深度学习Deep Learning必备之必背知识点
Posted Taily老段
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习Deep Learning必备之必背知识点相关的知识,希望对你有一定的参考价值。
https://mp.weixin.qq.com/s/fZqVeUSTM47QAOOIS3-Vbg
这篇文章有哪些需要背诵的内容:
1、张量、计算图、会话
神经网络:用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权重(参数),得到模型。
张量:标量(单个)、向量(1维)、矩阵(2维)、张量(n维)
2、前向传播
网络的线上的权重W,用变量表示,随机给初值。
前向传播计算得到输出。
3、反向传播
反向传播优化参数训练的模型。用梯度下降,使loss最小。
优化器Optimizer:GradientDescent、Momentum、Adam。
4、损失函数 loss
预测值与已知结果的差距。常用均方误差MSE作为loss;
5、学习率 learning rate
决定参数每次更新的幅度。
6、滑动平均
提高模型泛化能力。
7、正则化
缓解过拟合。
8、神经网络搭建
生成数据集 generateds
前向传播 forward
反向传播 backward
9、全连接网络 full connect
每个神经元与前后相邻层的每一个神经元都有连接关系。
10、卷积 convolutional
核心
11、全零填充 padding
输入图像周围全零填充,卷积后保证输出图像与输入一致。
12、池化 pooling
减少特征数量。
13、舍弃 dropout
减少过多的参数,暂时舍弃部分神经元。
14、卷积神经网络 CNN
借助卷积核提取特征后,送入全连接网络。
1、张量、计算图、会话
张量:标量(单个)、向量(1维)、矩阵(2维)、张量(n维)
计算图(Graph):搭建神经网络的计算过程,只搭建,不运算。

会话(Session):执行计算图中的节点运算。Session的run来执行。
2、前向传播
参数:网络的线上的权重W,用变量表示,随机给初值。
前向传播需定义输入、参数和输出。
 神经网络实现过程:
神经网络实现过程:
1-准备数据集,提取特征,作为输入喂给神经网络Neural Network(NN)
2-搭建NN结构,从输入到输出(先搭建计算图,再用会话执行)
NN前向传播算法——>计算输出
3-大量特征数据喂给NN,迭代优化NN参数
NN反向传播算法——>优化参数训练模型
4-使用训练好的模型预测和分类
基于深度学习的神经网络一般是两个过程:训练和使用;上面过程中1、2、3步是训练的过程,准备好数据集,前向和反向进行训练数据,前向是计算出输出,反向则是对上一次的前向过程进行参数的优化,得到新的参数,通过不断迭代训练出最终的模型;模型训练完成后,通过加载模型,对待测对象进行预测或分类计算。
前向传播:搭建模型,实现推理;
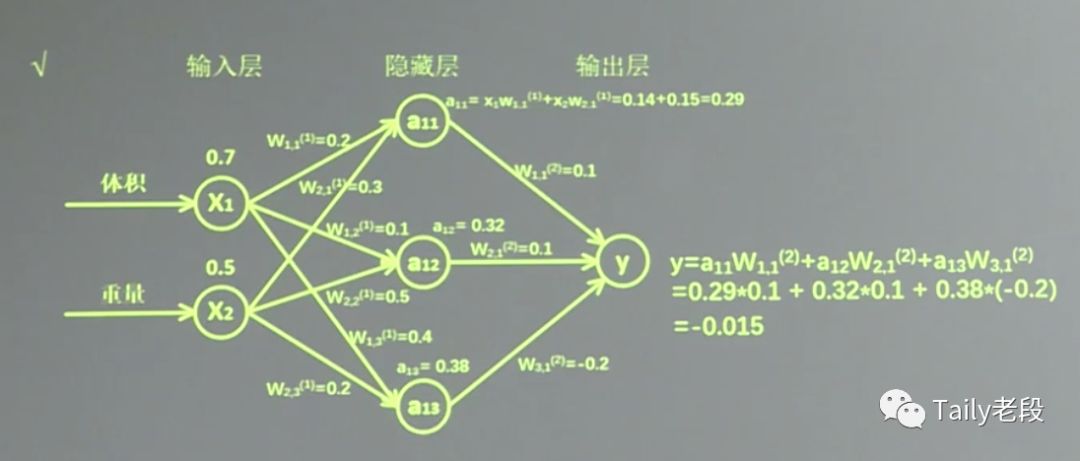
3、反向传播
反向传播需定义损失函数(loss=)、反向传播方法(train_step= )。
反向传播优化参数训练的模型。用梯度下降,使loss最小。
优化器Optimizer:GradientDescent、Momentum、Adam。
4、损失函数 loss
预测值与已知结果的差距。
NN的优化目标是让loss最小;
常用方法:均方误差MSE(mean squared error)、自定义、交叉熵CE(cross entropy)(表征两个概率分布之间的距离)。

