RepVGG网络学习记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RepVGG网络学习记录相关的知识,希望对你有一定的参考价值。
在ResNet等被提出前,VGG可谓是风靡一时,但当ResNet等横空出世后,VGG便遭受了冷落,甚至一度被人所遗忘,而今天所要介绍的是由清华大学与香港科技大学联合提出了一个VGG的衍生模型,试图让曾经风光不再的VGG容光焕发。
之所以RepVGG能够一骑绝尘达到STOA水平,源于其提出了在训练时使用下图B的网络结构,而在推理时则采用下图C的网络结构,而为何能够如此转换,这就是论文提出的思想:结构冲参数化
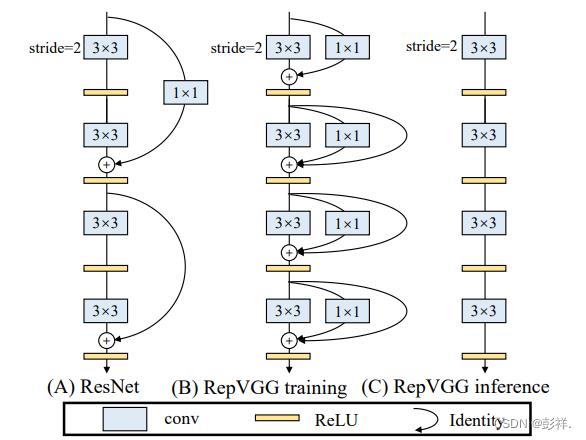
RepVGGBlock讲解

在训练模式下的RepBlock分为两种,一种是左边的步长为2进行下采样的,另一种是右面步长为1的,我们主要看的是第二种。该网络结构分为三个分支结构,设置卷积核为3*3,步长为1,padding为1。
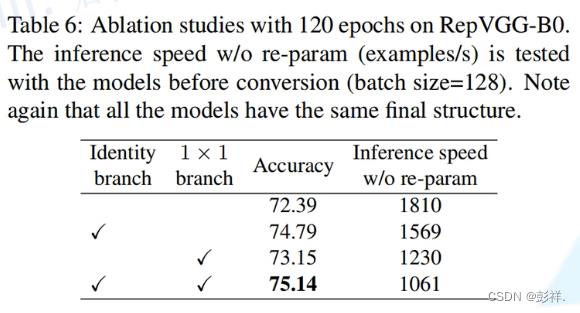
那么为何要采用多分支结构呢?事实上按照经验可知增加分支结构是能够增强模型的表征能力的。下面的消融实验给出了实验支撑:
那么为何我们在推理时却要将多分支转换为单路模型呢?
作者给出了理由:更快,更节省内存,更灵活。
更快:在下图种,训练模型的这种并行结构不见得会速度更快,首先,其卷积核大小不同,操作不同所需要的计算时间也会不同,而相加操作必然会造成水桶短板效应,其次,每个分支都需要读取原始数据,这就要访问内存,这个时间成本也是需要考虑的。而采用这种单路结构后,便会节省大量时间。

