基于 Web 引擎技术的 Web 内容录制
Posted singwhatiwanna
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 Web 引擎技术的 Web 内容录制相关的知识,希望对你有一定的参考价值。

随着基于WebRTC技术的Web应用快速成长,记录web在线教育、视频会议等场景的互动内容并对其准确还原越来越成为一项迫切需求。在主流浏览器中,通常基础设施部分已实现了页面渲染结果的采集及编码。开发者可以利用浏览器提供的API对页面内容进行录制。但受限于Web标准以及浏览器厂商在专利授权方面的问题,使用Web API实现页面录制在易用性和可用性上均较难令人满意。针对上述问题,声网Agora Web 引擎高级架构师高纯在 RTE 2020 实时互联网大会上就Web引擎渲染采集原理进行了分享,并就基于Web引擎的服务端录制技术进行探讨。

▶️点击「阅读原文」可观看视频回放,获取 PPT
以下为演讲实录:
大家好,我这次技术分享的主题是Web互动场景还原—基于Web引擎技术的Web内容录制。
我叫高纯,是来自声网的Web引擎高级架构师,接下来我将会为大家介绍以下的内容:包括应用背景、浏览器内容采集、服务端Web录制引擎,服务端Web录制引擎性能优化,最后会进行一个总结。
先看一下应用的背景,我们知道最近几年随着RTC行业的火热,基于Web RTC技术的Web应用快速成长,记录Web在线教学、视频会议等场景的互动内容并对其进行准确的还原越来越成为一项迫切的需求。
在主流的浏览器当中,其基础设施部分已经实现了对页面渲染结果的采集及编码过程,开发者可以利用浏览器提供的Web API对页面内容进行采集以及录制。但是受限于Web标准以及浏览器厂商在专利授权方面的问题,要使用Web API实现页面录制,在易用性和可用性方面还难以满足业务需求。
浏览器内容采集

我们先来看一下浏览器内容采集,所谓Web录制实际上就是对页面内容采集及编码并存储的过程,在主流的浏览器当中它的工作基本上都是在一个多进程的架构之上,页面的渲染会在一个或者多个的Render Process里面处理,最终的结果会在Browser Process里面来进行呈现,我们要做的事情就是在Renderer Process里面渲染的内容包括视频、音频及其他动画来进行采集并且录制成文件,这个过程就是页面内容采集。

目前在chrome浏览器上面我们可以使用两种方法来进行页面的采集,一种方法是通过chrome extension,目前chrome extension API提供了一条叫做chrome.tabcapture的对象,这个对象当中的capture API可以用来进行页面内容的采集,结合html5标准当中的其他模块,比如说像LocalMediaStream、MediaRecorder以及Blob这些组件,我们可以对页面内容进行采集及录制。

它的大概流程如这个示例代码所展示的一样,在使用chrome.tabcapture API的时候,我们需要给它传入一个是否允许video的采集,以及是否允许audio的采集,并且还要传入一些video相关的分辨率、采集帧率等信息。然后这条API在执行的时候会通过一个回调,把它采集到的结果以LocalMediaStream 的形式返回,我们在回调函数中拿到LocalMediaStream的对象之后,可以利用这个Stream对象来创建一个Media Recorder,同时给这个Media Recorder来指定我们视频编码的码率、音频编码的码率,以及我们视频编码的格式。
目前在chrome上面,它所支持的视频编码格式主要有H264、VP8、VP9。音频它只支持Opus格式,在文件格式方面他目前只支持WebM的媒体格式,通过调用MediaRecorder.start()方法,我们可以发起录制过程,在MediaRecorder的ondataavailable回调当中,他会把采集到的编码处理之后的视频数据返回。
我们拿到这个返回的数据之后可以把它交给一个blob来进行存储,在录制结束之后,我们可以利用这个blob来创造一个超链接,把这个文件下载下来,这就是用chrome extension来进行采集的一个过程。
这个过程的主要问题有什么呢,主要有以下几点,一个是他的音频编码仅支持opus格式,opus实际上支持的媒体格式是比较有限的,像在TS这种流媒体文件中它是不被支持。视频编码方面他提供的可选参数非常有限,视频编码的性能相对比较弱,另外由于他仅支持webm格式的录制,且没有往这个文件当中写入进度信息,录制出来的文件在播放的时候是没有办法去拖动的,另外由于是在录制完毕的时候才会生成整个文件,它的可用性是比较差的,一旦在录制过程中出现了故障,服务出现了崩溃,这意味着我们之前所录制的所有内容都会丢失。

