MongoDB内部的存储原理
Posted cui_yonghua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB内部的存储原理相关的知识,希望对你有一定的参考价值。
基础篇(能解决工作中80%的问题):
进阶篇:
其它:
存储引擎
本文介绍默认存储引擎WiredTiger
WiredTiger架构
WiredTiger的写操作会先写入Cache,并持久化到WAL(Write ahead log),每60s会做一次Checkpoint,将当前的数据持久化,每,产生一个新的快照。Wiredtiger连接初始化时,首先将数据恢复至最新的快照状态,然后根据Checkpoint恢复数据,以保证存储可靠性
btree与b+tree
虽然遍历数据的查询是相对常见的,但是 MongoDB 认为查询单个数据记录远比遍历数据更加常见,由于 B 树的非叶结点也可以存储数据,所以 查询一条数据所需要的平均随机 IO 次数会比 B+ 树少,使用 B 树的 MongoDB 在类似场景中的查询速度就会比 mysql 快。
这里并不是说 MongoDB 并不能对数据进行遍历,我们在 MongoDB 中也可以使用范围来查询一批满足对应条件的记录,只是需要的时间会比 MySQL 长一些。MySQL 认为遍历数据的查询是常见的,所以它选择 B+ 树作为底层数据结构
cache
内部缓存和文件系统缓存,默认情况下内部缓存取50%(RAM-1 GB)或256M较大者,文件系统缓存使用所有当前可用的RAM。
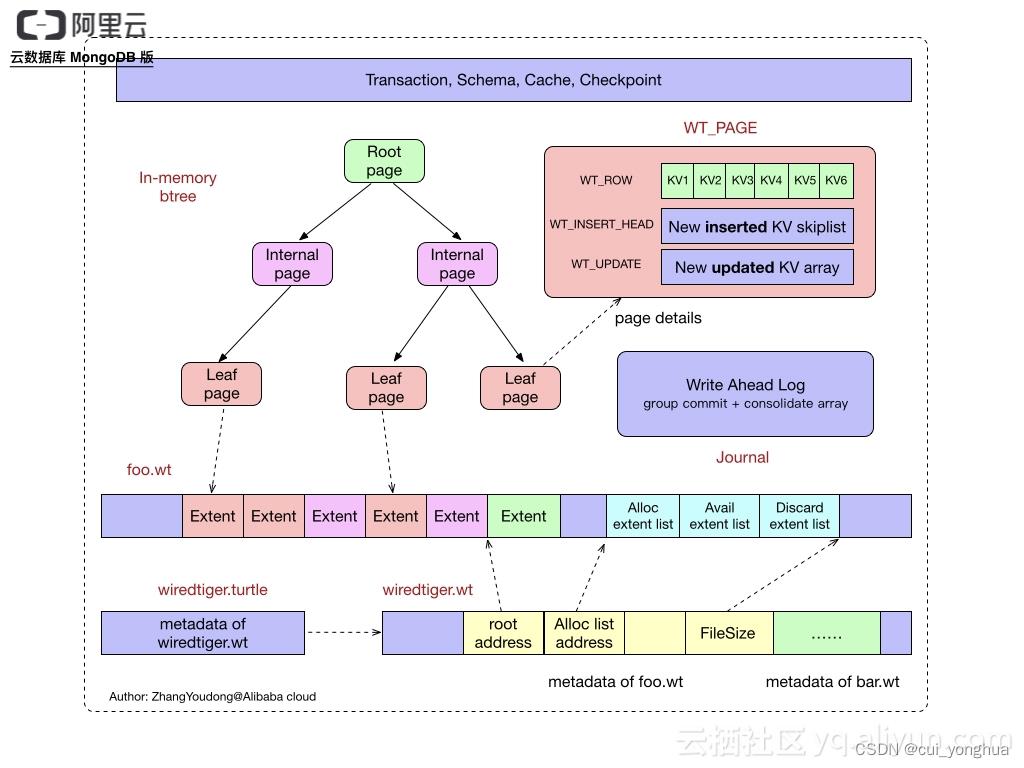
Wiredtiger的Cache采用Btree的方式组织,每个Btree节点为一个page,root page是btree的根节点,internal page是btree的中间索引节点,leaf page是真正存储数据的叶子节点;btree的数据以page为单位按需从磁盘加载或写入磁盘,btree的每个page以文件里的extent形式(由文件offset + size标识)存储
page
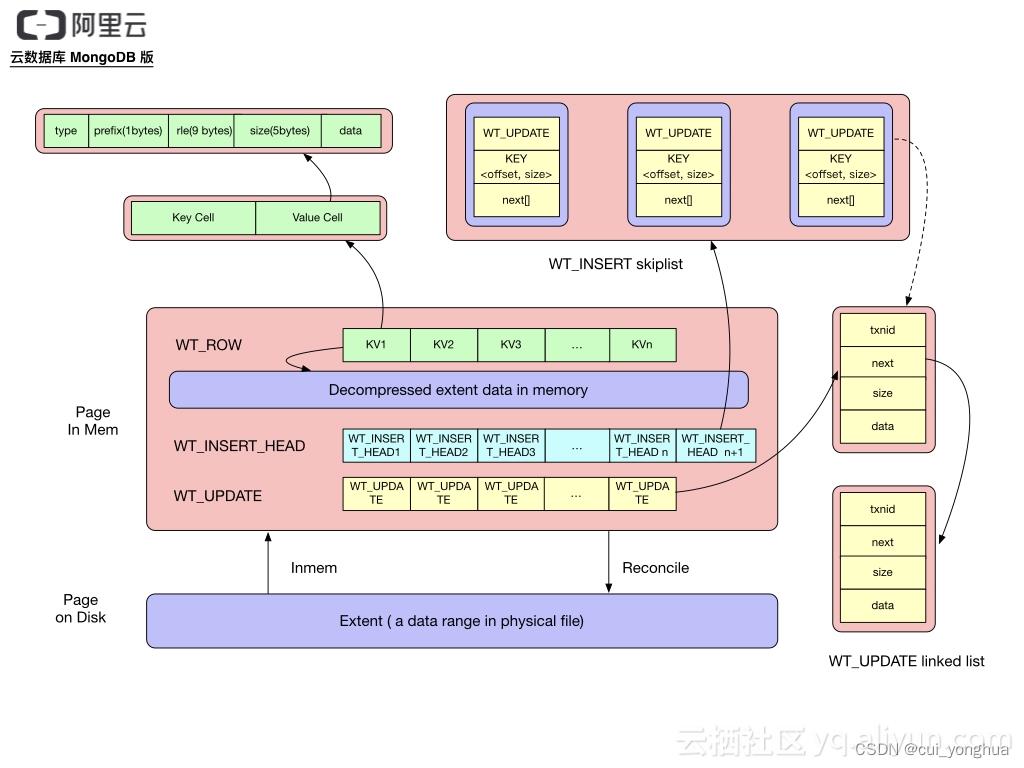
