PostgreSQL Replication 101 - 故障转移
Posted DataFlow范式
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL Replication 101 - 故障转移相关的知识,希望对你有一定的参考价值。
众所周知,PostgreSQL 在国内的整体份额比不上 mysql/MariaDB,但是号称世界上功能最为强大(没有更强,只有更强)的开源数据库之一,它在国内近几年发展势头明显。在大数据时代的背景下,基于 PostgreSQL 的分布式数据库,比如 Greenplum、Citus 等也推动了 PostgreSQL 的发展,而且很多云厂商也支持 PostgreSQL 数据源。
另外,2019-10-03,PostgreSQL全球开发组发布 PostgreSQL 12 版本。PostgreSQL 12 在各方面都得到了加强,包括显著地提升查询性能,特别是对大数据集,总的空间利用率方面。
今天笔者想给大家普及一下 PostgreSQL 故障转移方面的内容,大部分内容整理自参考文章。虽然基于 PostgreSQL 的分布式高可用数据库的快速发展,但是不少场景下,还是需要使用原生的 PostgreSQL 数据库来服务应用,另外大多数情况又要实现读写分离,自然而然主从架构就不可避免了。既然引入主从方案,那么复制和故障转移就必须要考虑了。
101
正式开讲之前,闲聊一二,笔者对标题中的 101 含义初略解释一下,大部分读者应该都知道:
在美国很多大学里面,在某些学科中为第一年的第一门课程编号采用的数字就是 101。后来经过扩展延伸,xxx 101 就是指针对该 xxx 主题的新手的入门课程、书籍或教科书。
引入故障转移
Failover,即故障转移,我们可能都听说过无数次了。针对故障转移的话题,又会带来很多问题,比如:
什么是真正的故障转移
故障转移用来做什么
如何做好故障转移
...
何为故障转移
故障转移是系统即使发生某些故障也可以继续运行的能力。如果 primary 组件出现故障,则系统功能将由 secondary 组件承担。