我们来看另外一种页面内容的采集方式,是利用chrome devtools API来进行采集,chrome devtools API它是第三方应用来驱动chrome工作的一个API,它支持chrome以headless模式来工作。第三方的应用和chrome之间进行通信是使用chrome devtools protocol协议。但是它只能采集chrome可视的数据,音频是没有办法采集的,它目前提供了三条API来做页面内容的采集。包括StartScreenCast()、StopScreenCast()、以及CaptureScreenstot()。Capture Screenstot可对页面进行截图,只能采集单帧的数据存储到image文件。我们主要使用的是StartScreenCast、StopScreenCast这两条API,它的方法大概是以下几个步骤:
首先我们要启动chrome,启动chrome的时候需要给它加上Headlees参数,令chrome以Headless模式启动,所谓Headless模式就是以一个服务进程在后台运行,他是没有用户界面的,在启动它的时候,我们需要给它带上remote debugging port调试端口的参数,同时要指定它渲染结果的窗口大小。

在启动Headless chrome之后我们可以利用一个node应用,在应用中使用google提供的叫做chrome remote interface的插件。利用这个插件我们就可以和Headless chrome进行通信来获取它采集到的数据。
具体的调用过程,首先会创建一个chrome remote interface的对象,并且拿到这个对象当中的Page对象。我们通过调用Page当中的startScreenCast的方法,来给它传入相应的编码格式,然后能够获取到它的每一单帧的数据,请求每一帧的数据方法叫做ScreenCastFrame,通过这个示例代码可以看到,浏览器在编码的时候,它采用的是图像的编码方式,目前chrome支持两种方式,一种是png一种是jpeg,我们拿到了这个png/jpeg的数据之后需要对这个图像进行解码,利用我们写的插件来对它进行视频的重新编码,然后保存为文件,这个是利用chrome devtools API来采集的整个过程。
用chrome devtools API采集主要的问题是什么,它主要有三种问题,一个是整个过程他会有png/jpeg数据的编码、解码,以及视频的编码过程,它整个开销是很大的,另外它不支持音频的采集,然后在node应用和chrome应用之间它是使用websocket来进行数据传输的,它的传输性能是比较差的。
在介绍完两种主要的chrome进行页面数据采集的方法之后,我们来给大家介绍一下,chrome是怎么进行页面渲染的,它的流程大概是怎么样。然后chrome内部又提供了哪些接口来让我们进行页面采集和录制。

我们知道chrome浏览器或者web引擎在解析了HTML文档之后会创建DOM树,DOM Tree中的每一个节点它都对应到HTML文档当中的一个节点。对DOM tree应用CSS属性之后,会生成相应的layout tree,layout tree中的每一个节点就是layout object,它除了能够表达它在文档结构当中的位置,它还能表达它在排版过程中的所有属性。
在页面绘制的过程中,web引擎它不会对整个layout去进行完整的绘制,它会对layout tree进行一个分层,对每一层进行独立的绘制,最后通过合成器把不同的绘制结果合成出来。
这个分层的过程其实是有一些规则的,它主要包含哪些规则呢?
首先我们的DOM Tree的根节点以及和它相关的这些节点,会作为一个layer来进行绘制,有一些特殊的节点比如包含一些位置信息应用了relative, absolute或者transform属性的这些节点,也会作为独立的层来进行绘制渲染,对于一些应用了CSS filter的节点也会作为独立层渲染。
假如说有一些节点会产生溢出会产生overflow它也会进行独立的绘制。另外在DOM Tree中,对于一些特殊的节点,比如说像video element 或者canvas element来进行2D或者3D内容绘制的时候,这些节点也会作为独立的层来进行绘制。