ROW_ARRAY: 每个数组单元(wt_row)存储的是这个 kv row 在存储在磁盘上的 page kv cell 行集合数据缓冲区偏移的位置和编码方式(这个位置和编码方式在 WT 上定义成一个 wt_cell 对象),通过这个信息偏移位置信息就可以访问到这一样在缓冲区中的 K/V 内容值
ROW_UPDATE_ARRAY: 一个 mvcc list 对象,mvcc_list 与 wt_row 是一一对应的,mvcc list 当中存储对 wt_row 修改的值,修改的值包括值更新和值删除,是一个无锁单向链表
写操作
- 遍历btree,找到需要更新的page
- 如果cache中没有对应的page,会从磁盘中加载page,键值对存入WT_ROW
- 如果是insert操作,更新WT_INSERT,如果是update/delete操作,更新WT_UPDATE
- 如果需要,将操作记录写入journal
我们通过一个实例来说明:
假如一个 page 存储了一个 [0,100] 的 key 范围,磁盘上原来存储的行 key=2, 10 ,20, 30 , 50, 80, 90,他们的值分别是value = 102, 110, 120, 130, 150, 180, 190。
在 page 数据从磁盘读到内存后,分别对 key=2 的 value 进行了两次修改,两次修改的值是分别 402,502。对 key = 20 ,50 的 value 做了一次修改,修改后的 value = 122, 155,后有分配 insert 了新的 key = 3,5, 41, 99,value = 203,205,241,299。
那么在内存中的 page 就是如下图组织数据的:
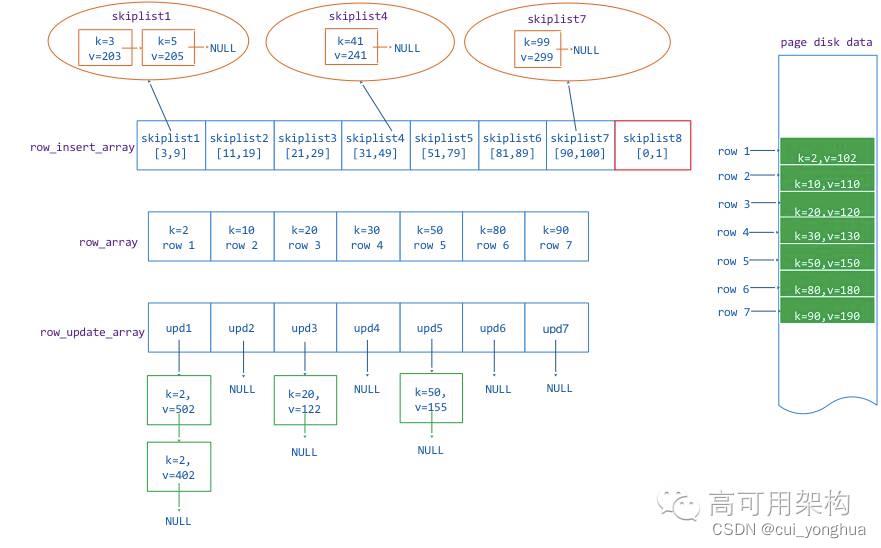
相邻的两 wt_row 之间可能不是连续的,他们之间可以插入新的单元,例如 row1(key = 2) 和 row2(key=10) 可以插入 3 和 5,这两个 row 之间需要有一个排序的数据结构(WT用 skiplist 数据结构)来存储插入的 K/V,就需要一个 skiplist 对象数组 page_insert_array与row array对应。