就 PostgreSQL 而言,有多种工具可让我们实现一个对故障或失败有弹性的数据库集群。在 PostgreSQL 中本地提供的一种冗余机制是就是复制。PostgreSQL 10 中的新颖之处在于实现了逻辑复制。
何为复制
笔者在上面提到了复制,那么复制到底是什么呢?
如果用一句话来概括,复制就是在一个或多个数据库节点中复制并保持数据更新的过程。复制的概念中包含使用接收修改的主节点和复制修改的从节点。
复制分类
Synchronous Replication
同步复制,即使我们的主节点(master)丢失,也不会丢失数据,但是主节点中的提交必须等待从节点(slave)的确认,这可能会影响性能。
Asynchronous Replication
异步复制,如果丢失主节点,则可能会丢失数据。如果事件发生时由于某种原因未更新副本,则尚未复制的信息可能会丢失。
Physical Replication
物理复制,其实就是复制磁盘数据块。
Logical Replication
逻辑复制:流式传输数据更改。
Warm Standby Slaves
不支持连接。
Hot Standby Slaves
支持只读连接,对分析报告或查询非常有用。
故障转移作用
故障转移有几种可能的用途。让我们看一些例子。
数据迁移
如果要通过最大程度地减少停机时间从一个数据中心迁移到另一个数据中心,则可以使用故障转移。
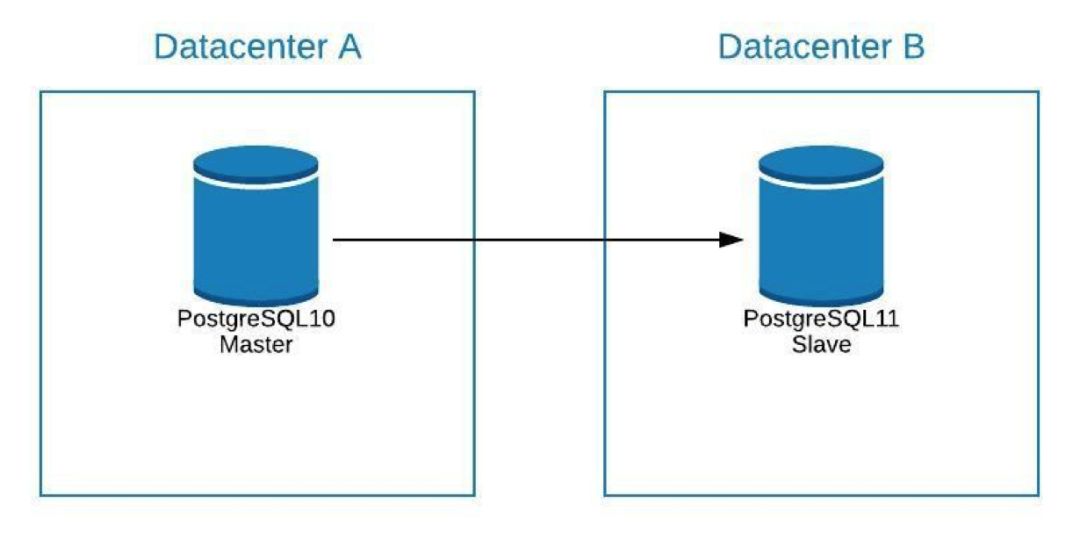
假设我们的 master 位于数据中心 A 中,并且我们希望将系统迁移到数据中心 B 中。
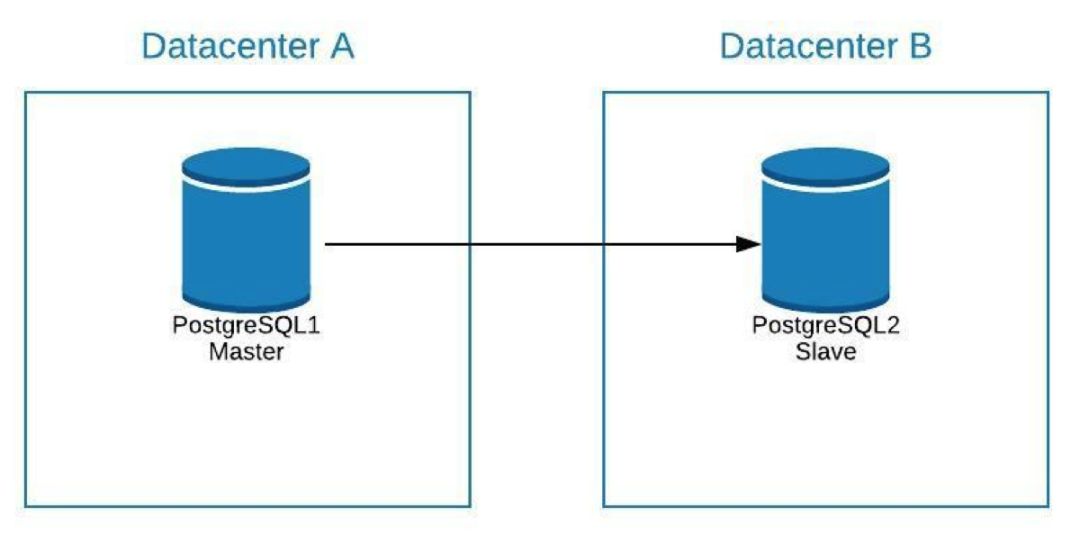
我们可以在数据中心 B 中创建一个 slave 副本。同步之后,我们必须先停止系统,将副本升级到新的 master 并进行故障转移,然后再将系统指向数据中心 B 中的新 master。
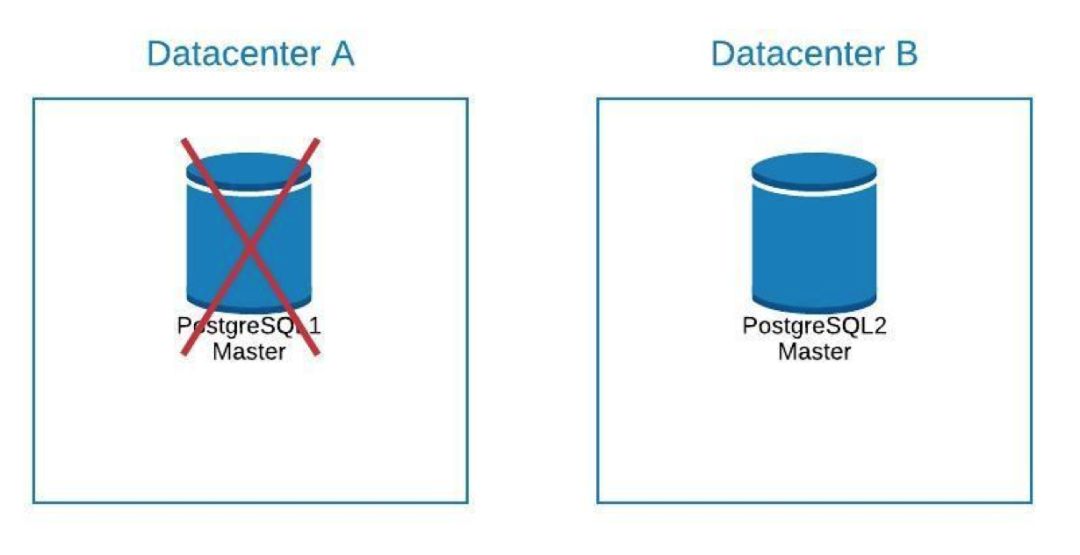
故障转移不仅与数据库有关,而且与应用程序有关。
应用程序如何知道要连接到哪个数据库?我们是不是要修改应用程序的数据库连接配置呢?