在分层之后,我们的web engine会对render layer 或者paint layer来创建相应的Graphics Layer,由所有Graphics Layer组成的树就叫做Graphics Layer Tree,每一个Graphics Layer当中会维护一个Graphics context,这个Graphics context就是这一层内容绘制的一个目标。每一个Graphics layer还会维护一个叫paint controller,这个paint controller会来控制我们每一层具体的绘制。
除了Graphics layer tree之外我们的layout tree 在预绘制的过程当中还会生成相应的Property Trees,所谓的Property其实是指四种类型的属性,它包含了像Transfer,一些位置的变换;或者是clipping,对内容进行裁剪;包括effect,一些特效,比如像透明度或者mask信息;然后还有scroll信息,就是当我的内容需要进行滚动的时候它也会有自己的一些信息,这些属性都会存储在这个Property Trees里面。
当我们的DOM文档结构发生变化的时候,或者CSS属性发生变化的,或者是Compositing发生变化的时候它会产生相应的invalidation,一旦invalidation发生,layout Tree会找到它发生变化的相应的节点,然后会利用它相应的Graphics layer来进行绘制。这个图是发生变化的区域。
绘制的过程实际上就是把layout Tree当中的layout Object属性转换成绘制指令的过程,这个绘制指令是通过术语display items来进行表达的。

有了这个Graphics layer Tree和Property Trees,之后我们可以对Graphics layer tree中的每一层来使用Compositer来进行合成,由于Compositer的输入有自己的格式,我们需要对Graphics layer tree和Property Trees进行转换,需要把Graphics layer tree转成layer list,把blink Property Trees转成CC Properties Trees。拿到这两个结构之后浏览器接下来就可以进行合成。

所谓的合成就如上面这张图所显示的,它是把浏览器当中的不同的部分,以及浏览器的界面进行层叠。最终显示出我们可以看到的最终效果的过程。但是在浏览器当中实际的合成过程是分成两个部分的,有两个阶段。

在第一阶段是在浏览器的渲染线程来实现的。它通过刚才我们拿到的layer List和CC Properties Trees来形成光栅化,如果是软件光栅化会生成位图,如果是硬件光栅化会形成GPU当中的纹理。
拿到这些结果之后来进行层叠处理,最终Compositer会输出一个叫做Compositer Frame的数据,Compositer Frame并不是实际的最终渲染的结果,它不是一个位图或者一个纹理,它实际上也是一系列的绘制指令,这些指令在光栅化之后才会产生实际的位图或者是纹理。
在第二个阶段我们的浏览器会利用dispaly Compositer 把我们上一阶段的合成结果和浏览器的UI部分,比如说像地址栏、标题、标签页的按钮来进行合成,最终输出到物理设备上面,这整个渲染过程就完成了。在render进程和browser(浏览器)进程之间它的数据传输是通过shared Memory的形式来传输的。
通过了解上面的这个过程其实我们就可以很明显的发现,如果我们需要对chrome当中的页面进行采集的话我们需要的是什么,我们需要的其实就是Compositer Frame光栅化之后的bitmap 或者是texture,通过对这个数据的编码以及经过muxer存储文件,我们的录制就可以完成了。
接下来我们来看一看chrome这个项目当中提供了哪些接口来让我们对音视频数据进行采集。在chrome当中由于它的渲染进程是跑在sandbox(沙盒)里面的,在sandbox(沙盒)进程当中是没有办法对系统调用,它对系统API的调用是受限的,由于我们的录制需要去访问本地文件,所以我们整个的采集过程是在Browser进程来实现的。

chrome在Browser线程提供了ClientFrameSinkVideoCapturer这个类,这个类会向渲染线程发起相应的采集请求,客户程序只需要通过当前tab页对应的CreateVideoCapturer来实例化这个类。
同时实现FrameSinkVideoConsumer这个接口,通过这个接口当中的OnFrameCapturer的回调来获取它返回的每一帧的Video Frame数据。

