自主实现的web服务器
Posted RWCC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自主实现的web服务器相关的知识,希望对你有一定的参考价值。
web服务器
背景
http协议被广泛使用,从移动端,pc端浏览器,http协议无疑是打开互联网应用窗口的重要协议,http在网络应用层 中的地位不可撼动,是能准确区分前后台的重要协议。
描述
采用C/S模型,编写支持中小型应用的http,并结合mysql,理解常见互联网应用行为,做完该项目,从技术上完全理解从上网开始,到关闭浏览器的所有操作中的技术细节。
应用技术
网络编程(TCP/IP协议, socket流式套接字,http协议)
多线程技术
cgi技术
shell脚本
线程池
一、认识HTTP
http背景
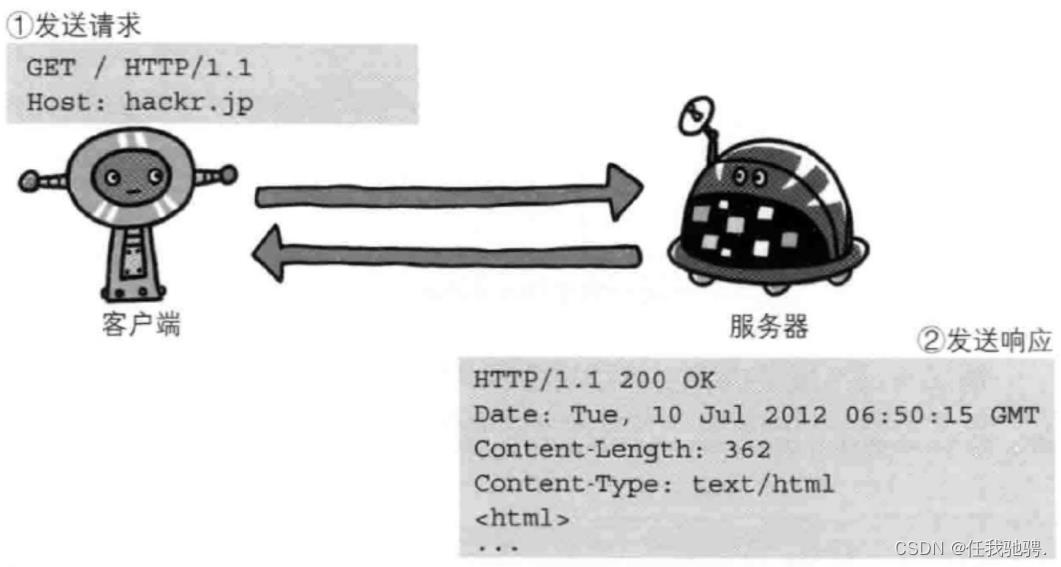
简单快速,HTTP服务器的程序规模小,因而通信速度很快。
灵活,HTTP允许传输任意类型的数据对象,正在传输的类型由Content-Type加以标记。