当然不需要修改应用程序,因为如果修改应用程序的数据库连接配置只会延长服务的停机时间。因此,我们可以配置一个负载平衡器,以便当关闭 master 时,它将自动指向要升级的下一个数据库服务(slave 升级为新 master)。
另一个选择是使用 DNS。通过在新的数据中心中提升 master 副本,我们可以直接修改指向 master 副本的主机名的 IP 地址。通过这种方式,我们可以避免修改应用程序,虽然它不能自动完成,但是如果不想实现负载平衡器,它也是一种可行的替代方法。
但是使用单个负载均衡器的实例并不好,因为它会成为单点故障。因此,我们可以使用 keepalived 等服务为负载均衡器本身实现故障转移。这样,如果我们的 primary 负载平衡器有问题,keepalived 负责将 IP 迁移到我们的 secondary 负载平衡器,所有的工作都继续透明地进行正常工作。
维护
如果必须对 PostgreSQL 数据库的 master 执行维护操作,则此时可以提升 PostgreSQL 数据库的 slave 为 新的 master,然后执行任务,并在旧的 master 上重构一个 slave。
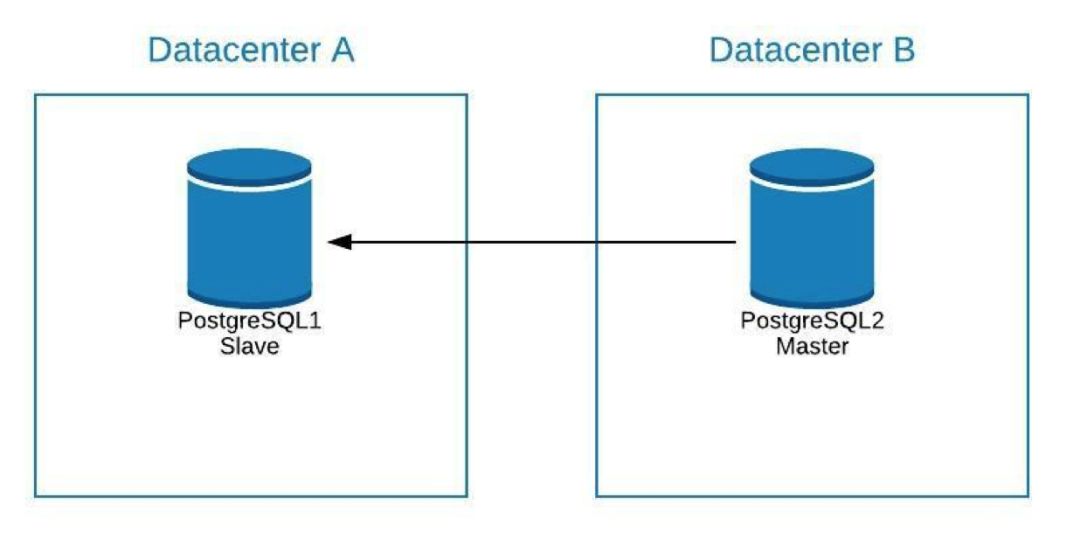
之后我们可以重新提升旧的 master ,重复 slave 的重建过程,回到最初的状态。
通过这种方式,我们可以在服务器上工作,而不必冒离线或在执行维护时丢失信息的风险。
升级
PostgreSQL 11 发布一年多了,我们可以从 PostgreSQL 10 使用逻辑复制进行升级。升级的步骤与迁移到新的数据中心相同,只是 slave 位于 PostgreSQL 11 中而已。
现实问题