激活函数 activation function:Relu、Sigmoid、tanh。

NN复杂度:多用NN层数和NN参数的个数表示。
层数 = 隐藏层的层数 + 1个输出层
总参数 = 总w + 总b
softmax()函数:让每个输出都在[0, 1]之间。

5、学习率 learning rate
每次参数更新的幅度。

学习率设置多少合适?
学习率大了振荡不收敛,学习率小了收敛速度慢。
6、滑动平均(影子值)
滑动平均是一个优化方法,记录每个参数一段时间内过往值得平均,增加了模型的泛化性。
(泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。通常期望经训练样本训练的网络具有较强的泛化能力,也就是对新输入给出合理响应的能力。)

在Tensorflow中ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
MOVING_AVERAGE_DECAY:衰减率(一般给比较大的值)
global_step:当前轮数。
7、正则化
有时候我们发现模型在训练数据集上的正确率非常高,但这个模型却很难对从来没有见过的数据做出正确响应,我们说这个模型存在“过拟合”的现象。
正则化缓解过拟合。
正则化在损失函数中引入模型复杂度指标,利用给W加权值,弱化了训练数据的噪声(一般不正则化b)

8、神经网络搭建总结



9、全连接网络 full connect
每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果。

针对灰度图和彩色图,灰度输入的宽*高,彩色图输入是宽*高*通道数;对图像进行深度学习,输入的数据比较大,参数也相应的比较多。

实际应用中会先对原始图像进行特征提取,再把提取到的特征喂给全连接网络。

10、卷积 convolutional
卷积可认为是一种有效提取图像特征的方法。
一般会用一个正方形卷积核,遍历图片上的每一个像素点。图片区域内,相对应的每一个像素值,乘以卷积核内相对应的权重,求和,再加上偏置。
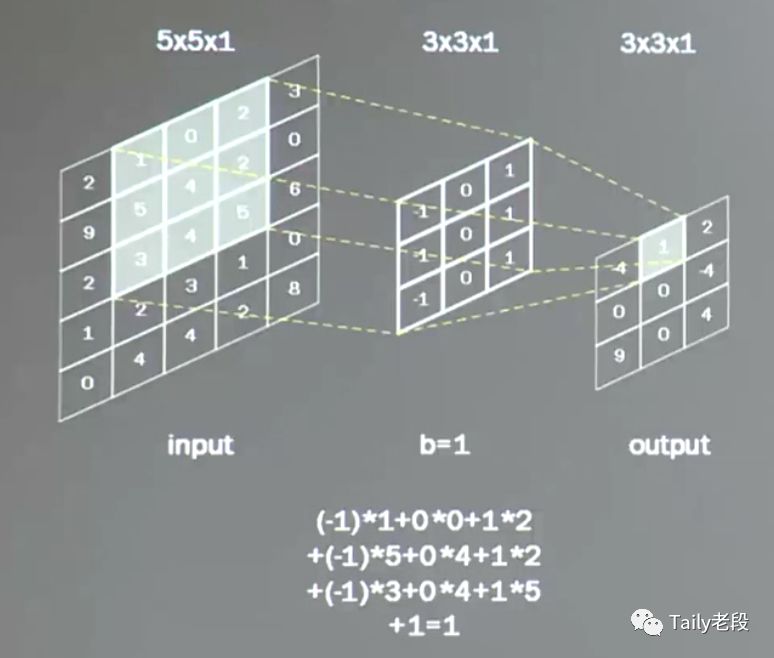
输出图片边长 = (输入图片边长 - 卷积核长 + 1 ) / 步长
下图计算:(5-3+1)/ 1 = 3

