云游 Google I/O 2021——Google Cloud 硬件算力和模型新突破
Posted TensorFlow 社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云游 Google I/O 2021——Google Cloud 硬件算力和模型新突破相关的知识,希望对你有一定的参考价值。

作者:王顺 Google Cloud AI 专家
美国时间 2021 年 5 月 18-20 日,Google I/O 2021 成功举办。在这次活动中,Google 带来了各种开发者关注的干货内容和产品资讯。同时 Google Cloud 这次也带来了很多创新主题的分享,特别是最新的 AI 技术。本期内容将围绕包括 Vertex AI、TPU v4、LaMDA、MUM 四个技术要点为大家进行深度剖析。
Vertex AI

Vertex AI 是 Google Cloud 上统一的托管机器学习平台,帮助企业进行 AI 训练、多组实验管理和加速模型的部署。
在此之前 Google Cloud 已经提供了用于自定义模型训练的 AI 平台 (AI Platform) 和 AutoML 产品,比如 AutoML Vision,AutoML Tables,AutoML Natural Language 等。但是用户在使用 AutoML 训练和自定义训练需要和两套不同的工具分别进行交互。
Vertex AI 统一了上述的两套工具,通过一套工具即可无缝管理和部署模型,无论是使用 UI、API 还是不同语言的 SDK,这套工具可以帮助您训练、预测、访问 AutoML Tables、AutoML Vision、AutoML Video Intelligence、AutoML Natural Language、可解释 AI 以及数据标注等等服务。上述的这一组服务被作为各种特性被统一到了这次重磅推出的 Vertex AI ——统一的 AI 平台,即 AI Platform(Unified)。
ML Ops
ML Ops 作为一个新兴的领域,在社区中迅速发展,因为它提供了端到端的机器学习开发流程。帮助设计、构建和管理可复用、可测试和可进化的 ML 驱动的软件。Vertex AI 就提供了以下出众的 ML Ops 功能:
● Vertex Experiments——跟踪、分析和发现 ML 实验以加快模型的选择。
● Vertex Vizier——为超参调优提供优化值,以最大化模型预测的精度。
● Vertex Pipelines——简化了 ML 流水线的构建和运行,进而简化 ML Ops。
● Explainable AI——可解释 AI 为您提供详细的模型评估指标和特征属性,帮助了解每个输入特征对于预测的重要性。
端到端的全生命周期管理
Vertex AI 管理 ML 流水线的工作流程可以归纳为以下几个阶段:
● 定义并上传数据
● 使用 AutoML 或指定 GPU 机型进行自定义训练
● 获得模型评估和超参调优
● 使用数据标注服务为自定义训练模型数据集请求人工标注
● 在 Vertex AI 中上传和存储您的模型
● 部署模型并获得用于预测的端点 (endpoint)
● 发送预测请求
● 在端点中指定预测流量的拆分规则
● 管理您的模型和端点
ML 模型只有在您将其实际投入生产时才具有价值。Vertex AI 以开发人员为中心并统一 ML 体验的多种特性的发布,会大大简化流水线的构建和模型的部署与管理进而帮助企业更专注于业务并提高效率。访问 Vertex AI 页面了解新的特性和快速上手。
TPU v4
从加强网络安全到提高医疗诊断准确性,机器学习技术为多方面的业务和研究领域带来了突破。为了让所有人都能够实现这样的突破,我们打造了张量处理单元 (TPU)。Cloud TPU 是 Google 专为机器学习打造的 ASIC,广泛应用于翻译、相册、搜索、助理和 Gmail 等诸多 Google 产品。运用 Cloud TPU 和机器学习技术可以协助您的企业加速取得成功。
但是对于 TPU,一部分读者和一些网上的文章还存在某些理解错误或偏差,在这里我通过和 v4 的对比给大家做一下回顾。
第一代 TPU
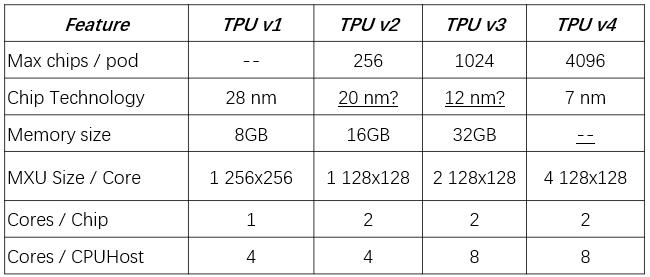
第一代 TPU 基于 28 纳米制程,主频是 700MHz,能耗是 40W,主要用于 Google 产品的推理,包括搜索、翻译、相册,当然更出名的是它被用到了 AlphaGo 的比赛中。由于这代 TPU 为推理而设计,支持 int8 量化,矩阵乘加单元做到了 256x256,这比之后的几代都要大。
第二代 TPU
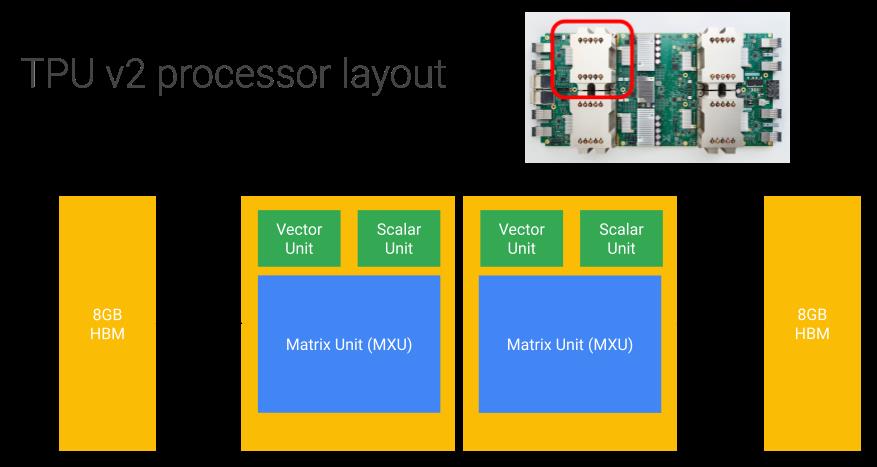
第二代 TPU 则主要为训练而设计,如下图,每张卡包含了 4 个芯片 (chips),每个芯片含有两个核 (cores),所以在 Google Cloud 文档上我们会看到 v2-8 的称呼,而在学术论文中更多是使用 chips 数量来表达算力,网上看到的最容易出错的地方就是简单的把一个芯片 (chip) 等价为个或者张。v2-8 具有每秒 180 万亿次的浮点运算和 64GB 的高带宽内存 (HBM)。矩阵乘加单元 (MXU) 规格为128x128,每周期支持 16K bfloat16 格式的乘加操作。