当 master 数据库出现问题时,故障转移的最重要功能是最大程度地减少停机时间或避免信息丢失。
如果由于某种原因我们丢失了 master 数据库,则可以执行故障转移,将 slave 提升为新的 master,并保持系统运行。
但是 PostgreSQL 并没有为用户提供任何自动化解决方案。不过,我们可以手动执行操作,也可以通过脚本或外部工具自动执行操作。
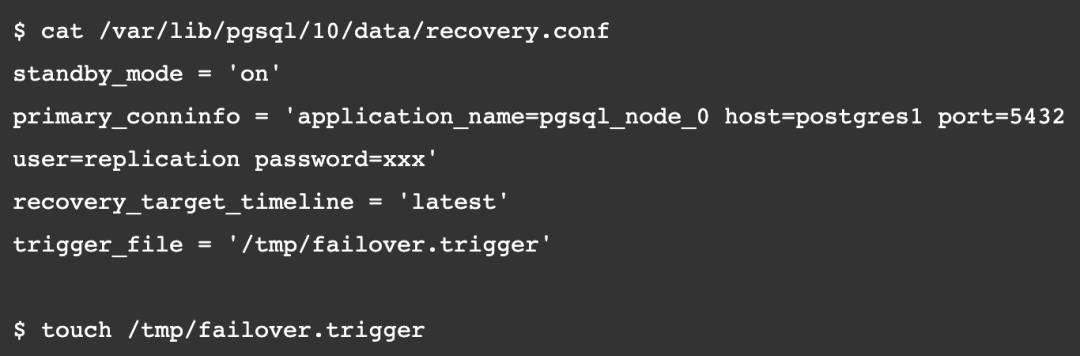
PostgreSQL 本身提供了命令,用于提升 slave 为 master:
执行 pg_ctl 提升 slave 为 master 命令
$ pg_ctl promote -D /var/lib/pgsql/10/data/
waiting for server to promote.... done
server promoted
创建一个文件 trigger_file,必须将其添加到数据目录的 recovery.conf 中
为了实施故障转移策略,我们需要对其进行规划,并在不同的故障情况下进行全面测试。由于故障可能以不同的方式发生,因此该解决方案在理想情况下应适用于大多数常见方案。如果读者正在寻找一种自动化的方法,可以看看 ClusterControl 提供什么解决方案。
故障转移工具
ClusterControl 具有许多与 PostgreSQL 复制和自动故障转移相关的功能。但是 ClusterControl 大部分功能都是商业收费的。不过,我们可以借鉴 ClusterControl 工具的思路来实现一些类似的功能。

