笔记
Posted Qunar_尤雪萍
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了笔记相关的知识,希望对你有一定的参考价值。
mysql名词解释/含义/读书笔记
MVCC(Multiversion concurrency control)
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能,这也是为什么现阶段,几乎所有的RDBMS,都支持了MVCC。
在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
快照读
简单的select操作,属于快照读,不加锁。(当然,也有例外,下面会分析)
select * from table where ?;
当前读
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
select * from table where ? lock in share mode;S锁
select * from table where ? for update; X锁
insert into table values (…);X锁
update table set ? where ?;X锁
delete from table where ?;X锁
clustered index
官方文档:
Every InnoDB table has a special index called the clustered index where the data for the rows is stored. Typically, the clustered index is synonymous with the primary key. To get the best performance from queries, inserts, and other database operations, you must understand how InnoDB uses the clustered index to optimize the most common lookup andDMLoperations for each table.
If you define a
PRIMARY KEYon your table, InnoDB uses it as the clustered index.(如果定义的主键,那么InnoDB会选择主键作为聚簇索引。)If you do not define a
PRIMARY KEYfor your table, MySQL picks the firstUNIQUEindex that has onlyNOT NULLcolumns as the primary key andInnoDBuses it as the clustered index.(如果不存在主键,那么Mysql会选择一个唯一建并且唯一建列为Not Null作为InnoDB索引。)If the table has no
PRIMARY KEYor suitableUNIQUEindex,InnoDBinternally generates a hidden clustered index on a synthetic column containing rowIDvalues. The rows are ordered by theIDthatInnoDBassigns to the rows in such a table. The rowIDis a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the rowIDare physically in insertion order.(如果表主键和唯一建都不存在,那么InnoDB内部会生成一个隐藏的包含了列号值,并且作为聚簇索引。)
2PL—Two-Phase Locking:二阶段锁
在数据库和会话程序中,使用2PL来保证线程安全,即获取锁与释放锁。2PL有两个原语:
-Expanding phase : locks are acquired and no locks are released;
-Shrinking phase : locks are released and no locks are acquired;
2PL定于区分了两种锁,Shared locks 和 Exclusive locks。
Mysql 事务隔离级别:Isolation level
在database systems中,isolations 决定事务对于其他用户和系统的可见性吗,PS:ACID(Atomicty,Consistency, Isolation, Durability)。
事务操作中出现的一些名词
幻读
在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几行(Row)数据,而另一个事务却在此时插入了新的几行数据,先前的事务在接下来的查询中,就会发现有几行数据是它先前所没有的。
脏读
某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的,原因是事务能看到别的事务的未提交的结果。
不可重复读
在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据,原因是事务可以看到别的事务提交的结果。
四中隔离级别
Serializable
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
Repeatable reads
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题,GAP锁。
Read committed
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Read uncommitted
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
分析一条Sql的加锁情况,参见何登成博文
- Sql: select * from t1 where id=10;
- Sql: delete from t1 where id=10;
在回答这个问题之前我们需要明确几个前提条件: - 前提一:id列是不是主键
- 当前数据库引擎的隔离级别是什么
- Id列不是主键,那么Id列上面有无索引
- Id列上面如果有二阶索引,那么Id是否是Unique Key
- 两个Sql的执行计划是什么?索引扫描?全表扫描?
另外一个Sql即便通过分析结论会使用索引,但实际执行计划有很多复杂的其他条件,即便”看上去“会走索引但是最终通过执行计划看却走了全表扫描。
组合一:id列是主键,RC隔离级别,执行delete from t1 where id = 10;
create table t1(
id int(32) not null,
name varchar(50) not null,
primary key(id)
);结论:如果id列是主键,这种情况只需要在id=10的列上加上X锁。
组合二:id是Unique_key , RC隔离级别,执行delete from t1 where id=10;
create table t1(
id int(32) not null,
name varchar(50) not null,
primary key (`name`),
unique key `key_name`(`name`)
);执行图(何登成博客获取):

这种组合下面id是二阶段索引,这种情况下和组合一加锁不同,DB引擎先走where条件的Id索引,在对应Id索引上id=10的记录上加X锁,然后根据name值回到聚簇索引上面,并对name=d的值加X锁。为什么聚簇索引上面也需要加X锁,如果不加X锁在delete执行的同事如果一个update t1 set id=100 where name=’d’;就会有冲突。
结论:如果id是唯一索引,name为主键,那么会在id索引上面id=10的记录上加X锁,并且name聚簇索引上name=’d’的记录上加X锁。
组合三:id为非唯一索引,RC隔离级别delete from t1 where id=10;
create table t1(
id int(32) not null ,
name varchar(50) not null ,
primary key (`name`),
key `key_name`(`name`)
);执行图(何登成博客获取):

