深入理解Kotlin协程Google的工程师们是这样理解Flow的?
Posted 川峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解Kotlin协程Google的工程师们是这样理解Flow的?相关的知识,希望对你有一定的参考价值。
Question:why there is a Flow in kotlin?
问这个问题就好比在问为什么那里会有一座山存在,嗯,这貌似是一个哲学问题。当然,对于kotlin中的Flow的理解可能不会上升到这么高的哲学层次,对于Flow相关的Api掌握并使用它并不是什么难事,但是我们需要思考的是为什么会有Flow这样的存在?
其实flow的背后是协程,那么kotlin中的协程框架已经能够做到异步任务问题的解决方案了,为什么还要设计Flow呢?设计这个玩意的最初的目的和构想是为了什么样的意图?
为了搞明白这个问题的真相,我特意通过科学上网的方式,了解了一下Google的android工程师们对Flow的理解。下面主要是记录一下理解产生Flow这个想法的过程。
注意看,下面这个男人叫小帅,他每天的一项任务就是提着水桶到湖边去取水。


小帅一年365天都在重复着这样的内容,可是不出意外的话,意外终于发生了,有一天小帅来到湖边后发现湖泊居然干了,于是他不得不尝试跑去寻找其他新的水源。

但是聪明的小帅很快就发现了问题,他在想:与其这样到不同的湖边跑来跑去,为什么不能在湖边架设一根管道,然后让水流沿着管道自动流过来呢?就像下面这样:

这样即使有多个湖泊也可以通过管道将它们连接起来:

这样以后小帅就不必每次亲自跑到湖边去检查湖泊有没有干,只要湖泊没有干,那么小帅在管道的另一头只需要拧开水龙头,就会自动有水流出。
现在回想一下在一个应用当中,其实我们请求应用界面所需的数据跟这个场景很相似,不是吗,想象一下,我们平时是不是在到处请求数据,然后拿到数据以后再返回到使用它的地方去更新View界面?就像下面这样:

我们就跟小帅一样,不停的在应用的各个地方去请求数据,拿到数据后再返回到UI界面去更新,而且这样的地方非常的多,因此我们总是为此而疲于奔命,有时甚至感到分身乏术。

假设我们不再请求数据,而是改为观察数据,观察数据就像安装管道一样,我们在上游的数据源位置安装管道,一旦部署到位,对数据源的任何更新都将自动流向下游的视图当中:
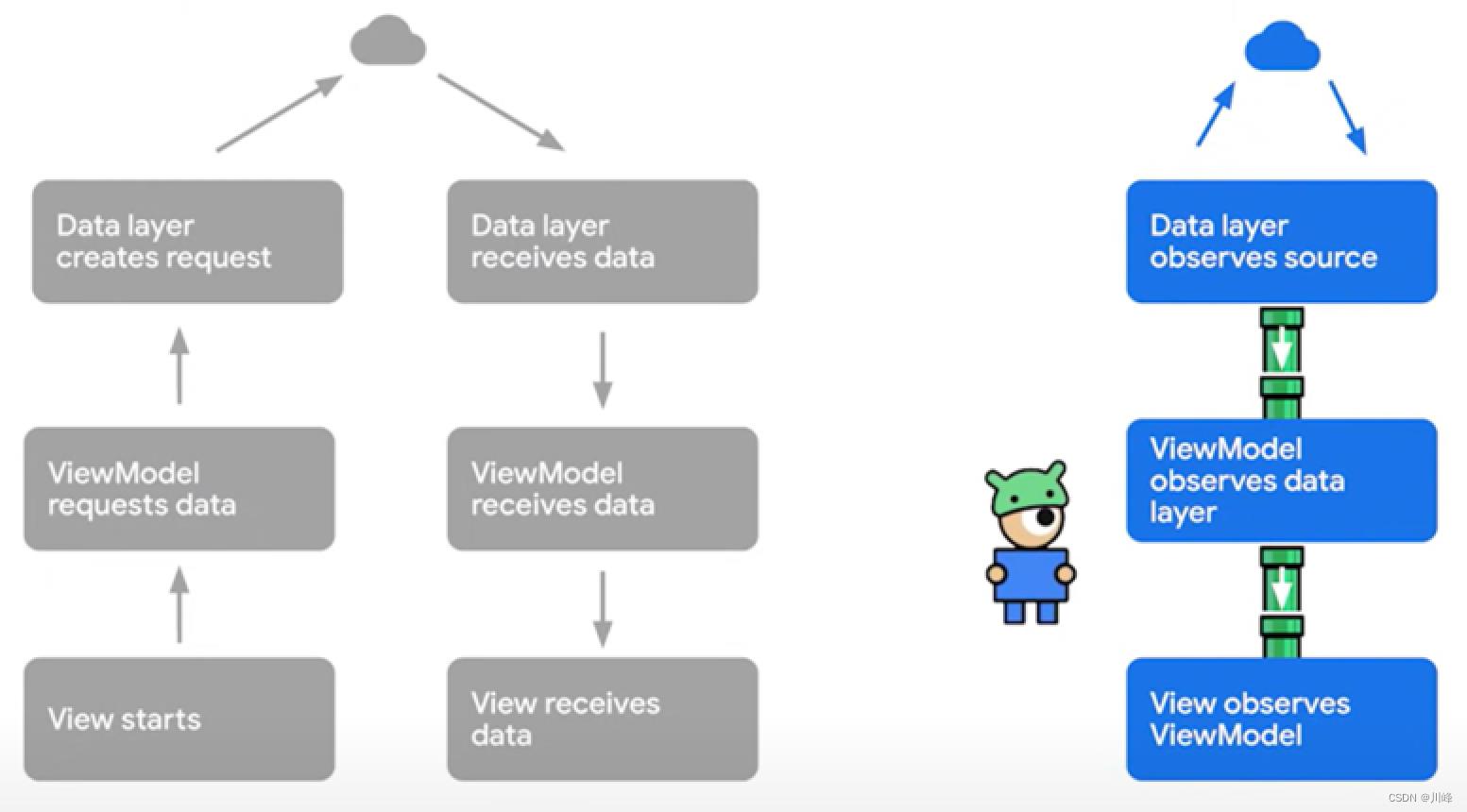
这样我们再也不用每次都走到湖边了。不管应用的数据源有多少个,我们只需要在不同的数据源之间架设好管道,然后将所有的管道用统一的管道相连,最终将管道的另一头连接到我们的view界面,然后就可以自动订阅数据的更新了!是不是很棒:

这样做其实是在数据源和最终的显示界面搭建了一条单向的管道流:

下面来回顾一下Flow的Api加深对这个问题的理解:

一个Flow流的两端分别对应生产者和消费者,因此Flow是生产者-消费者模式。

在Flow中,操作在同一个协程中按顺序执行。

我们可以通过map操作符对流进行变换,将原始数据转换为适合UI界面展示的Model实体类,这就好比在一节管道之后另外又接了一节管道。
这些操作符变换的地方都属于管道的上游,而接受数据的地方则属于管道的下游:


通过catch操作符,可以在需要时抛出异常或者发射新的数据:

最后,我们可以通过Flow.collect收集数据,这就像在管道的终端拧开水龙头一样:

当然,我们可以多次拧开水龙头,每次拧开时,都会有水流出来,因此我们可以多次调用Flow.collect,每次都会产生新的数据流:

另外需要注意的一点是,Flow.collect是一个挂起函数,因此它需要在一个协程当体中调用。
当然在很多时候,我们不需要自己亲自动手创建Flow,如果你使用官方推荐的一些Jetpack组件库或者一些著名的三方库,它们在生产数据时会为你自动输出一个Flow对象供你使用,比如下面这些:

Don’t waste resources
好了,我们现在可以使用流了,那么到此故事就完了吗? 并没有,回到前面湖泊的比喻中,在费了九牛二虎之力安装好管道之后,小帅深知这水来之不易,于是他决定节约用水,因此小帅总是在需要的时候才会打开水龙头(比如在刷牙时),而不是一直开着水龙头让水一直流,在小帅不需要水的时候(比如睡觉时)他会关闭水龙头。这个道理非常的简单好理解,同样地,回到我们的应用中,如果某些信息不会在屏幕上面显示,界面就不应该从数据流中收集此类信息。(比如应用被用户切到后台)

需要注意的是,通过lifecycleScope.launch或者lifecycleScope.launchWhenXXX方法中对Flow进行collect的方式都是不安全的做法:

那么如何正确的做到这一点呢,官方为我们提供了以下几种方案:

使用repeatOnLifecycle会只在onStat-onStop之间收集数据,而在onStop-onStart之间则会停止收集数据:

下一个问题:为什么会有StateFlow?
要理解这个问题,首先得考虑一下下面这个场景:

当我们旋转屏幕时,Activity可能被销毁重建,而ViewModel却能够得以保留,假如我们通过ViewModel直接暴露出Flow,而Flow是一种冷流,每次首次收集冷数据流时,它都会重启,那么下面的代码会被重复调用:

因此,我们需要的是某种缓存区,无论重新创建多少次,这种缓冲区都可以保存数据,并在多个收集器之间共享数据。StateFlow正是为此用途而设计的。

回到我们湖泊的比喻当中,StateFlow就好比一个水箱,它可以暂时保存很多的水。
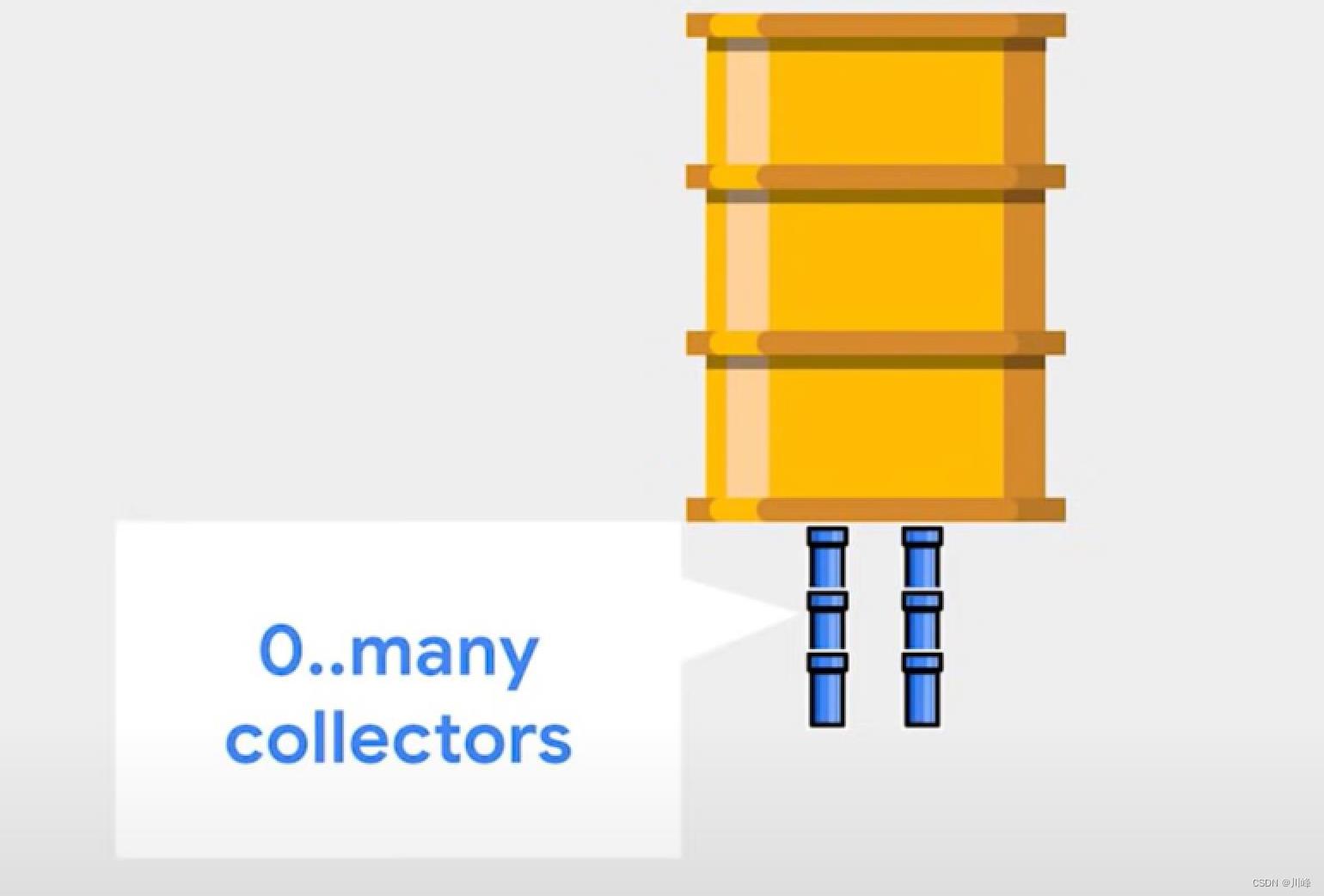
即使没有收集器,它也能保存数据。

您可以从中收集很多次,并随时根据需要更新它的值。

您可以将任何的普通数据流转换成一个StateFlow,这样做将使用StateFlow来接收上游数据流的所有更新,并存储最新的值。而且收集器的数量可以是0个或多个,因此它非常适合和ViewModel一起使用。
以下是将任意Flow转换成一个StateFlow的方法:

这里通过调用stateIn方法即可返回一个StateFlow对象,stateIn有三个参数,其中initialValue和scope非常好理解,分别表示初始值和所处的协程作用域,但是这里的 started = WhileSubscribed(5000) 是什么含义呢?要理解它又得先考虑以下的场景:

其中第一个场景是前面提到过的Activity在屏幕旋转或者配置更改时被销毁随后在短时间内重建,第二个场景是用户导航到桌面,但是此时并没有关闭应用,只是被切到后台。
在旋转的场景中,我们不希望重启任何数据流以便尽可能快地完成过渡,但是在导航到桌面的场景中,我们希望停止所有数据流,以节省电量和其他资源。那么如何正确的判断不同的场景呢?我们通过设置超时来做到这一点,当停止收集StateFlow时,不会立即停止所有上游数据流,而是会等待一段时间,比如5秒钟,如果在超时前再次收集数据流,则不会取消上游数据流。
这就是 WhileSubscribed(5000) 的作用:


下图展示了当按下Home键应用转到后台的过程中会发生什么:
当按下Home键之前,视图持续接受更新

当超过超时时间之后,上游数据流被取消

只有当用户再次打开应用时,如果发生这种情况,上游数据流会自动重启

而在旋转的场景中,视图只停止了很短的时间,因此StateFlow不会重启,并保持所有上游数据流都处于活动状态,就像什么都没发生一样,可即时向用户呈现旋转后的屏幕。

因此官方推荐我们使用StateFlow通过ViewModel来公开数据流:

关于Flow的单元测试
单元测试关键就在于两个字“模拟”,不管你在测试什么数据流,都会有一个数据来源
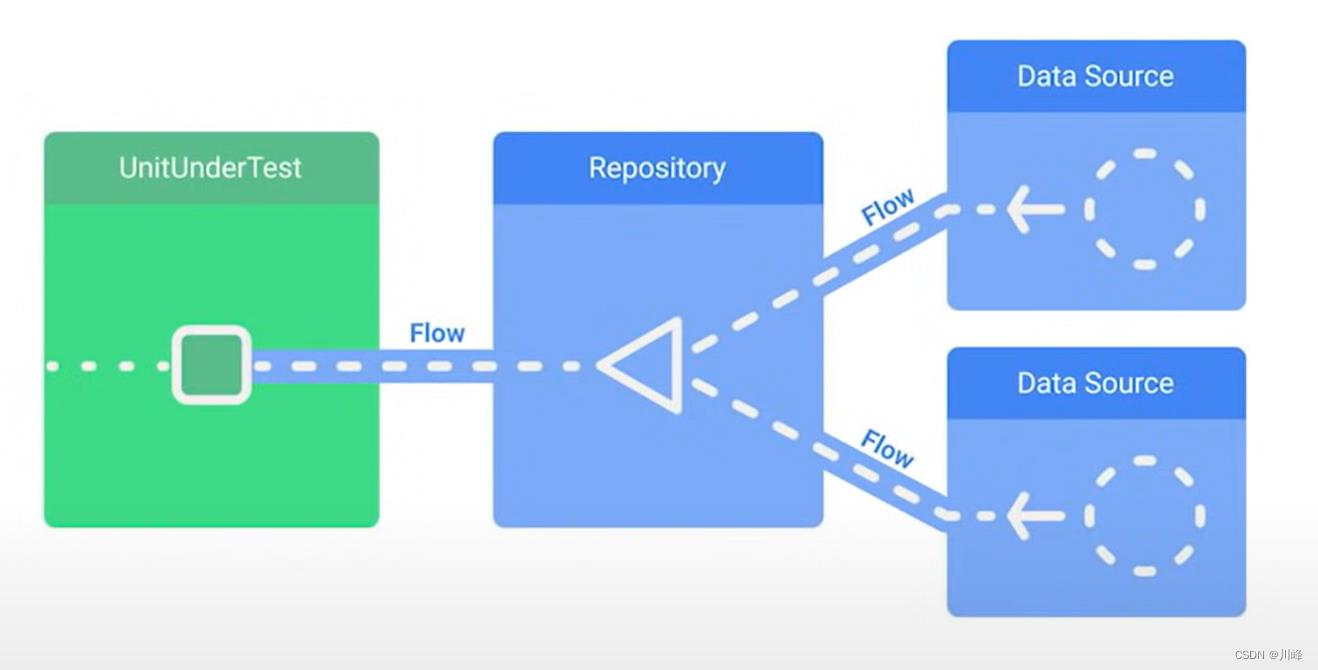
如果是上图这种情况,如果受测单元接受一个产生流的Respository,我们只需将输入受测单元的那个Repository变成FakeRepository就可以:

如果受测单元本身就是一个产生流的Respository,那么只需将输入Respository的DataSource变成FakeDataSource:

然后通过first()或take()这样的方法取到对应的模拟数据项进行验证


以上是关于深入理解Kotlin协程Google的工程师们是这样理解Flow的?的主要内容,如果未能解决你的问题,请参考以下文章