ClusterControl Community Edition 是一个免费使用的多合一数据库管理系统,它可以部署和监视 MySQL、MariaDB、Percona、MongoDB、PostgreSQL 和 Galera Cluster 等顶级开源数据库技术。
添加 Slave
如果我们想在另一个数据中心中添加一个 slave,以备不时之需或迁移现有的系统,我们可以转到 Cluster Actions,然后选择 Add Replication Slave。
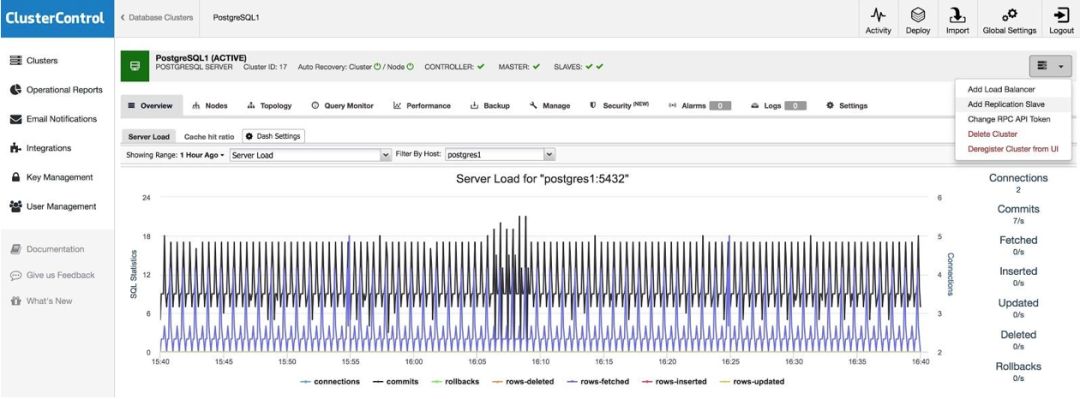
我们需要输入一些基本信息,例如 IP 或主机名、数据目录(可选)、同步或异步的 slave。在几十秒内,就可以启动并运行 slave。
在使用另一个数据中心的情况下,我们建议创建一个异步 slave,否则延迟会严重影响性能。

手动故障转移
使用 ClusterControl,可以手动或自动完成故障转移。
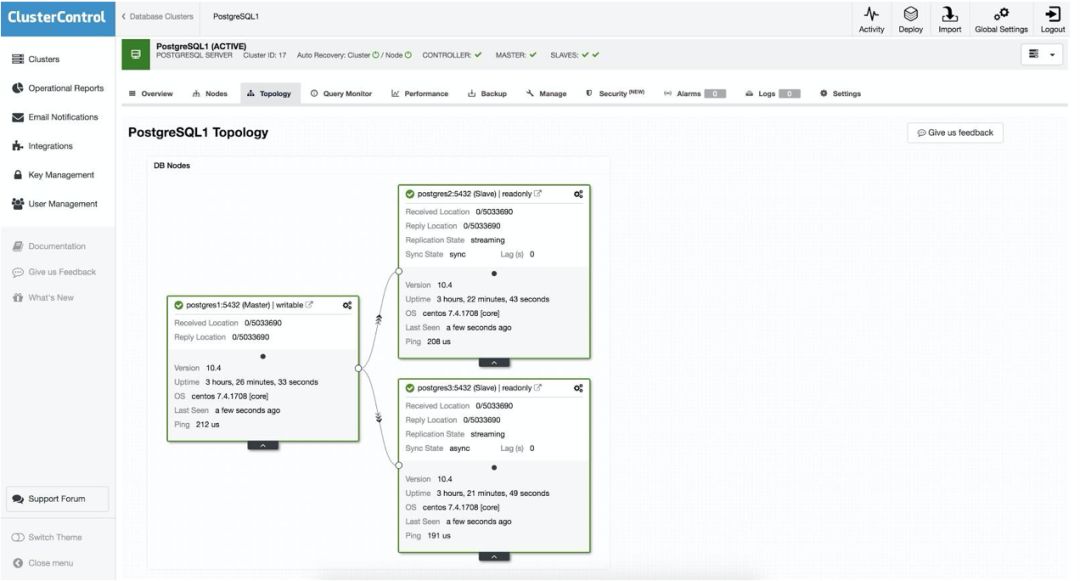
要执行手动故障转移,请转到 ClusterControl-> Select Cluster-> Nodes,然后在其中一个 slave 的 Action Node 中,选择 Promote Slave。这样,几秒钟后,slave 就成为 master,而以前的 master 变成了 slave。
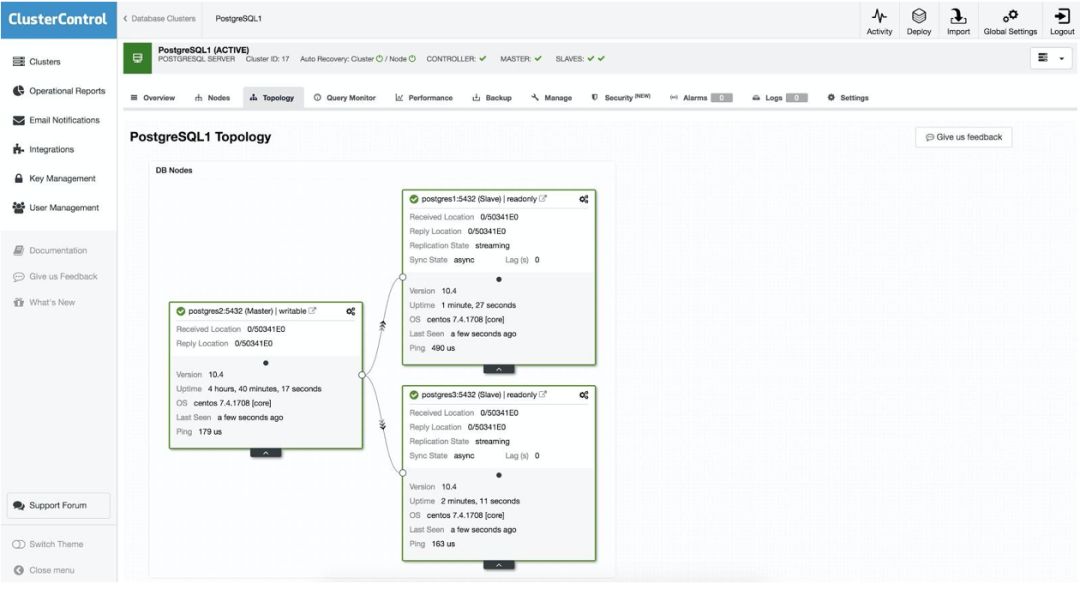
上面的内容对于我们之前看到的迁移、维护和升级任务很有用。
自动故障转移
在自动故障转移的情况下,ClusterControl 会检测到 master 中的故障,并将具有最新数据的 slave 升级为新的 master。它还适用于其余的 slaves,以使它们从新的 master 复制。