省内存:每一个相加操作需要保留特征图,其会占用内存。

更灵活:进行优化单路更加方便,模型压缩(剪枝、量化)更容易。
关于模型剪枝
深度学习网络模型从卷积层到全连接层存在着大量冗余的参数,大量神经元激活值趋近于0,将这些神经元去除后可以表现出同样的模型表达能力,这种情况被称为过参数化,而对应的技术则被称为模型剪枝。
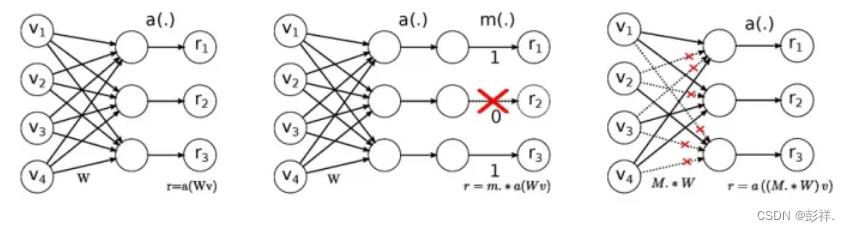
作者刚刚听到模型剪枝这个概念时有效困惑,这是新概念吗?其实我们从学习深度学习的第一天起就接触过,Dropout和DropConnect代表着非常经典的模型剪枝技术,看下图。
当然,模型剪枝不仅仅只有对神经元的剪枝和对权重连接的剪枝,根据粒度的不同,至少可以粗分为4个粒度。
细粒度剪枝(fine-grained):即对连接或者神经元进行剪枝,它是粒度最小的剪枝。
向量剪枝(vector-level):它相对于细粒度剪枝粒度更大,属于对卷积核内部(intra-kernel)的剪枝。
核剪枝(kernel-level):即去除某个卷积核,它将丢弃对输入通道中对应计算通道的响应。
滤波器剪枝(Filter-level):对整个卷积核组进行剪枝,会造成推理过程中输出特征通道数的改变。
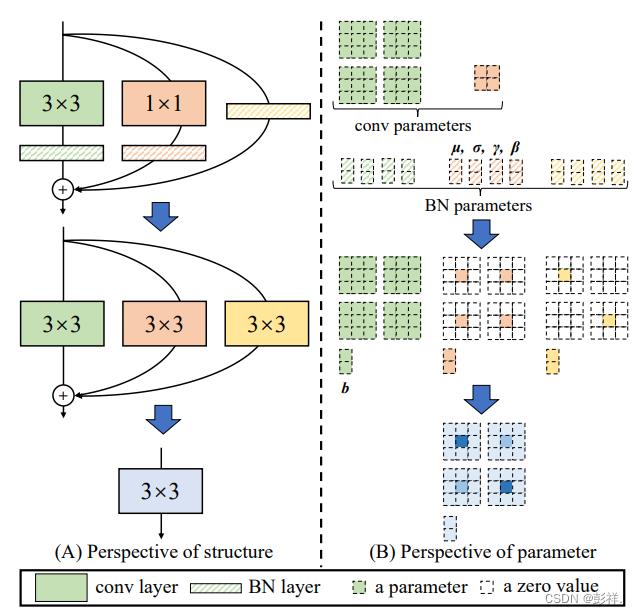
接下来我们来看本篇论文的核心部分:结构重参数化
结构重参数化

在下方给出了设定,设定in_channel=out_channel=2,那么这就对应我们右面的参数矩阵个数,因为输出通道=2,那么就要有两个kernel使其有两个输出,而输入chanel=2,则表明每个channel中还也要有两个特征图(kernel)。这是两个过程所决定的。此外BN层参数个数是与输出通道个数报错一致的。
然后其将所有矩阵进行映射为3*3后进行融合。
卷积层与BN融合
卷积融合

卷积与BN融合

以上完成的便是下面的公式表达:

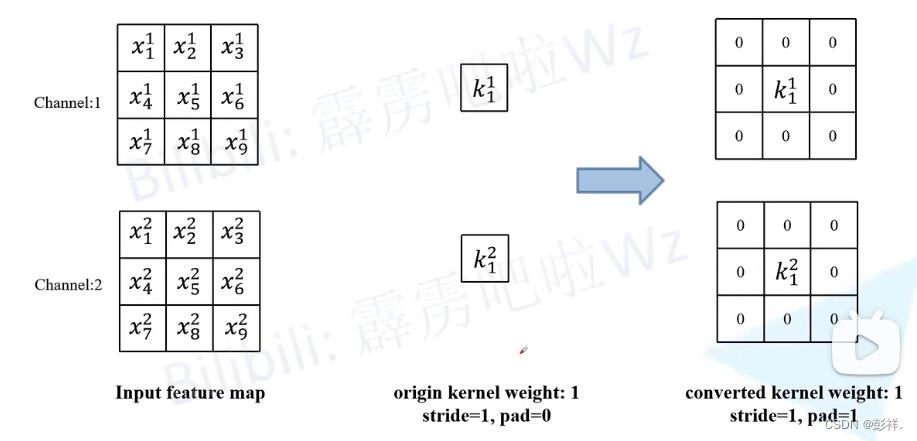
11与33的融合
很简单,只需要在1*1边上补零即可
BN转换为3*3
也是很简单,需要两个通道,每个通道里面两个卷积核即可。在与输入特征图做卷积操作得到输出特征图。

注意:
三个分支都是做的卷积操作。
最终都是3*3,那么就可以融合了。
那么最后便是完成分支融合了:

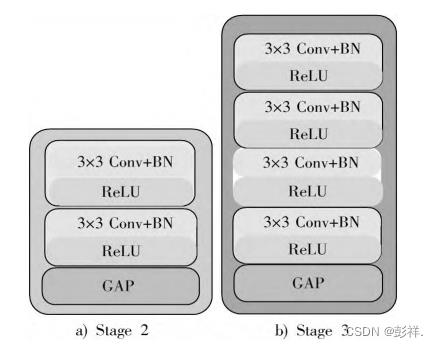
才外,RepVGG有多个版本,区别在于深度不同,但其内部都是按照stage来划分,如RepVGG-A0,该网络模型共有 5 个阶段(stage),每个阶段的层数分别为 1,2,4,14,1。
以上是关于RepVGG网络学习记录的主要内容,如果未能解决你的问题,请参考以下文章