知识蒸馏NST算法实战:使用CoatNet蒸馏ResNet18
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识蒸馏NST算法实战:使用CoatNet蒸馏ResNet18相关的知识,希望对你有一定的参考价值。
文章目录
摘要
复杂度的检测模型虽然可以取得SOTA的精度,但它们往往难以直接落地应用。模型压缩方法帮助模型在效率和精度之间进行折中。知识蒸馏是模型压缩的一种有效手段,它的核心思想是迫使轻量级的学生模型去学习教师模型提取到的知识,从而提高学生模型的性能。已有的知识蒸馏方法可以分别为三大类:
- 基于特征的(feature-based,例如VID、NST、FitNets、fine-grained feature imitation)
- 基于关系的(relation-based,例如IRG、Relational KD、CRD、similarity-preserving knowledge distillation)
- 基于响应的(response-based,例如Hinton的知识蒸馏开山之作)
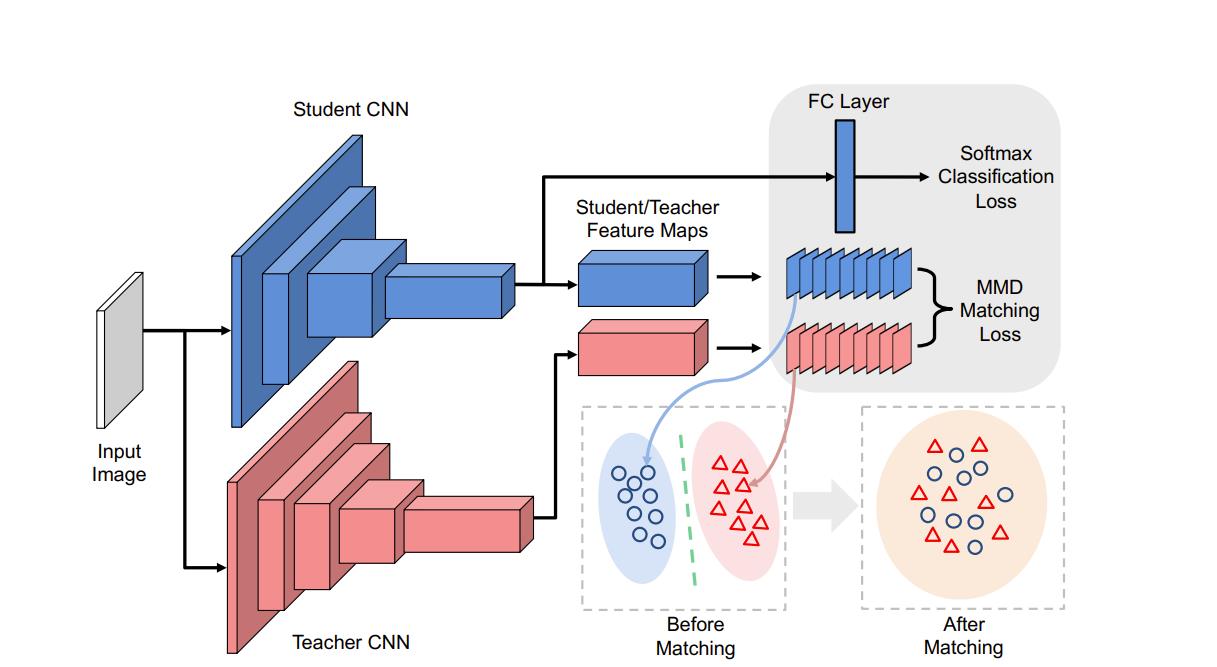
今天我们就尝试用基于关系特征的NST知识蒸馏算法完成这篇实战。NST蒸馏是对模型里面的的Block最后一层Feature做蒸馏,所以需要最后一层block的值。所以我们对模型要做修改来适应NST算法,并且为了使Teacher和Student的网络层之间的参数一致,我们这次选用CoatNet作为Teacher模型,选择ResNet18作为Student。
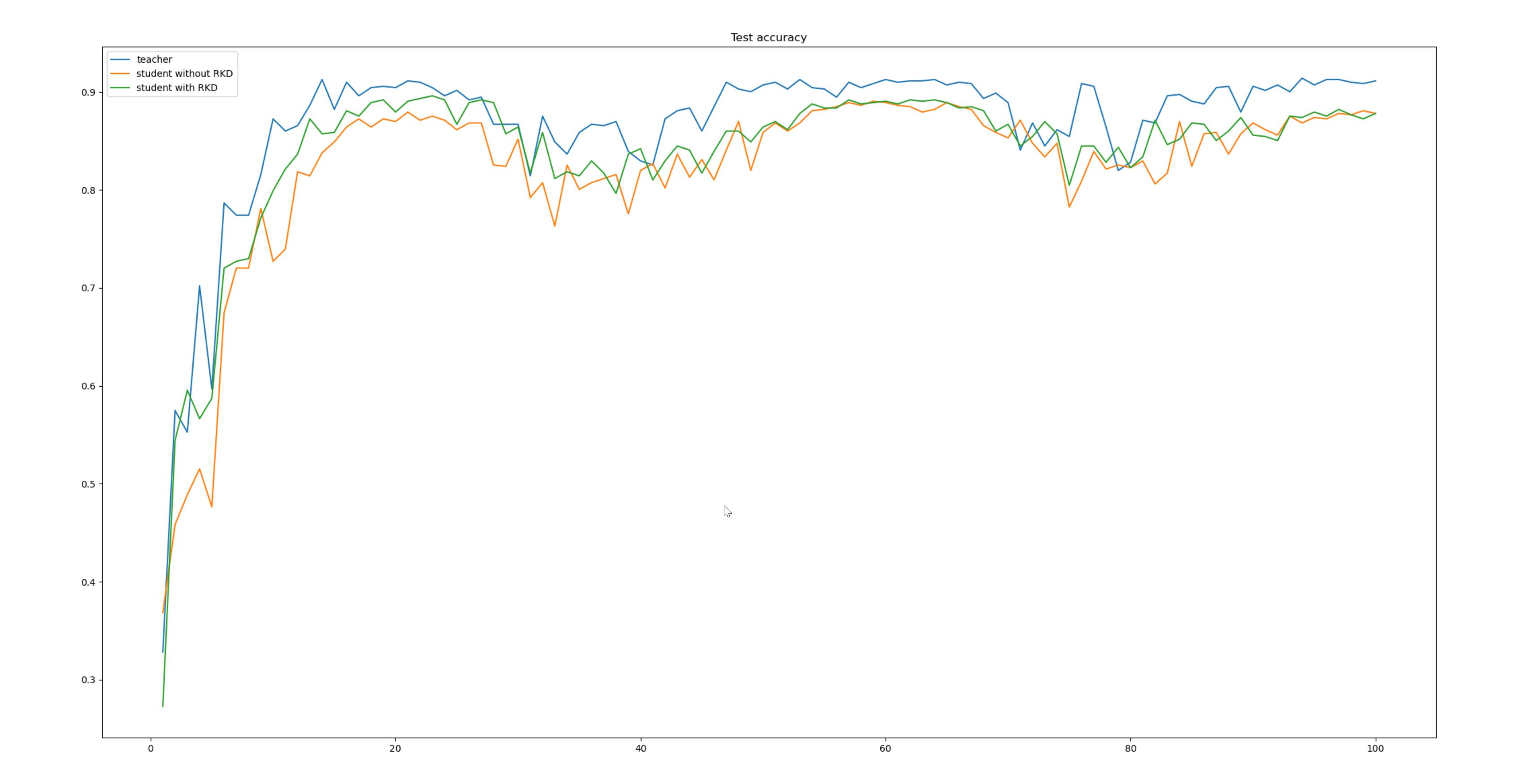
最终结论
先把结论说了吧! Teacher网络使用CoatNet的coatnet_2模型,Student网络使用ResNet18。如下表
| 网络 | epochs | ACC |
|---|---|---|
| CoatNet | 100 | 91% |
| ResNet18 | 100 | 89% |
| ResNet18 +NST | 100 | 90% |
模型
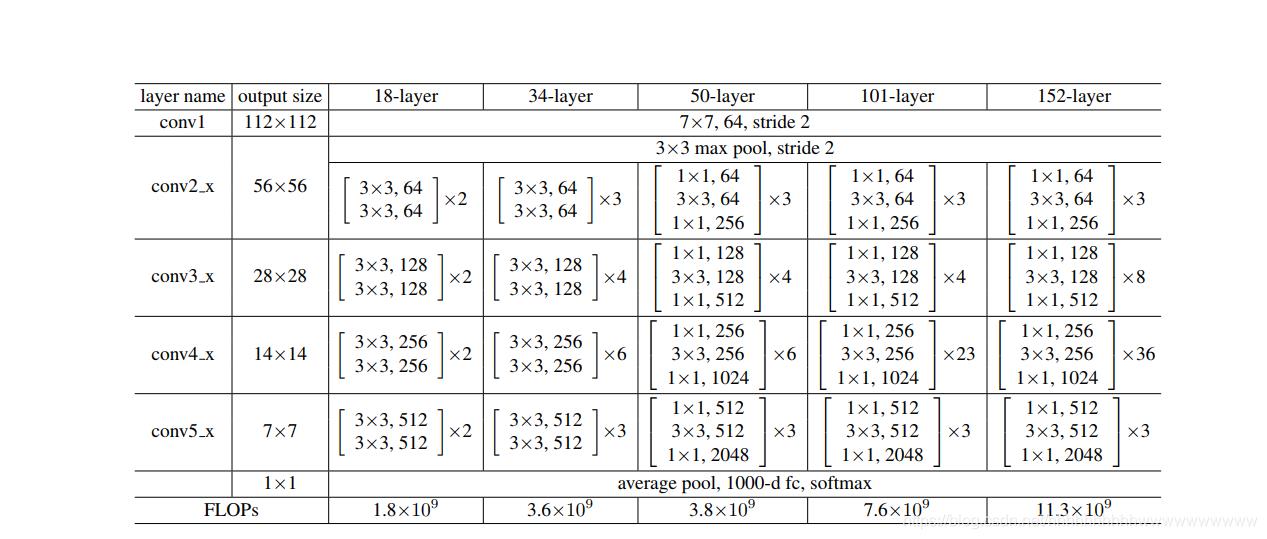
模型没有用pytorch官方自带的,而是参照以前总结的ResNet模型修改的。ResNet模型结构如下图:
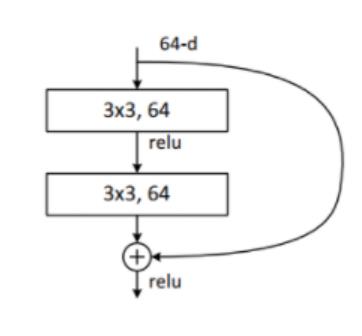
ResNet18, ResNet34
ResNet18, ResNet34模型的残差结构是一致的,结构如下:
代码如下:
resnet.py
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
# from torchsummary import summary
class ResidualBlock(nn.Module):
"""
实现子module: Residual Block
"""
def __init__(self, inchannel, outchannel, stride=1, shortcut=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.right = shortcut
def forward(self, x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet(nn.Module):
"""
实现主module:ResNet34
ResNet34包含多个layer,每个layer又包含多个Residual block
用子module来实现Residual block,用_make_layer函数来实现layer
"""
