四种聚类方法之比较 Posted 2023-04-25
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了四种聚类方法之比较相关的知识,希望对你有一定的参考价值。
四种聚类方法之比较介绍了较为常见的k-means、层次聚类、SOM、FCM等四种聚类算法,阐述了各自的原理和使用步骤,利用国际通用测试数据集IRI
参考技术A
四种聚类方法之比较
R语言确定聚类的最佳簇数:3种聚类优化方法
确定数据集中最佳的簇数 是分区聚类(例如k均值聚类 )中的一个基本问题,它要求用户指定要生成的簇数k。
分层聚类 生成的树状图,以查看其是否暗示特定数量的聚类。不幸的是,这种方法也是主观的。
我们将介绍用于确定k均值,k medoids(PAM)和层次聚类的最佳聚类数的不同方法。
这些方法包括直接方法和统计测试方法:
直接方法:包括优化准则,例如簇内平方和或平均轮廓之和。相应的方法分别称为弯头 方法和轮廓 方法。
统计检验方法:包括将证据与无效假设进行比较。
除了肘部 ,轮廓 和间隙统计 方法外,还有三十多种其他指标和方法已经发布,用于识别最佳簇数。我们将提供用于计算所有这30个索引的R代码,以便使用“多数规则”确定最佳聚类数。
对于以下每种方法:
我们将描述基本思想和算法
我们将提供易于使用的R代码,并提供许多示例,用于确定最佳簇数并可视化输出。
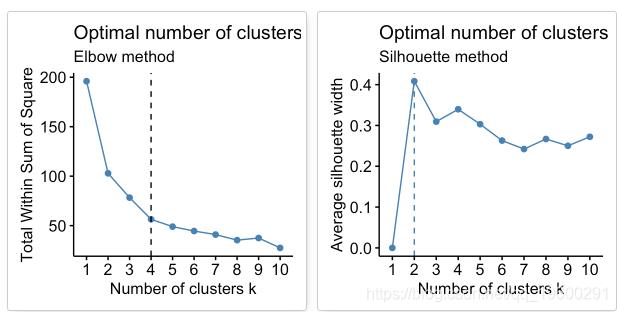
肘法
回想一下,诸如k-均值聚类之类的分区方法背后的基本思想是定义聚类,以使总集群内变化[或总集群内平方和(WSS)]最小化。总的WSS衡量了群集的紧凑性,我们希望它尽可能小。
Elbow方法将总WSS视为群集数量的函数:应该选择多个群集,以便添加另一个群集不会改善总WSS。
最佳群集数可以定义如下:
针对k的不同值计算聚类算法(例如,k均值聚类)。例如,通过将k从1个群集更改为10个群集。
对于每个k,计算群集内的总平方和(wss)。
根据聚类数k绘制wss曲线。
曲线中拐点(膝盖)的位置通常被视为适当簇数的指标。
平均轮廓法
平均轮廓法计算不同k值的观测值的平均轮廓。聚类的最佳数目k是在k的可能值范围内最大化平均轮廓的数目(Kaufman和Rousseeuw 1990)。
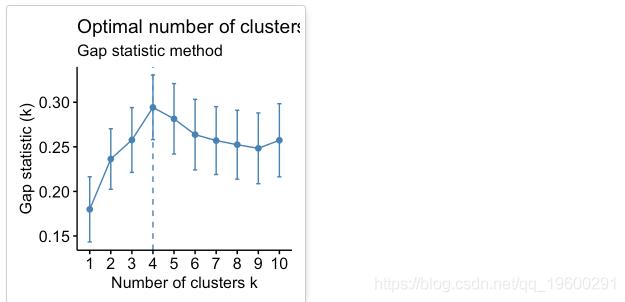
差距统计法
该方法可以应用于任何聚类方法。
间隙统计量将k的不同值在集群内部变化中的总和与数据空引用分布下的期望值进行比较。最佳聚类的估计将是使差距统计最大化的值(即,产生最大差距统计的值)。
资料准备
我们将使用USArrests数据作为演示数据集。我们首先将数据标准化以使变量具有可比性。
Silhouhette和Gap统计方法
简化格式如下:
下面的R代码确定k均值聚类的最佳聚类数:
## Clustering k = 1,2,..., K.max (= 10): .. done
## Bootstrapping, b = 1,2,..., B (= 50) [one "." per sample]:
## .................................................. 50? ?
根据这些观察,有可能将k = 4定义为数据中的最佳簇数。
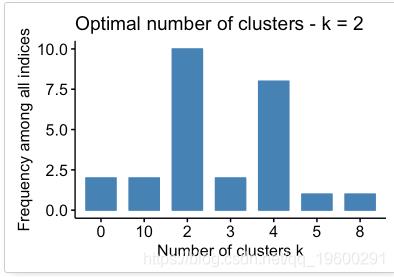
30个索引,用于选择最佳数目的群集
数据 :矩阵
diss :要使用的相异矩阵。默认情况下,diss = NULL,但是如果将其替换为差异矩阵,则距离应为“ NULL”distance :用于计算差异矩阵的距离度量。可能的值包括“ euclidean”,“ manhattan”或“ NULL”。min.nc,max.nc :分别为最小和最大簇数要为kmeans 计算NbClust (),请使用method =“ kmeans”。
要计算用于层次聚类的NbClust (),方法应为c(“ ward.D”,“ ward.D2”,“ single”,“ complete”,“ average”)之一。
下面的R代码为k均值计算:
## Among all indices:
## ===================
## * 2 proposed 0 as the best number of clusters
## * 10 proposed 2 as the best number of clusters
## * 2 proposed 3 as the best number of clusters
## * 8 proposed 4 as the best number of clusters
## * 1 proposed 5 as the best number of clusters
## * 1 proposed 8 as the best number of clusters
## * 2 proposed 10 as the best number of clusters
##
## Conclusion
## =========================
## * According to the majority rule, the best number of clusters is 2 .?
根据多数规则,最佳群集数为2。
如果您有任何疑问,请在下面发表评论。
?
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat (咨询服务请联系官网客服 )
?
?QQ交流群:186388004
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】 提供定制化的一站式数据挖掘和统计分析咨询
欢迎选修我们的R语言数据分析挖掘必知必会
以上是关于四种聚类方法之比较的主要内容,如果未能解决你的问题,请参考以下文章
轨迹聚类:哪种聚类方法?
关于聚类方法的问题
三种聚类方法:层次、K均值、密度
R语言确定聚类的最佳簇数:3种聚类优化方法
哪种聚类算法最适合聚类一维特征?
一文盘点6种聚类算法,数据科学家必备!