在Render进程大概的过程是怎么样的呢(如上图所示),由于时间有限我不做太多的介绍。只描述一下简单的过程,在类FrameSinkVideoCapturer当中,当它接收到Browser端发来的采集请求,就会去Schedule一次采集的请求。然后会把这个请求转发给它聚合的CompositorFrameSinkVideoSupport对象,这个对象拿到请求之后,会把这个请求放在队列里面。
由于CompositorFrameSinkVideoSupport对象,它实现了SurfaceClient的接口,可以从Compositer当中拿到输出的Surface,一旦有新的Surface产生它就会得到通知,它会利用实现的CompositerFrameSink接口,通过其中的didAllocateSharedBitmap方法来创建相应的共享内存,然后把Surface当中的数据写到共享内存当中,同时会把这个共享内存的ID返回给Browser进程,Browser进程拿到这个ID之后会从Shared Memory里面把数据给解出来,这个采集过程就完成了。

那么对于音频的处理呢(如上图所示),chrome在进行音频播放的时候它会把页面当中所有的Audio Media Streams直接交给系统的Audio framework来进行混音和播放。它的混音的过程是由Audio framework来做的。如果我们需要对所有的Audio media Streams进行采集的话我们需要自己来实现混音的过程,混音之后的Audio 数据我们把它交给encoder进行编码,最终存储到文件里面来。

同样在chrome当中它也提供了相应的接口,让我们来进行音频数据的采集,这个接口主要有AudioLoopbackStreamCreator以及Audio input stream这两个类。
我们通过创建AudioLoopbackStreamController来启动一个音频采集过程,在启动之后它会通过AudioLoopbackStreamCreator去创建一个AudioLoopbackStream,同时它会去创建相应的线程,这个线程会通过Socket不断的从Render 进程来获取采集到的音频数据,一旦这个Audio frames达到一定量之后足够多,它会去出发相应的callback,这个callback回调会最终把数据交给录制程序。
所谓的AudioLoopbackStream是chrome当中一个特殊的数据,它称为回环音频流,它会把chrome当中所有输出的Audio Streams进行合成,然后把合成的结果转换成一个输入流。
具体在Render端是怎么实现混音的过程我们在这个地方就不展开描述了。
服务端 Web 录制引擎
接下来我们聊一聊在服务端进行WEB录制它所需要的一些需求,主要有几点。

一个是无UI模式,我们在服务端进行页面内容的采集,它通常是跑在一个无桌面的linux的服务环境下,同时它采集的格式需要满足实现流媒体格式。因为传统的媒体格式往往是存储单个的文件,一旦服务端发生了故障,它之前所录制视频内容很有可能会丢失。同时录制引擎也需要去指定一些录制参数。比如说页面渲染的分辨率,最大的视频录制帧率,音频采样率、音频编码率,包括流媒体文件切片的时长等等。由于我们的Web Engine是一个开放的平台,理论上它是可以运行所有的Web应用的。有一些Web应用可能性能开销会非常大,所以在服务端Web应用录制的过程当中我们需要对整个应用的开销进行监测。对于可能产生系统资源过度使用的HTML5组件来进行一些控制。同时对引擎内部运行的一些状态进行监测,发生错误要能进行上报。
我们声网在实现相应的Web云录制引擎当中针对这四点也做了大量的工作,主要是Headless模式我们是基于Chromium Headless模式实现的,它不需要像Xvfb这样的虚拟X Server环境作为页面的渲染目标。
另外由于我们整个录制过程是一个无交互的过程,我们需要允许引擎能够令这个音视频内容在无交互的情况下进行自动播放。
另外很重要一点是我们的录制引擎是不提供Web API的,不需要Web应用主动发起录制的请求。页面的录制结果是一个所见即所得的过程。Web引擎当中渲染了什么内容,它就会做出相应的录制。
对于录制格式方面我们主要支持TS和M4A两种流媒体格式,同时会输出相应的M3U8的文件列表,在编码器方面我们可以选用Openh264、X264、声网自研的a264编码器来对录制内容进行编码。
我们整个录制过程是一个动态帧率的编码过程,只有当页面发生变化的时候,输出新的video frame的时候我们才会对它进行采集和录制。
在音频部分我们使用的是刚才介绍过的AudioLoopbackStream来进行混音,对混音的数据进行采集再进行编码。音频的编码我们使用AAC格式,因为像ts这种流媒体格式当中opus编码格式是不受支持的,AAC格式通常在更多的媒体文件类型下能得到更好的支持。