MXU 之外,还有专门的向量单元和标量单元,Tensorflow 有专门针对 TPU 的 TPUEmbedding API,可以通过配置 pipeline_execution_with_tensor_core=True 帮助加速稀疏 embedding 表的查找和更新 (tf.nn.embedding_lookup & update: embedding.apply_gradients(embedding_gradients))。
TPU 最强大的是互联能力,64 张 v2-8 组成的 8x8mesh 提供了 11.6PFlops 的算力。
第三代 TPU
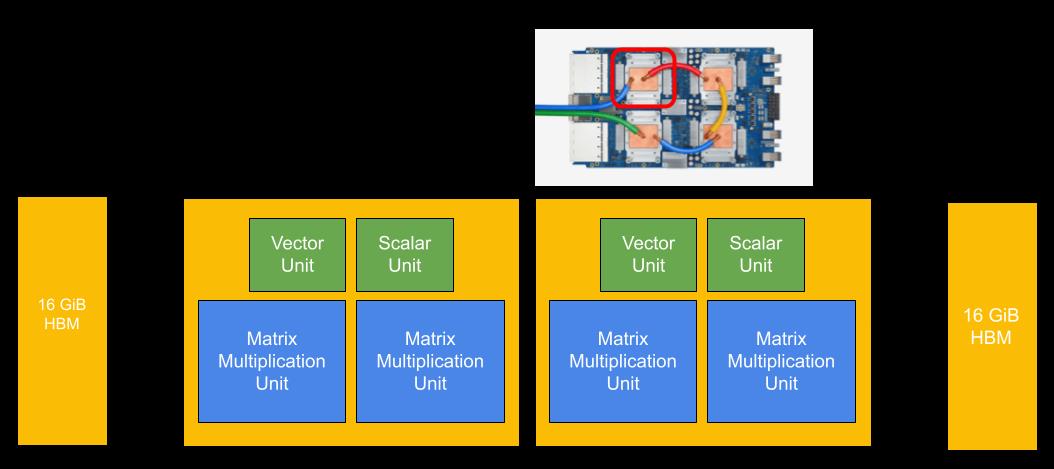
如下图,第三代 TPU 同样是每张卡四个芯片,每个芯片两个核。一个显著的变化也可以在图中看到,v3 引入了液冷。

