; ++i) ws_[i] += ws_[i - 1];//统计不大于字符i的字符个数
for(i = n - 1; i >= 0; --i) sa[--ws_[x[i]]] = i;//计算字符排名
//基数排序
//x数组保存的值相当于是rank值
for(j = 1, k = 1; k < n; j *= 2, m = k)
//j是当前字符串的长度,数组y保存的是对第二关键字排序的结果
//第二关键字排序
for(k = 0, i = n - j; i < n; ++i) y[k++] = i;//第二关键字为0的排在前面
for(i = 0; i < n; ++i) if(sa[i] >= j) y[k++] = sa[i] - j;//长度为j的子串sa[i]应该是长度为2 * j的子串sa[i] - j的后缀(第二关键字),对所有的长度为2 * j的子串根据第二关键字来排序
for(i = 0; i < n; ++i) wv[i] = x[y[i]];//提取第一关键字
//按第一关键字排序 (原理同对长度为1的字符串排序)
for(i = 0; i < m; ++i) ws_[i] = 0;
for(i = 0; i < n; ++i) ws_[wv[i]]++;
for(i = 1; i < m; ++i) ws_[i] += ws_[i - 1];
for(i = n - 1; i >= 0; --i) sa[--ws_[wv[i]]] = y[i];//按第一关键字,计算出了长度为2 * j的子串排名情况
//此时数组x是长度为j的子串的排名情况,数组y仍是根据第二关键字排序后的结果
//计算长度为2 * j的子串的排名情况,保存到数组x
t = x;
x = y;
y = t;
for(x[sa[0]] = 0, i = k = 1; i < n; ++i)
x[sa[i]] = (y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + j] == y[sa[i] + j]) ? k - 1 : k++;
//若长度为2 * j的子串sa[i]与sa[i - 1]完全相同,则他们有相同的排名
int Rank[MAXN], height[MAXN], sa[MAXN], r[MAXN];
void calheight(int *r,int *sa,int n)
int i,j,k=0;
for(i=1; i<=n; i++)Rank[sa[i]]=i;
for(i=0; i<n; height[Rank[i++]]=k)
for(k?k--:0,j=sa[Rank[i]-1]; r[i+k]==r[j+k]; k++);
bool judge(int k,int c,int n)
int i,count=1;
for(i=1;i<n;i++)
if(height[i]>=c)
count++;
else
count=1;
if(count>=k)
return true;
return false;
int main()
int n,k,i,Max,L,R,mid,ans;
while(~scanf("%d%d",&n,&k))
Max=0;
for(i=0;i<n;i++)
scanf("%d",&r[i]);
Max=max(Max,r[i]);
r[i]=0;
Suffix(r,sa,n+1,Max+1);
calheight(r,sa,n);
L=0,R=n,ans=0;
while(L<=R)
mid=(L+R)/2;
if(judge(k,mid,n+1))
L=mid+1,ans=max(ans,mid);
else
R=mid-1;
printf("%d\\n",ans);
return 0;
以上是关于POJ 3261 Milk Patterns(后缀数组[可重叠的k次最长重复子串])的主要内容,如果未能解决你的问题,请参考以下文章