我们提供的参数主要有这些(如上图),视频输出的路径包括日志的路径,同时可以指定音频的采样率是41000或者48000赫兹,录制的声道数,录制的音频的码率,视频编码的码率,以及视频的录制帧率,我们页面渲染的尺寸高度或者宽度,流媒体HRS文件它切片的时长等等都可以进行设定。
同时也会对H5的一些性能开销比较大的组件进行一些控制,比如说像WebGL、Web Assembly ,同时对于一些比较大的尺寸的视频,对它的播放进行一些控制。
在性能和安全性方面,其实刚才也提到了,主要会对Web GL、Web Assembly包括高分辨率的视频进行播放的时候会进行一些开关。然后我们引擎本身也会对CPU、内存、带宽等等系统资源进行自我监测和上报,对于一些文件操作,比如说像文件下载,包括对file://scheme访问会进行限制。在URL加载异常的时候会对异常以及异常的原因会进行一个上报,对页面音视频的采集过程以及编码的状态也会进行上报,这些内容会上报到我们服务端的应用框架当中,服务端应用框架收到这些上报信息之后会做相应的处理。

引擎对外发出的一些通知,主要有录制的开始结束,包括文件切片的开始以及完毕,有音视频编码器的初始化成功或者失败,还有采集到第一帧音频的时候或者第一帧视频的时候都会发出相应的通知,还会在音频编码失败的时候和视频编码失败的时候发出一些通知。录制引擎还会周期性的去监测我们距离上一帧采集到音频或者视频的时间间隔。
当URL访问出现异常的时候会对URL异常的原因进行上报。最后Recording Prof,会对CPU、内存、带宽使用率进行通知。
刚才介绍了服务端Web录制引擎的一些特征,包括声网在实现Web录制引擎当中做的一些事情。
服务端Web录制引擎性能优化
接下来我们聊一聊Web录制引擎性能优化,Web录制引擎它的整个的过程本质上是一个从视频解码、音频解码到页面渲染、页面合成再到视频音频编码的过程。它整个过程的开销实际上是非常大的。
我们目前主要有几点对Web录制引擎进行优化。第一点就是chrome本身它在使用OpenH264的时候,出于平台兼容性的考虑,它没有启用AVX2指令来做CPU的优化,AVX2指令是在intel haswell平台之后推出的AVX指令的扩展,它扩展了原来AVX的指令计算数据的位宽,从128位扩展到了256位,能够有更好的向量运算的性能。

另外一个优化点就是使用GPU来做编解码的加速,我们知道limux平台上面通常它的显示驱动或者设备,性能一般不是太好,或者有各种问题,出于这个原因chromium把linux平台的硬件加速的视频编解码列入了黑名单,也就是说它只用软件的方式来进行音视频的编解码。

由于我们的整个系统是运行在服务端,这个平台是确定的,在保证这个平台的图形的驱动稳定的情况下,我们可以去把这个视频编解码从黑名单中移除来启用它的硬件加速。同时我们在对视频进行编码的时候可使用ffmpeg加VAAPI来进行硬件加速。
第三个就是对页面渲染性能本身的一个优化,chrome headness一些特殊的条件下,可以在limux服务器上去使用OpenGL进行硬件加速,但是它要求我们的整个服务端的环境必须是在桌面系统上,也就是基于X11的OpenGL去进行硬件加速。