这里需要说明的是 图6 当中红色框当中的 skiplist8,它是用于存储 row1(key=2) 范围之前的 insert 数据,图中如果有 key =1 的数据 insert,那么这个数据会新增到 skiplist8 当中。
那么图中row与 insert skiplist 的对应关系就是:
- row1 之前的范围对应 insert 是 skiplist8
- row1 和 row2之间对应的 insert 是 skiplist1
- row2 和 row3之间对应的 insert 是 skiplist3
- …
- row7 之后的范围对应的 insert 是 skiplist7
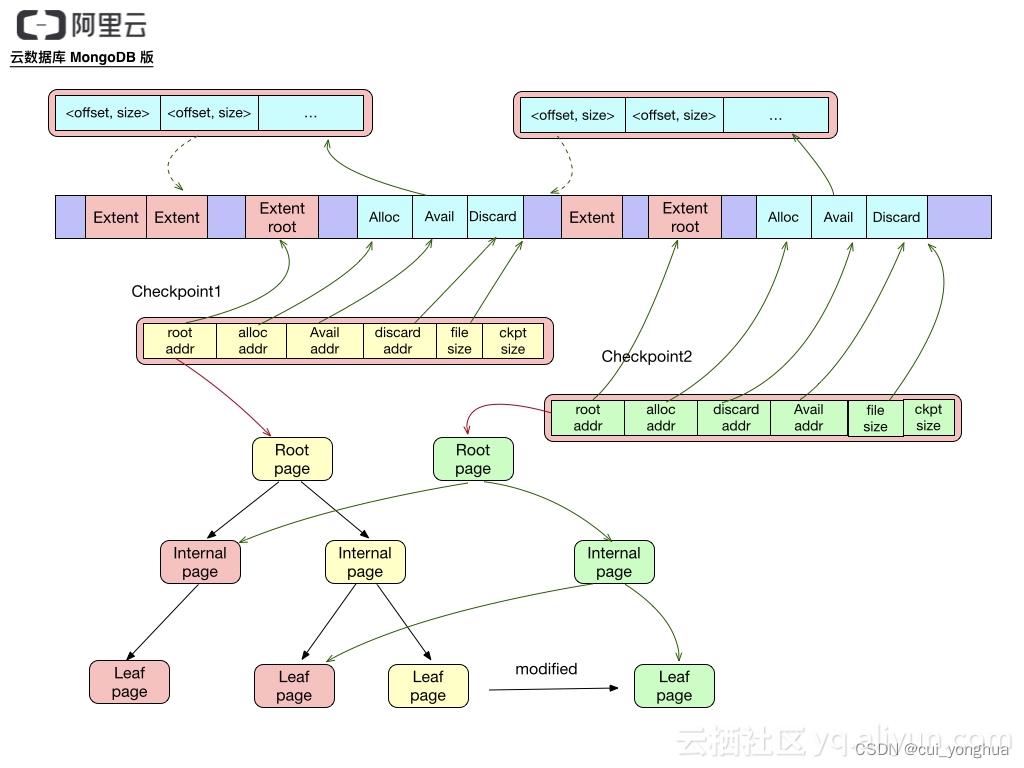
checkpoint
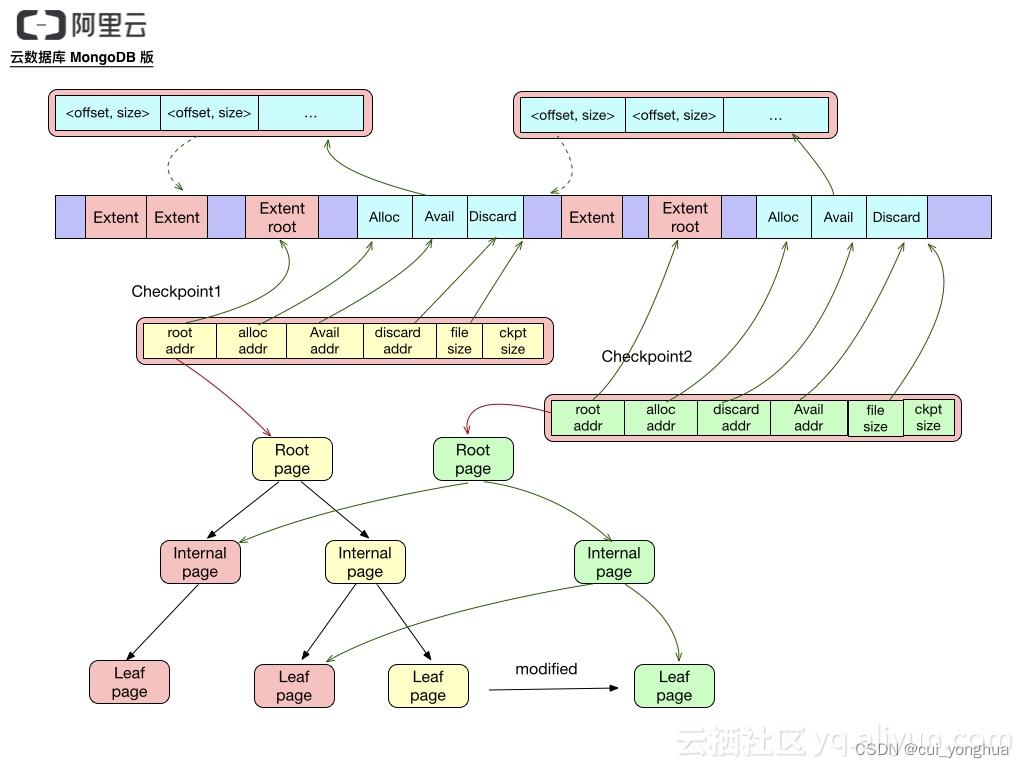
一个Checkpoit包含如下元数据:
root page地址,地址由文件offset,size及内容的checksum组成
alloc extent list地址,存储从上次checkpoint起新分配的extent列表