def __init__(self, blocks, num_classes=1000):
super(ResNet, self).__init__()
self.model_name = 'resnet34'
# 前几层: 图像转换
self.pre = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1))
# 重复的layer,分别有3,4,6,3个residual block
self.layer1 = self._make_layer(64, 64, blocks[0])
self.layer2 = self._make_layer(64, 128, blocks[1], stride=2)
self.layer3 = self._make_layer(128, 256, blocks[2], stride=2)
self.layer4 = self._make_layer(256, 512, blocks[3], stride=2)
# 分类用的全连接
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
"""
构建layer,包含多个residual block
"""
shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 1, stride, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU()
)
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
for i in range(1, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.pre(x)
l1_out = self.layer1(x)
l2_out = self.layer2(l1_out)
l3_out = self.layer3(l2_out)
l4_out = self.layer4(l3_out)
p_out = F.avg_pool2d(l4_out, 7)
fea = p_out.view(p_out.size(0), -1)
out=self.fc(fea)
return l1_out,l2_out,l3_out,l4_out,fea,out
def ResNet18():
return ResNet([2, 2, 2, 2])
def ResNet34():
return ResNet([3, 4, 6, 3])
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = ResNet34()
model.to(device)
# summary(model, (3, 224, 224))
主要修改了输出结果,将每个block的结果输出出来。
CoatNet
代码:
coatnet.py
import torch
import torch.nn as nn
from einops import rearrange
from einops.layers.torch import Rearrange
def conv_3x3_bn(inp, oup, image_size, downsample=False):
stride = 1 if downsample == False else 2
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.GELU()
)
class PreNorm(nn.Module):
def __init__(self, dim, fn, norm):