从图可知,在where条件匹配到的id=10的所有记录均会加上X锁,并且对应到索引上的记录也都会加锁。
结论:若id列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
组合四:id列上无索引,RC隔离级别delete from t1 where id=10;
create table t1(
id int(32) not null ,
name varchar(50) not null,
primary key (`name`),
);执行图(何登成博客获取):
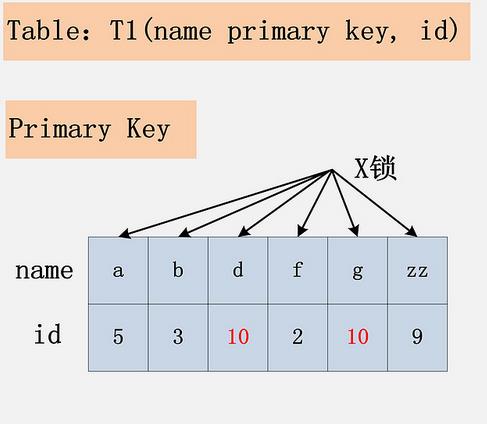
结论:mysql在走where条件的时候由于无法快速通过索引确认影响行,因此会对所有聚簇索引的记录行加上X锁然后返回所有记录。在具体实现时Mysql做了优化,再次通过where条件判断,对于不满足的记录通过unlock_row将X锁进行释放(违背了2PL规范);
组合五:id为主键列,RR隔离级别
这种情况下加锁机制同组合一一致。
组合六:id列为唯一索引,RR隔离级别
这种情况下加锁同组合二一致
组合七:id列为非唯一索引,RR隔离级别 (GAP锁)
由于Mysql事务离别为RC的情况下是允许幻读的,但是隔离级别在RR的情况下是不运行幻读。Mysql是如何做到RR隔离级别不产生幻读?这个组合中会加以说明。
执行图(何登成博客获取):

这里的加锁机制和RC下面的加锁机制相似,唯一区别的是就是RC的加锁情况下增加了一个GAP锁,并且GAP锁不是加到具体的记录上的,而是加载到记录与记录之间的一把锁。
先说说幻读:幻读的意思是说当连续两次执行一个select * from t1 where id=10 for update Sql的时候,前后两次读取的记录数不一致(第二次不会返回比第一次更多的记录数)。
RR隔离级别下,由于B+树索引是有序的,那么需要保证的是在id=[6,10)之间不能插入id=10的记录,详细就是在[6,c]与[10,b]之间插入类似[10,aa]或者在[10,b]与[10,d]之间插入[10,c]时都需要有一把锁来使得这些插入不能执行(即:GAP锁)。
GAP锁之所以在组合五和组合六中不会出现的原因是因为上面两种组合保证了记录的唯一性,也就没有必要使用GAP锁。
结论:Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
组合八:id上无索引,RR事务隔离级别
加锁情况(何登成博客获取):

结论:加锁机制和RC隔离级别下类似,区别是同事为每个记录之间增加了一个GAP锁。任何更新/修改/插入等涉及到加锁的Sql语句都无法执行。欣喜的是同组合四类似,Mysql会提前过滤where条件为不满足条件的提前释放锁。
组合九:Serializable
Serializable情况下,delete from t1 where id=10 通RR情况下一样会通过Gap锁解决掉幻读情况。Serializable影响的是在select * from t1 where id=10 ,这条Sql在RR 和 RC下面都是快照度不加锁,但是在Serializable情况下会加锁。
一条复杂Sql的分析
Sql用例如下(何登成博客获取):

在分析出SQL where条件的构成之后,再来看看这条SQL的加锁情况 (RR隔离级别),如下图所示:

从图中可以看出,在Repeatable Read隔离级别下,由Index Key所确定的范围,被加上了GAP锁;Index Filter锁给定的条件 (userid = ‘hdc’)何时过滤,视MySQL的版本而定,在MySQL 5.6版本之前,不支持Index Condition Pushdown(ICP),因此Index Filter在MySQL Server层过滤,在5.6后支持了Index Condition Pushdown,则在index上过滤。若不支持ICP,不满足Index Filter的记录,也需要加上记录X锁,若支持ICP,则不满足Index Filter的记录,无需加记录X锁 (图中,用红色箭头标出的X锁,是否要加,视是否支持ICP而定);而Table Filter对应的过滤条件,则在聚簇索引中读取后,在MySQL Server层面过滤,因此聚簇索引上也需要X锁。最后,选取出了一条满足条件的记录[8,hdc,d,5,good],但是加锁的数量,要远远大于满足条件的记录数量。
结论:在Repeatable Read隔离级别下,针对一个复杂的SQL,首先需要提取其where条件。Index Key确定的范围,需要加上GAP锁;Index Filter过滤条件,视MySQL版本是否支持ICP,若支持ICP,则不满足Index Filter的记录,不加X锁,否则需要X锁;Table Filter过滤条件,无论是否满足,都需要加X锁。
死锁的原理和分析
死锁的情况1(何登成博客获取):

死锁情况2(何登成博客获取):

上面的两个死锁用例。第一个非常好理解,也是最常见的死锁,每个事务执行两条SQL,分别持有了一把锁,然后加另一把锁,产生死锁。
第二个用例,虽然每个Session都只有一条语句,仍旧会产生死锁。要分析这个死锁,首先必须用到本文前面提到的MySQL加锁的规则。针对Session 1,从name索引出发,读到的[hdc, 1],[hdc, 6]均满足条件,不仅会加name索引上的记录X锁,而且会加聚簇索引上的记录X锁,加锁顺序为先[1,hdc,100],后[6,hdc,10]。而Session 2,从pubtime索引出发,[10,6],[100,1]均满足过滤条件,同样也会加聚簇索引上的记录X锁,加锁顺序为[6,hdc,10],后[1,hdc,100]。发现没有,跟Session 1的加锁顺序正好相反,如果两个Session恰好都持有了第一把锁,请求加第二把锁,死锁就发生了。
参见文档
何登成文章:http://hedengcheng.com/?p=771
mysql文档:http://dev.mysql.com/doc/
以上是关于笔记的主要内容,如果未能解决你的问题,请参考以下文章