discard extent list地址,存储从上次checkpoint起丢弃的extent列表
available extent list地址,存储可分配的extent列表,只有最新的checkpoint包含该列表
file size 如需恢复到该checkpoint的状态,将文件truncate到file size即可
WAL(journal)
日志文件记录的是从上一个checkpoint之后的实际操作,该文件每100ms或文件大小到达100M就从缓存同步到磁盘
整体关系
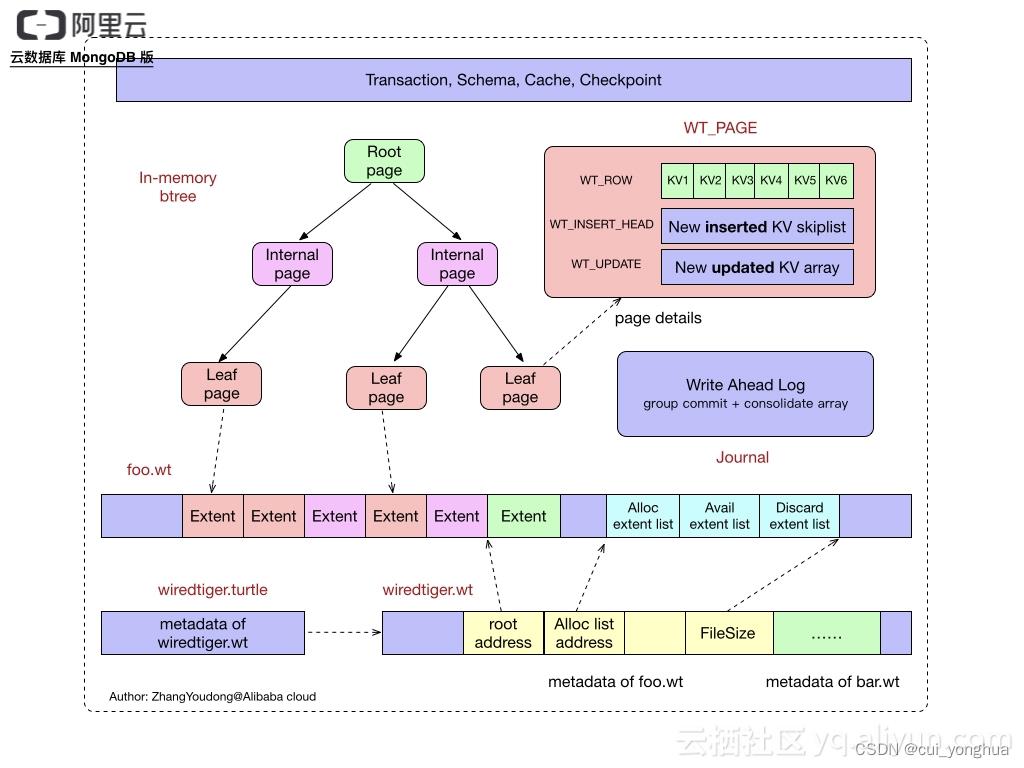
存储引擎原理补充
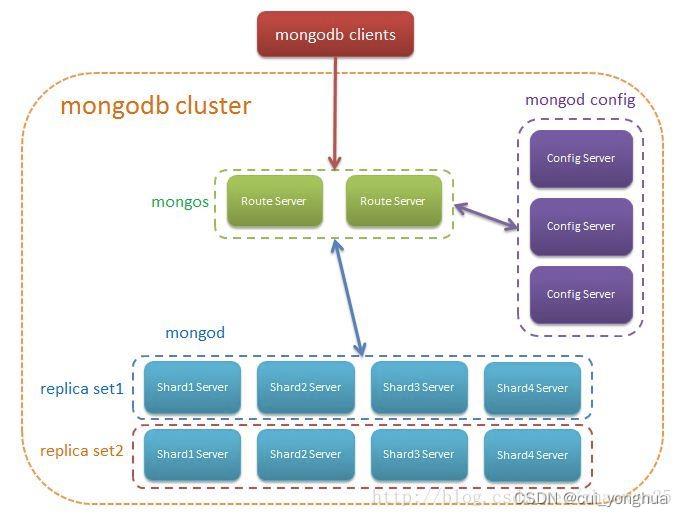
分布式存储
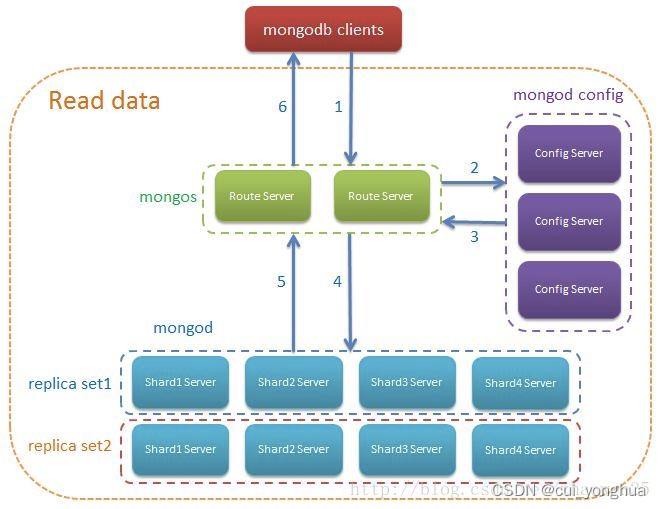
架构
架构图:
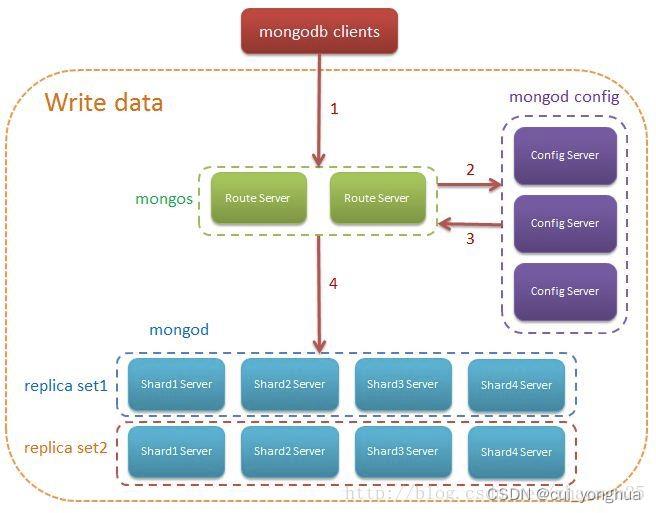
写数据流程:
读数据流程:
以上是关于MongoDB内部的存储原理的主要内容,如果未能解决你的问题,请参考以下文章