super().__init__()
self.norm = norm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class SE(nn.Module):
def __init__(self, inp, oup, expansion=0.25):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, int(inp * expansion), bias=False),
nn.GELU(),
nn.Linear(int(inp * expansion), oup, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class MBConv(nn.Module):
def __init__(self, inp, oup, image_size, downsample=False, expansion=4):
super().__init__()
self.downsample = downsample
stride = 1 if self.downsample == False else 2
hidden_dim = int(inp * expansion)
if self.downsample:
self.pool = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
if expansion == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride,
1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
# down-sample in the first conv
nn.Conv2d(inp, hidden_dim, 1, stride, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1,
groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
SE(inp, hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
self.conv = PreNorm(inp, self.conv, nn.BatchNorm2d)
def forward(self, x):
if self.downsample:
return self.proj(self.pool(x)) + self.conv(x)
else:
return x + self.conv(x)
class Attention(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == inp)
self.ih, self.iw = image_size
self.heads = heads
self.scale = dim_head ** -0.5
# parameter table of relative position bias
self.relative_bias_table = nn.Parameter(
torch.zeros((2 * self.ih - 1) * (2 * self.iw - 1), heads))
coords = torch.meshgrid((torch.arange(self.ih), torch.arange(self.iw)))
coords = torch.flatten(torch.stack(coords), 1)