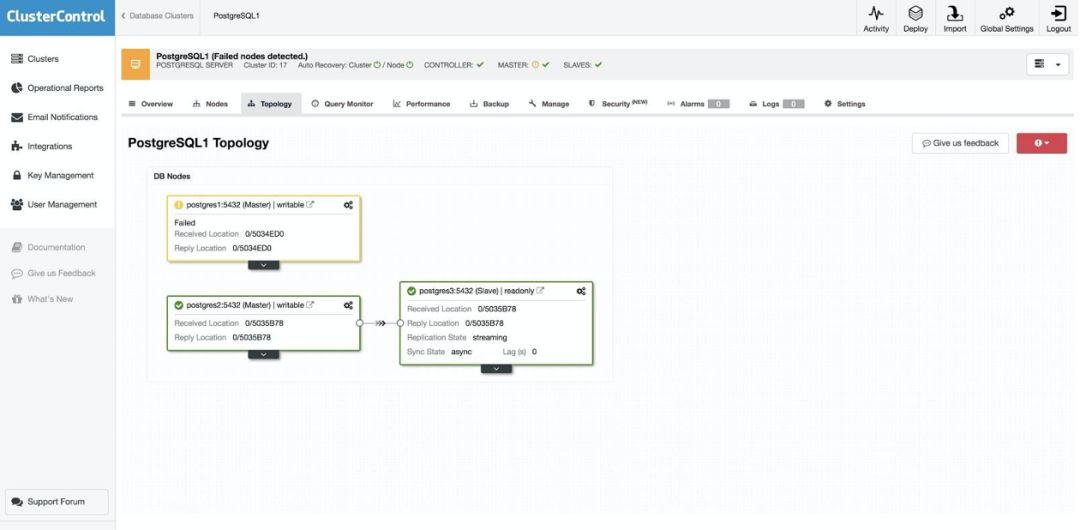
启用 Autorecovery 选项后,ClusterControl 将执行自动故障转移并通知管理员出现了问题。通过这种方式,数据库系统可以在几秒钟内恢复,而无需人工干预。
另外,ClusterControl 可以配置白名单/黑名单,以定义在决定主要候选角色时应该如何考虑服务器。
从上述配置可用的那些服务器中,ClusterControl 将选择最高级的 slave,为此使用 pgcurrentxloglocation(PostgreSQL 9+)或 pgcurrentwallsn(PostgreSQL 10+),具体取决于使用的数据库版本。
为了避免一些常见的错误,ClusterControl 还对故障转移过程执行了一些检查。比如,如果我们设法恢复失败的旧 master,则不会作为 master 或 slave 将其自动重新引入集群,我们需要手动进行,这样可以避免发生故障时 slave(被提升的)被延迟的情况,从而避免数据丢失或不一致的可能性。
另外,如果故障转移失败,则无需进行进一步尝试,需要手动干预来分析问题并执行相应的操作。这是为了避免 ClusterControl 作为高可用性管理器尝试提升下一个 slave 和再下一个 slave 的情况。这样可能会存在问题,我们不想通过尝试多次故障转移使情况变得更糟。
负载均衡器
如前所述,负载平衡器是考虑故障转移的重要工具,尤其是当我们要在数据库拓扑中使用自动故障转移时。
为了使故障转移对用户和应用程序都透明,我们需要一个中间的组件,我们可以使用 HAProxy + Keepalived。
HAProxy