其他主要的不同是矩阵乘加单元 (MXU) 从每核一个增大到了两个,对应的 HBM 也增加了一倍,所以 v3-8 的每秒浮点运算可达 420 万亿次,高带宽内存达 128GB。
对比 v2 Pod 的 v2-512,16x16 的二维环形网络将 256 张 v3-8 组成了 v3-2048 更大规模的 v3 Pod,算力可以达到 100 PFlops 以上,高带宽内存达到 32TB。
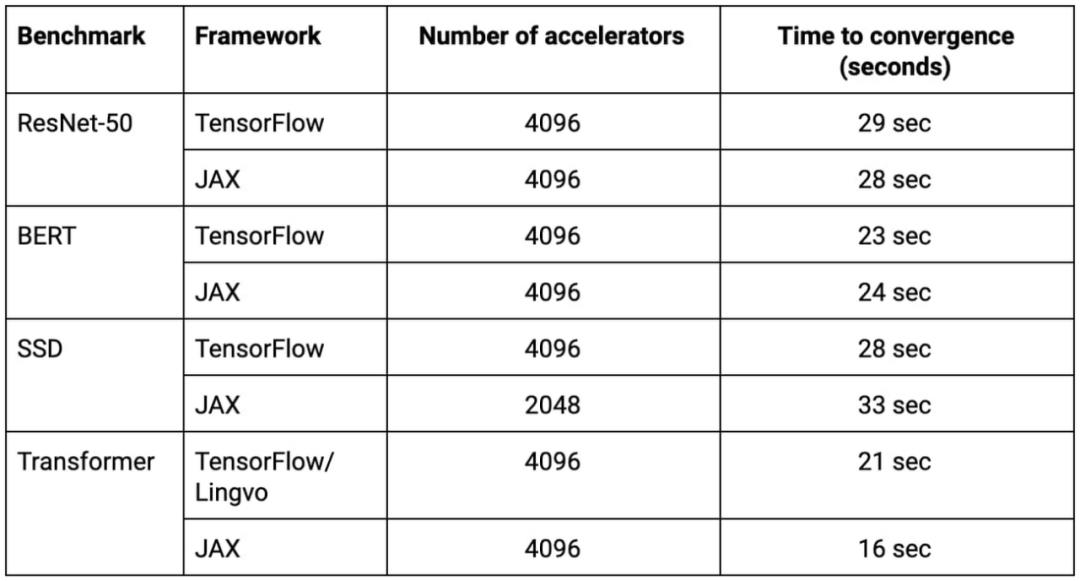
在 2020 年的 MLPerf 训练基准 v0.7 发布中,Google 将四个 v3-2048 组成了一个 4096-chips 的 superpod,峰值性能超过了 430 PFLOPs。8 个基准测试中的 4 个在 30 秒内就完成了训练(见下表)。