由于我们的录制引擎通常是部署在multi user模式下的linux服务器上面,它是没有桌面环境的,在这个时候我们可以在chromium当中使用ozone图形中间层,结合DRM后端来实现脱离X11的OpenGL硬件加速。ozone是ChromiumOS上面默认所采用的图形子系统,它是一个中间层。它的后端可以有各种不同的实现,比如说有基于X11,Wayland, 或者基于GBM/DRM的,基于DRM的实现它可以脱离桌面环境,这样我们可以在headness multi user模式的来enable硬件加速。
最后的一个优化过程是对web引擎渲染流程流程本身的一个优化,刚才我讲到整个的Web录制过程实际上是音视频解码—页面渲染—合成—编码的过程,性能开销非常的大。
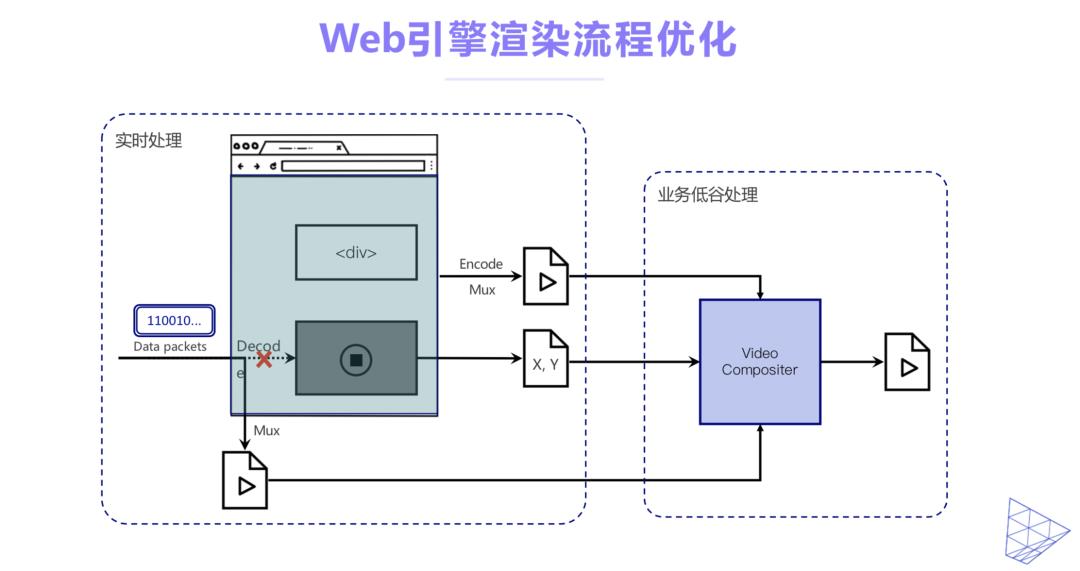
对于整体的渲染流程我们可以来进行一些优化,比如说业务高峰时期在实时处理的时候,我们接收到视频数据之后可以不进行解码也不进行播放,直接把接收到的视频流进行转储,存储为相应的视频文件。
在页面当中视频的区域我们使用空白来进行占位,同时对区域的位置进行记录,以及对这个视频的播放状态,是播放还是暂停、停止来进行一个记录。
我们知道页面当中如果没有视频的渲染的话,通常它的FPS都是比较低的,这就意味着我们从这个浏览器当中采集出来的video frame的帧率会很低,甚至是静止,这样它的编码开销就很小。我们把没有视频部分的page进行编码进行录制来生成文件之后就能得到页面部分的文件。以及从Media stream(流媒体)转储的视频文件以及视频的一些状态信息,有了这三个信息之后,我们可以在业务低谷时间进行视频的合成,来有效的降低我们在业务高峰时段的服务器的压力。以上就是服务端的录制引擎的性能优化。
最后,我们来进行一个总结,主要有以下几点。
当前主流的浏览器对Web录制的支持并不能满足我们的业务需求。
我们所需要的业务能力和可用性可以通过定制chromium浏览器来实现。
Web云录制作为一种新的技术和业务形态,它面对性能和安全性的双重挑战。
我们针对目标硬件平台来进行CPU和GPU的优化能够比较有效的缓解性能的问题。
通过对Web引擎渲染流程进行特殊优化能够有效的降低我们的服务在业务高峰时的性能压力。
以上就是我的分享,非常感谢。
回顾更多演讲,可访问:rteconf.com/look-back

以上是关于基于 Web 引擎技术的 Web 内容录制的主要内容,如果未能解决你的问题,请参考以下文章
SpringBoot的Web开发支持与Thymeleat模板引擎
jmeter压测学习48- BadBoy录制web网站登录页面脚本
LoadRunner录制上传文件,web_custom_request函数的Body属性显示了上传文件的内容。我如何参数化???