11、全零填充 padding
在输入图像的周围进行全零填充padding,这样可以保证输出图像大小和输入图像一致。比如下图,在5*5的输入图像周围全零填充,经过卷积计算后,输出图像依然是5*5大小的图像。

输出图像边长 = 输入图像边长 / 步长
上图计算的输出图像边长 : 5 / 1 = 5
Tensorflow中计算卷积的输入参数包括以下:(灰度图)

彩色图像的情况下的卷积计算:

Tensorflow中计算卷积的输入参数包括以下:(彩色图)

12、池化 pooling
通过卷积进行特征提取,提取到的特征数量依然巨大,池化用于减少特征的数量。
池化的主要方法:最大池化可提取图片纹理,均值池化可保留背景特征。

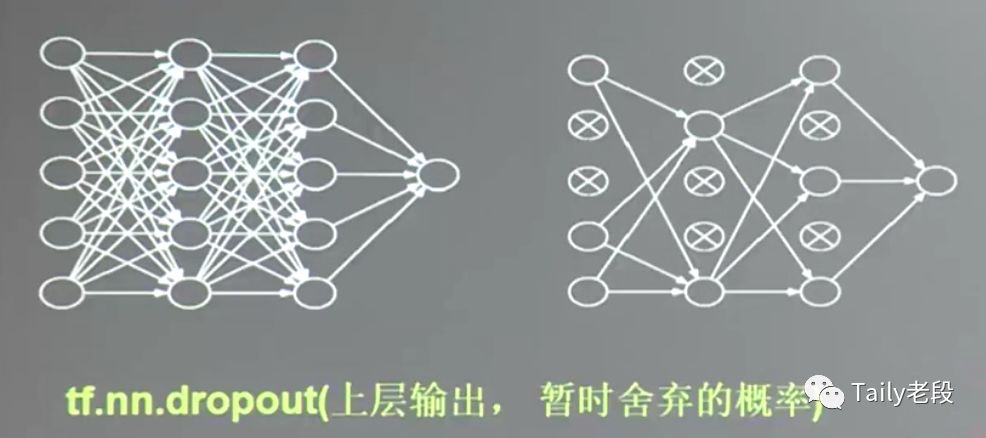
13、舍弃 dropout
在神经网络的训练过程中,将一部分神经元按照一定概率从神经网络中暂时舍弃。使用时被舍弃的神经元恢复连接。这种舍弃时临时性的,仅在训练时舍弃一定概率的神经元,在使用神经网络时会把所有的神经元恢复到神经网络中。dropout可以有效减小过拟合。
14、卷积神经网络 CNN
借助卷积核(kernel)提取特征后,送入全连接网络。
CNN可以认为是由两部分组成,第一部分是对输入图像的特征提取,第二部分是全连接网络,只不过喂入全连接网络的不是原始图片,而是经过若干次卷积、激活、池化后的特征信息。

深度学习的知识分支:

附:两个体验Demo
Demo 1 :3D Visualization of a CNN:
http://scs.ryerson.ca/~aharley/vis/conv/

Demo 2 :ConvnetJS Demo:
https://cs.stanford.edu/people/karpathy/convnetjs//demo/classify2d.html

Taily老段的微信公众号,欢迎交流学习

2018-09-25最近在忙工作上的开发任务,好长一段时间没更新公众号的文章了,实在抱歉;我看很多童鞋在公众号提出一些人工智能相关的问题,打算利用一下国庆假期的时间好好学习整理一下知识点,然后分享给大家,感谢大家的关注,感谢大家的交流学习;
以上是关于深度学习Deep Learning必备之必背知识点的主要内容,如果未能解决你的问题,请参考以下文章