第四代 TPU
第四代 TPU 采用了 7nm 的制程,算力是 v3 的两倍以上,Pod 并行训练则是 v3 Pod 性能的十倍之多——达到了 1ExaFLOPs 以上。即每秒 10 的 18 次方浮点运算,而且芯片间的高互联带宽也是目前其他任何组网技术的十倍,未来无论是服务 Google 自家的推荐模型还是云上客户推荐模型的训练任务都将大受裨益。细心的同学还可以看到如下图更多的细节。

一些更具体的信息还有待进一步披露,这里就不再过多展开了,想更多了解的读者还可以关注即将举办的 ISCA 2021 大会,会上有关于 TPU v4 的更多分享:


Google Cloud 上的 TPU 和 GPU 资源为客户提供了训练大模型(当然还有推理)所需的算力,另外 Google 在算法和模型开源上的最新进展可以给 Google Cloud 客户提供与模型训练相关的更多技术支撑和实践指南,所以 Google I/O 2021 在自然语言理解和多模态上的最新进展同样会给云上的客户带来启发。
LaMDA
2017 年 Google 就提出了 Transformer 架构,基于其 BERT 等模型在 2020 年之前就引起了广泛的关注。2020年 BERT 技术被广泛用于 Google Search,每十个搜索结果中就有一个因此得到了改进,DialogFlow 也发布了被称为 DialogFlow CX 基于 BERT 技术的高级版。另外,AlphaFold2 引入 Transformer 相对 AlphaFold 有了更大的提升,被认为一举解决了 50 年未决的蛋白质折叠难题,2020 年当之无愧的被 AI 业界公认为 Transformer 之年。
2020 年 1 月份 Google 就发布了基于 Transformer seq2seq 架构的对话机器人 Meena,她具有 26 亿参数和接近于人的对话能力;随后在 7 月份 OpenAI 发布了作为 Transformer 注意力机制更典型代表的 GPT-3 模型,该模型将参数扩展到了 1750 亿,作为通用型的语言模型,在文本生成等多种 NLP 任务上都非常出色。
LaMDA (Language Model for Dialogue Applications) 展示了最新的开放域类人对话场景的 SOTA 性能,是 Google 在 Transformer、BERT、T5、Meena 等技术之上在自然语言理解 (NLU) 领域的最新成果发布。