HAProxy 是一种负载均衡器,可将流量从一个来源分发到一个或多个目的地,并可以为此任务定义特定的规则或协议。如果任何目的地停止响应,则将其标记为 offline,并将流量发送到其余可用目的地。这样可以防止将流量发送到不可访问的目的地,并通过将其定向到有效目的地来防止流量丢失。
Keepalived
Keepalived 允许在 active/passive 服务器组中配置虚拟 IP。该虚拟 IP 被分配给 active 的 Primary 服务器。如果该服务器发生故障,则 IP 将自动迁移到发现是 passive 的 Secondary 服务器,从而使其能够以透明的方式继续为我们的系统使用相同的 IP。
为了使用 ClusterControl 实现此解决方案,和添加 slave 类似,转到 Cluster Actions,然后选择 Add Load Balancer。
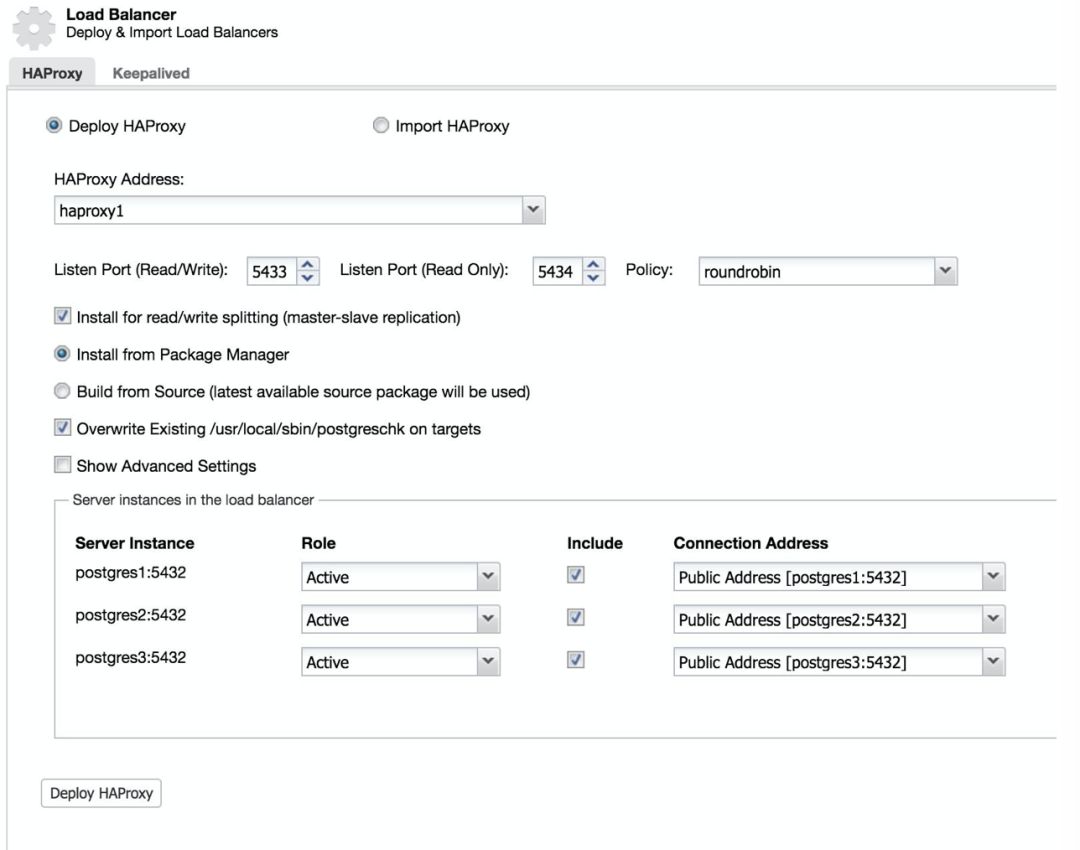
我们添加了新的负载均衡器的信息以及配置策略。如果要为我们的负载均衡器实施故障转移,则必须至少配置两个实例。
然后,我们可以配置 Keepalived(选择 Cluster -> Manage -> Load Balancer -> Keepalived):

完成后,整个架构拓扑如下:
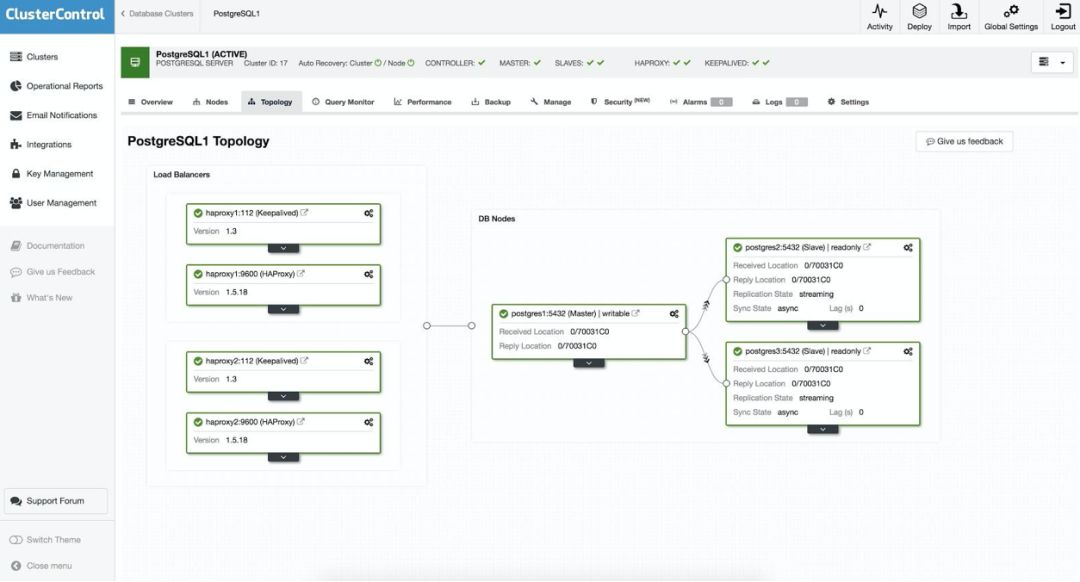
HAProxy 配置两个不同的端口,一个为读写端口,另一个为只读端口。
在读写端口中,我们的 master 处于 online 状态,其余节点处于 offline 状态。在只读端口中,master 和 slave 同时处于 online 状态。这样,我们可以平衡节点之间的读取流量。写入时,将使用读写端口,该端口指向 master。
