论文阅读CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Posted 知识的芬芳和温柔的力量全都拥有的小王同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读CodeBERT: A Pre-Trained Model for Programming and Natural Languages相关的知识,希望对你有一定的参考价值。
目录

paper地址:https://arxiv.org/pdf/2002.08155v4.pdf
代码地址:https://github.com/microsoft/CodeBERT
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
一、简介
CodeBERT是一种可处理双模态数据(编程语言PL和自然语言NL)的预训练模型,支持下游 NL-PL 应用程序(如自然语言代码搜索、代码文档生成等)的通用表示。
CodeBERT基于 Transformer 的架构开发,混合目标函数结合了替换标记检测的预训练任务。
在两个 NL-PL 下游任务上微调,结果显示在自然语言代码搜索和代码文档生成任务上达到了SOTA。此外,文章还构建了一个用于 NL-PL 探测的数据集,并在预训练模型的参数固定的零样本设置中进行了评估。
二、方法
基于RoBERTa
参数总量约125M
1. 输入输出表示
输入: [CLS], w1, w2, …wn,[SEP],c1, c2, …, cm,[EOS]
w为NL单词序列,c为PL token序列。[CLS]为两个片段前的特殊token。
输出:自然语言和代码中每个token的上下文向量表示,以及[CLS]的表示,作为聚合序列的表示
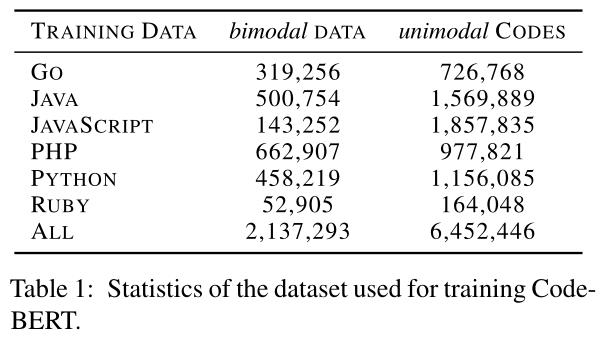
2. 预训练数据
双峰数据+单峰数据
注:
1、双峰NL-PL 对是指类似下面的自然语言-程序语言对,即带有配对文档的单独函数,语料一般以json行格式文件保存,一行是一个json对象:
"nl": "Increment this vector in this place. con_elem_sep double[] vecElement con_elem_sep double[] weights con_func_sep void add(double)",
"code": "public void inc ( ) this . add ( 1 ) ; "
2、单峰数据是指没有成对自然语言文本的单独函数代码和没有成对代码的自然语言
3、数据集CodeSearchNet来自Github仓库,包括六种编程语言,共2.1万个双峰数据点和6.4万个单峰代码