关于 LaMDA 的更多信息还有待 Google 进一步发布,因为 Meena 模型曾经对标 OpenAI 的 GPT-2,在此可以类比 OpenAI 的 GPT-2 到 GPT-3,我们通过回顾 Meena,来推测和理解 LaMDA 模型。
Meena 模型有 26 亿参数,在 341GB 文本上进行训练,这些文本是从公共领域的社交媒体对话中过滤出来的。对比当时(2020 年 1 月)最先进的 GPT-2 模型(15 亿参数和 40GB 文本),Meena 容量提高了 1.7 倍,训练数据增大了 8.5 倍。
Meena 在理智和具体 (Sensibleness andSpecificity Average) 方面已经非常接近人类,相信 LaMDA 会更近一步。在最新介绍 LaMDA 的博客里还特别提到趣味性 (interestingness) 和真实性 (factuality),通过下面的示例可以具体的理解这两点。
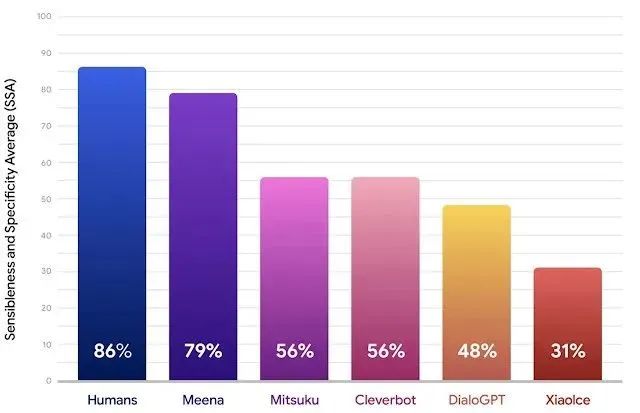
主题演讲上给出了 LaMDA 分别扮演冥王星和纸飞机与用户进行了精彩的对话,这里翻译一小段来回顾这段对话:
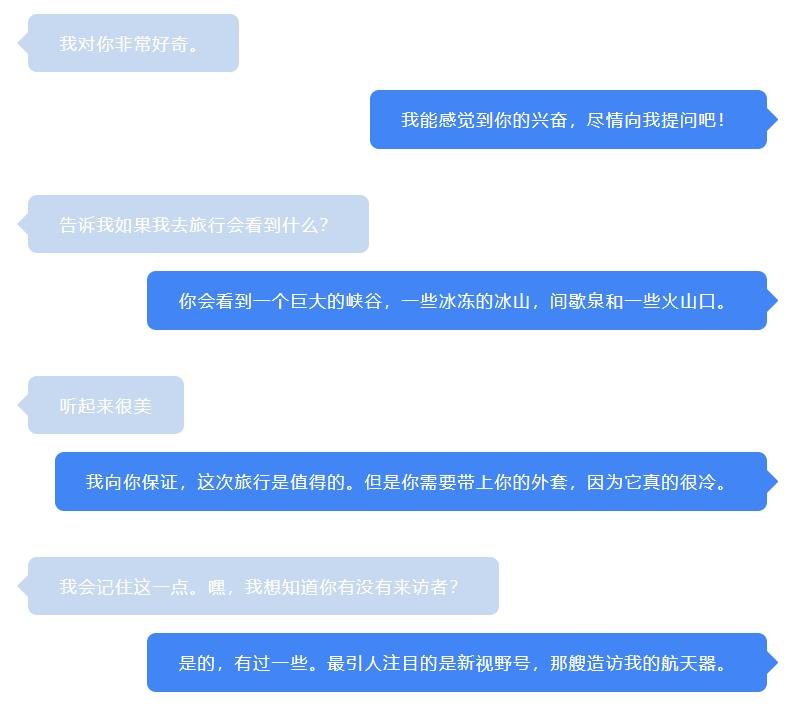
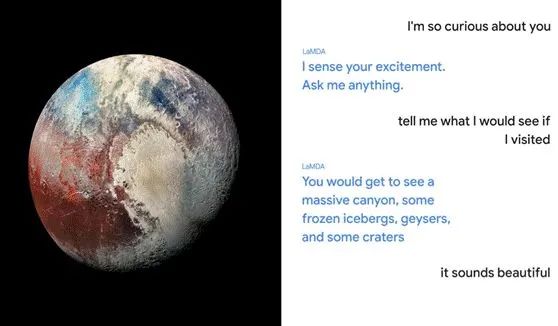

可以看到短短的一段对话中,拟人化的交互体验非常好,合乎语境,表达流畅,回答精准,仿佛感受到在和知识渊博的专家对话,随时可以学到新的知识。
MUM
在最新的 blog 介绍中,将 MUM(多任务统一模型,Multitask Unified Model)称为理解信息的新 AI 里程碑,比之前的 BERT 模型强大 1000 倍。
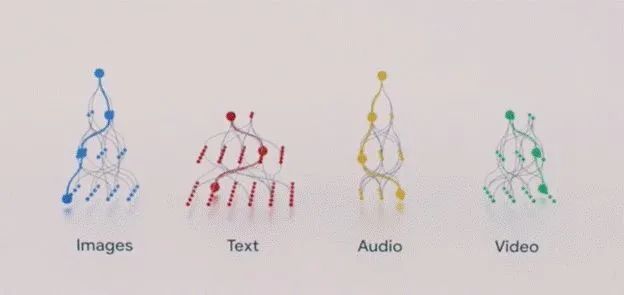
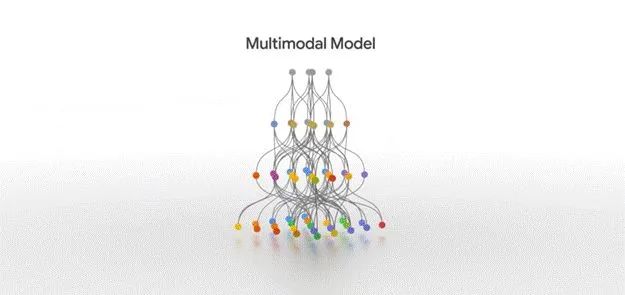
LaMDA 是完全基于文本数据训练的 Transformer 模型。而在真实生活中,我们更希望是能够将文字、图像、语音和视频等多种模态的数据结合到一起,希望有个统一的模型能够以我们期望的形态给出最好的答案,这也是我们目前使用搜索引擎的一大痛点,往往要多次细化我们的搜索关键字才能找到最匹配的答案。
而 MUM 可以让我们对未来的搜索引擎有更大的期待,主题演讲中给出了一个具体的例子:

“我去过亚当斯山徒步,明年秋天想去富士山,需要做哪些不同的准备?”
今天,Google 可以帮助你解决这个问题,但这需要经过深思熟虑的许多搜索——你必须搜索每座山的海拔、秋季的平均温度、远足路径的难度、合适的装备等等。经过多次复杂的搜索,您最终能够得到所需的答案。
由于 MUM 可以根据其对世界的深入了解得出见解,因此它可以强调,虽然两座山的海拔大致相同,但秋天是山上的雨季。富士山之旅你可能需要一件防水夹克。MUM 还可以显示有用的子主题以进行更深入的探索——例如,最受好评的装备或最佳训练练习——以及来自网络上的有用文章、视频和图像的链接。
消除语言障碍
语言可能是获取信息的重大障碍。MUM 有可能通过跨语言传输知识来打破这些界限。她可以从不是您搜索所用的语言编写的数据源中学习,并将这些信息带给您。
比如说有关于用日语写的富士山非常有用的信息,今天如果你不用日语搜索,你可能找不到它。但是 MUM 可以跨语言传输来自不同来源的知识,并使用这些见解以您的首选语言找到最相关的结果。因此将来,当搜索有关参观富士山的信息时,您可能会看到诸如哪里可以欣赏到山的最佳景色、该地区的温泉和受欢迎的纪念品商店等结果——所有这些信息在用日语搜索时更常见。

跨模态理解信息
MUM 是多模态的,这意味着它可以同时理解来自不同格式的信息,如网页、图片等。最终,您或许可以为您的登山靴拍张照片并询问:“我可以用这些来远足富士山吗?” MUM 会理解图像并将其与您的问题联系起来,让您知道您的靴子是否适合。然后它可以将您指向一个包含推荐装备列表的博客。

这个搜索的演示很容易让我联想到 Google Cloud 上针对零售电商的服务 Retail AI,这个解决方案主要依靠 AI 技术驱动,包含了三个主要部分:
● Vision Product Search 以图搜图
用户使用自己的图片查询商品集时,Vision API Product Search 会应用机器学习,以比较用户查询图片中的商品与零售商商品集中的图片,然后返回在视觉和语义上类似的结果排序列表。
● Recommendations AI 高度个性化的商品推荐
多年来,Google 一直在 Google Ads、Google 搜索和 YouTube 等旗舰渠道中提供推荐内容。Recommendations AI 汲取这些经验以及机器学习方面的专业知识,在您的所有接触点中为客户提供符合他们的品味和偏好的个性化推荐。
● Search for Retail 搜索零售商品(非公开预览)
充分利用 Google 的丰富专业知识,提供可配置的直观搜索功能,从而满足零售组织的特定需求。相信多模态模型的进展会进一步让云上的企业客户受益良多。
以上总结了这次 Google I/O 2021 大会发布的 Google Cloud 可以赋能您 AI 的算力、算法领域最新进展,感谢您的阅读,也希望能为您的技术开发之旅带去新的灵感。更多精彩和细节,也欢迎点击阅读原文观看主题演讲回放。
登陆官网或关注 TensorFlow 官方微信公众号,了解更多资讯。

以上是关于云游 Google I/O 2021——Google Cloud 硬件算力和模型新突破的主要内容,如果未能解决你的问题,请参考以下文章