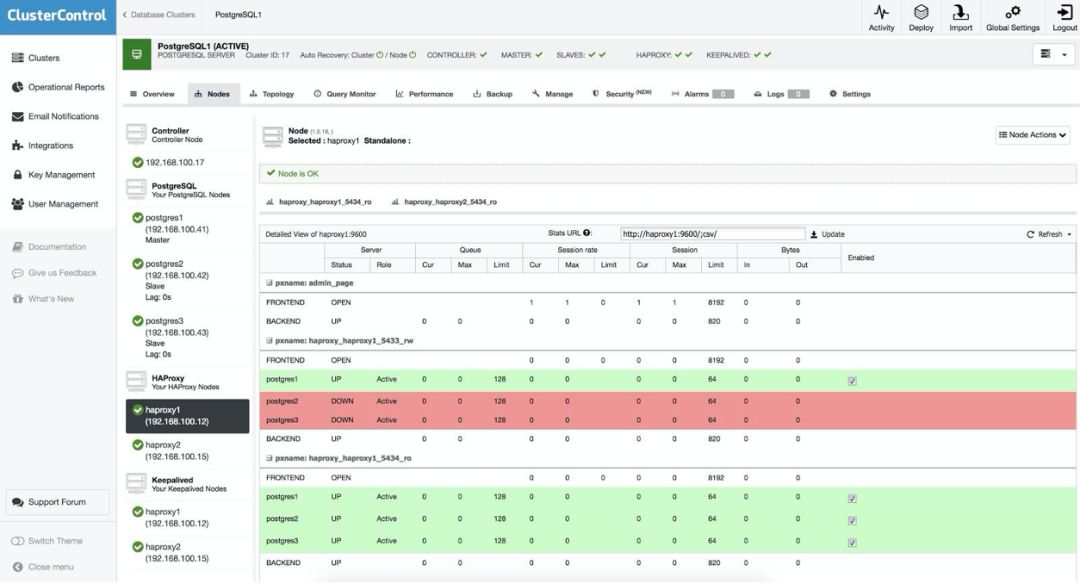
当 HAProxy 检测到我们的一个节点(master 或 slave)不可访问时,它将自动将其标记为 offline。HAProxy 将不会向其发送任何流量。此检查是在部署时由 ClusterControl 配置的运行状况健康检查脚本完成的,检查包括这些实例是否已启动、是否正在恢复还是只读状态。
当 ClusterControl 将一个 slave 升级为 master 时,我们的 HAProxy 将旧的 master 标记为 offline,并将升级后的节点置于 online 状态(在读写端口中)。这样,应用系统将继续正常运行。
如果 active 的 HAProxy(为其分配了与系统连接的虚拟 IP 地址)失败,则 Keepalived 会自动将该 IP 迁移到 passive 的 HAProxy,这意味着系统随后能够继续正常运行。
结论
正如上面我们所见,故障转移是任何企业级生产数据库的基本组成部分。在执行常规维护任务或迁移时,此功能非常有用。
虽然 ClusterControl 大部分核心功能都是付费的,但是本身所使用的一些技术都是开源的,并且也很成熟,值得借鉴。
最后,笔者希望本篇文章给大家更多的思路去构建满足自身需求的自动化故障转移策略。
参考
https://severalnines.com/database-blog/failover-postgresql-replication-101
以上是关于PostgreSQL Replication 101 - 故障转移的主要内容,如果未能解决你的问题,请参考以下文章