4、数据筛选规则:
(1)每个项目应该被至少一个其他项目使用,(2)每个文档被截断到第一段(图中红色表示),(3)小于三个标记的文档被删除,(4)小于三行的函数被删除,(5)带有子字符串“test”的函数名被删除。图13给出了一个数据示例。

3. 预训练
训练的两个目标:MLM、RTD
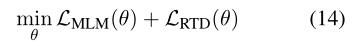
MLM
masked language modeling
对NL-PL对的双峰数据应用MLM,即选择随机位置的NL和PL mask,用特殊token [MASK]代替。
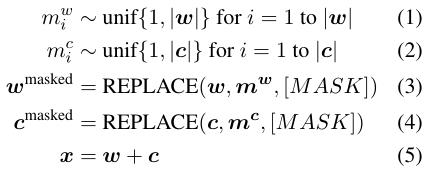
MLM的目标是预测被mask的token。鉴别器
p
D
1
p^D_1
pD1预测第i个单词为masked的token的概率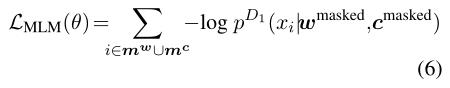
RTD
replaced token detection
训练时同时使用双峰数据和单峰数据,有两个数据生成器
p
G
w
p^G_w
pGw、
p
G
c
p^G_c
pGc,一个生成NL,一个生成PL,用于选择随机掩蔽位置
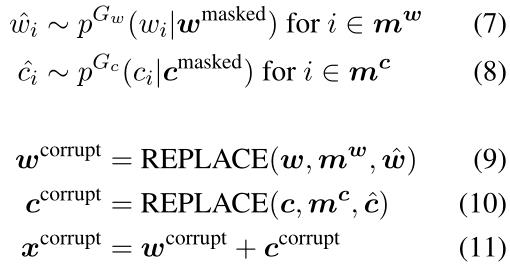
可以理解为MLM找到了一组用来mask的位置
m
w
m^w
mw和
m
c
m^c
mc,然后用[MASK]代替,而RTD是先生成mask掉位置
m
w
m^w
mw和
m
c
m^c
mc的token(code token 和 word token),然后用生成的token代替。
鉴别器
p
D
2
p^D_2
pD2鉴别是否正好生成了原始单词,即预测第i个单词为原始单词的概率,δ(i)为指示函数
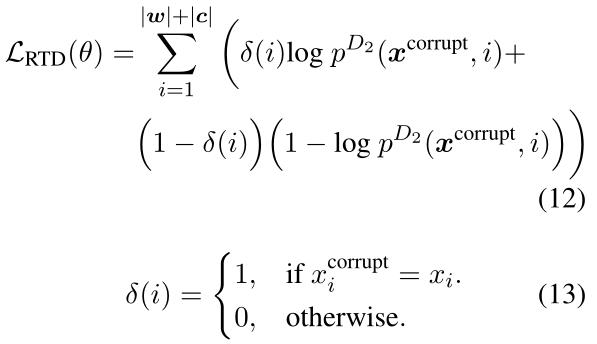
4. 微调
下游任务:natural language code search、code-to-text generation
natural language code search
输入和预训练一样的数据,用[CLS]表示代码和自然语言间的语义关联
code-to-text generation
基于Encoder-Decoder框架,用CodeBERT初始化Encoder
三、实验
1. Natural Language Code Search
下游任务之一,对CodeBERT中的模型参数进行微调
任务
输入给定自然语言,从一组代码中找出语义最相关的代码
评价指标
MRR,即Mean Reciprocal Rank,把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。计算所有编程语言的平均MRR作为总的评估指标。