relative_coords = coords[:, :, None] - coords[:, None, :]
relative_coords[0] += self.ih - 1
relative_coords[1] += self.iw - 1
relative_coords[0] *= 2 * self.iw - 1
relative_coords = rearrange(relative_coords, 'c h w -> h w c')
relative_index = relative_coords.sum(-1).flatten().unsqueeze(1)
self.register_buffer("relative_index", relative_index)
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(inp, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, oup),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(
t, 'b n (h d) -> b h n d', h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# Use "gather" for more efficiency on GPUs
relative_bias = self.relative_bias_table.gather(
0, self.relative_index.repeat(1, self.heads))
relative_bias = rearrange(
relative_bias, '(h w) c -> 1 c h w', h=self.ih*self.iw, w=self.ih*self.iw)
dots = dots + relative_bias
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out
class Transformer(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, downsample=False, dropout=0.):
super().__init__()
hidden_dim = int(inp * 4)
self.ih, self.iw = image_size
self.downsample = downsample
if self.downsample:
self.pool1 = nn.MaxPool2d(3, 2, 1)
self.pool2 = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
self.attn = Attention(inp, oup, image_size, heads, dim_head, dropout)
self.ff = FeedForward(oup, hidden_dim, dropout)
self.attn = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(inp, self.attn, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
self.ff = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(oup, self.ff, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
def forward(self, x