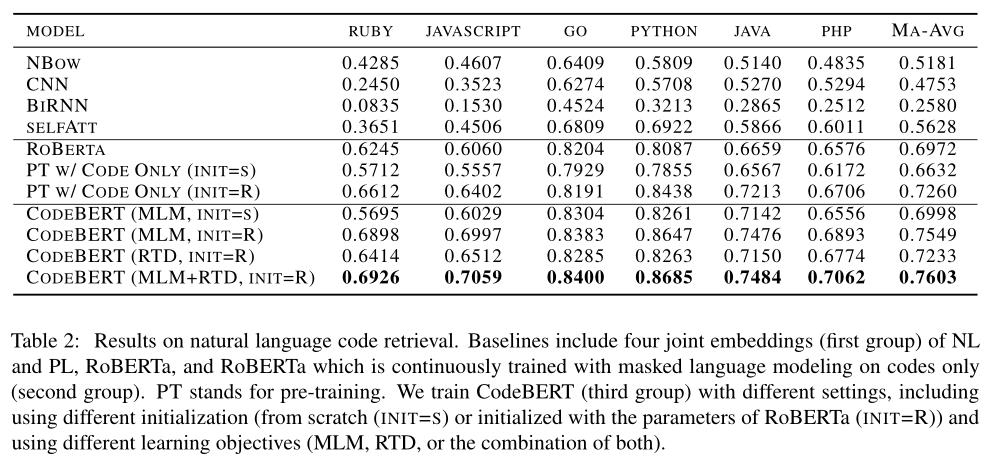
实验结果
2. NL-PL Probing
NL-PL探测任务,用零样本(zero-shot)评估参数固定的CodeBERT
任务
给定一个NL-PL对(c, w),预测/恢复感兴趣的masked token(代码token
c
i
c_i
ci 或单词token
w
j
w_j
wj),形式为完形填空选择题

注:
-
对于NL,选定的NL- PL对中其NL文档包含6个关键字之一(max、maximize、min、minimize、less、greater),并通过合并前两个关键字和中间两个关键字将它们分组为4个候选者。
任务是要求预先训练过的模型选择正确的一个,而不是其他三个干扰因素。此设置中的输入包括完整的代码和屏蔽的NL文档,目标是从四个候选答案中选出正确答案。 -
对于PL,选择包含关键字max和min的代码,并将任务表述为一个双选题。输入包括完整的NL文档和屏蔽PL代码,目标是从两个候选答案中选择正确答案。
评价指标
正确率,正确预测实例的数量与所有实例的数量之比
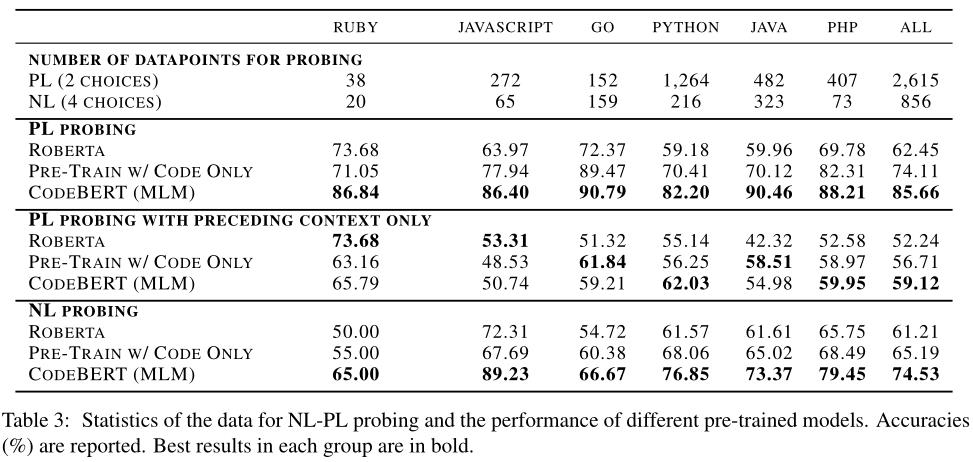
实验结果
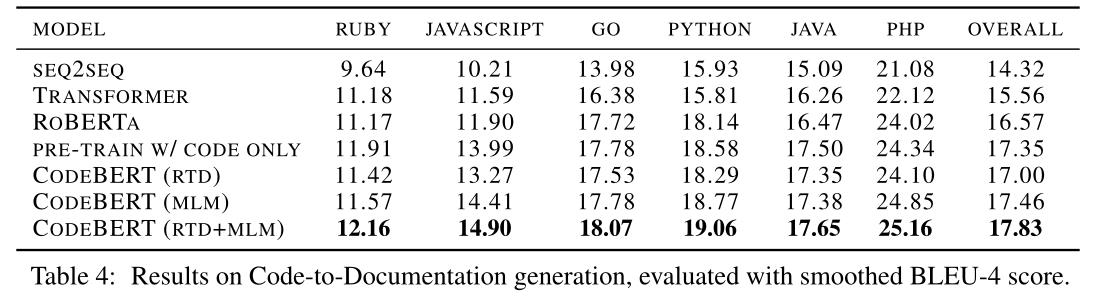
3. Code Documentation Generation
任务
给定PL生成相关描述NL
评价指标
BLEU
(因为生成的描述PL文档很短,高阶n-g可能不会重叠,所以选用了平滑的BLEU)
实验结果
4. 泛化实验
编程语言的泛化不是在预训练
预训练CodeBERT的数据集包括了Python, Java,
javascript, php , Ruby, Go六种编程语言,文章这节测试了CodeBERT在C#上的效果来展示CodeBERT应对没有见过的编程语言的能力
数据集
CodeNN,由StackOverflow自动收集的66015对问题和答案组成的数据集
任务
生成c#代码段的自然语言摘要
评价标准
BLEU-4
实验结果
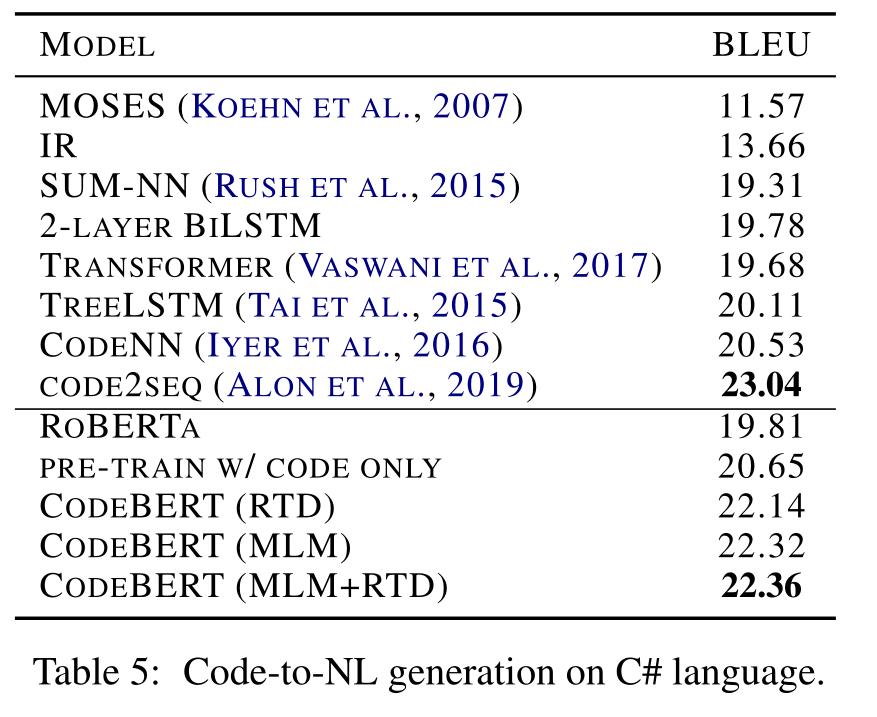
模型在MLM和RTD的预训练目标下取得了22.36的BLEU分数,比RoBERTa提高了2.55分,可以更好地推广到其他编程语言
略低于code2seq,分析可能是由于code2seq在其抽象语法树(AST)中使用了组合路径,而CodeBERT只接受原始代码作为输入
有帮助的话可以点个赞喔~

以上是关于论文阅读CodeBERT: A Pre-Trained Model for Programming and Natural Languages的主要内容,如果未能解决你的问题,请参考以下文章