无连接,每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。(http/1.0具有的功能,http/1.1兼容)
无状态
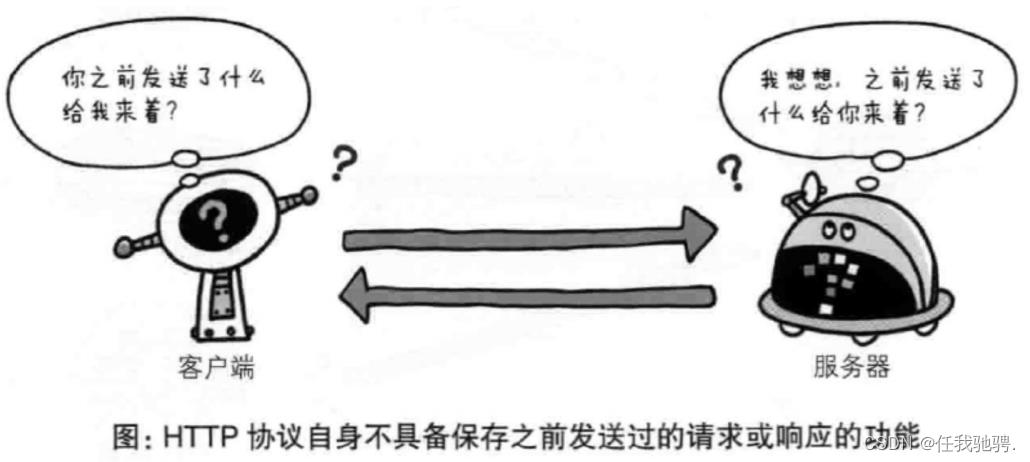
http协议每当有新的请求产生,就会有对应的新响应产生。协议本身并不会保留你之前的一切请求或者响应,这是为了更快的处理大量的事务,确保协议的可伸缩性。
可是,随着web的发展,因为无状态而导致业务处理变的棘手起来。比如保持用户的登陆状态。
HTTP请求与响应
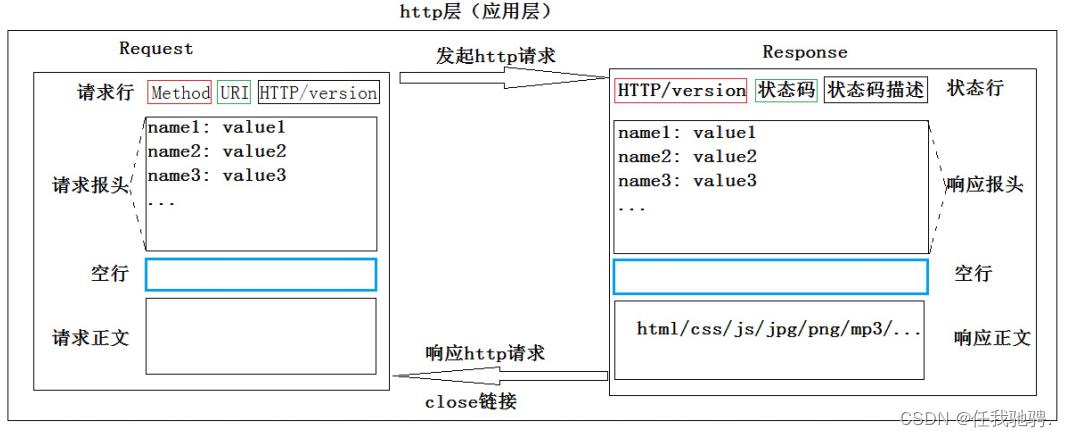
具体http细节说明
请求
响应

http请求 - 方法

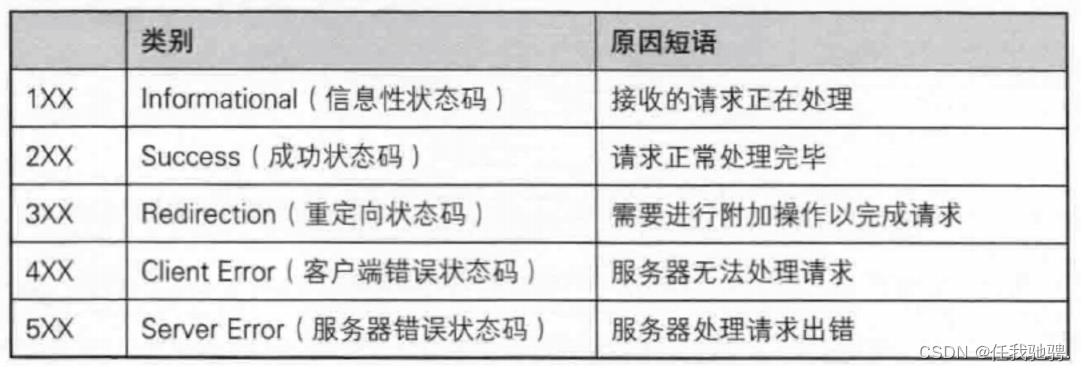
http响应 - 状态码及其描述
HTTP状态码(HTTP Status Code)是用以表示服务器HTTP响应状态的3位数字代码。通过状态码,就可以知道服务器端是否正确的处理的请求,如果不正确,是因为什么原因导致(404)
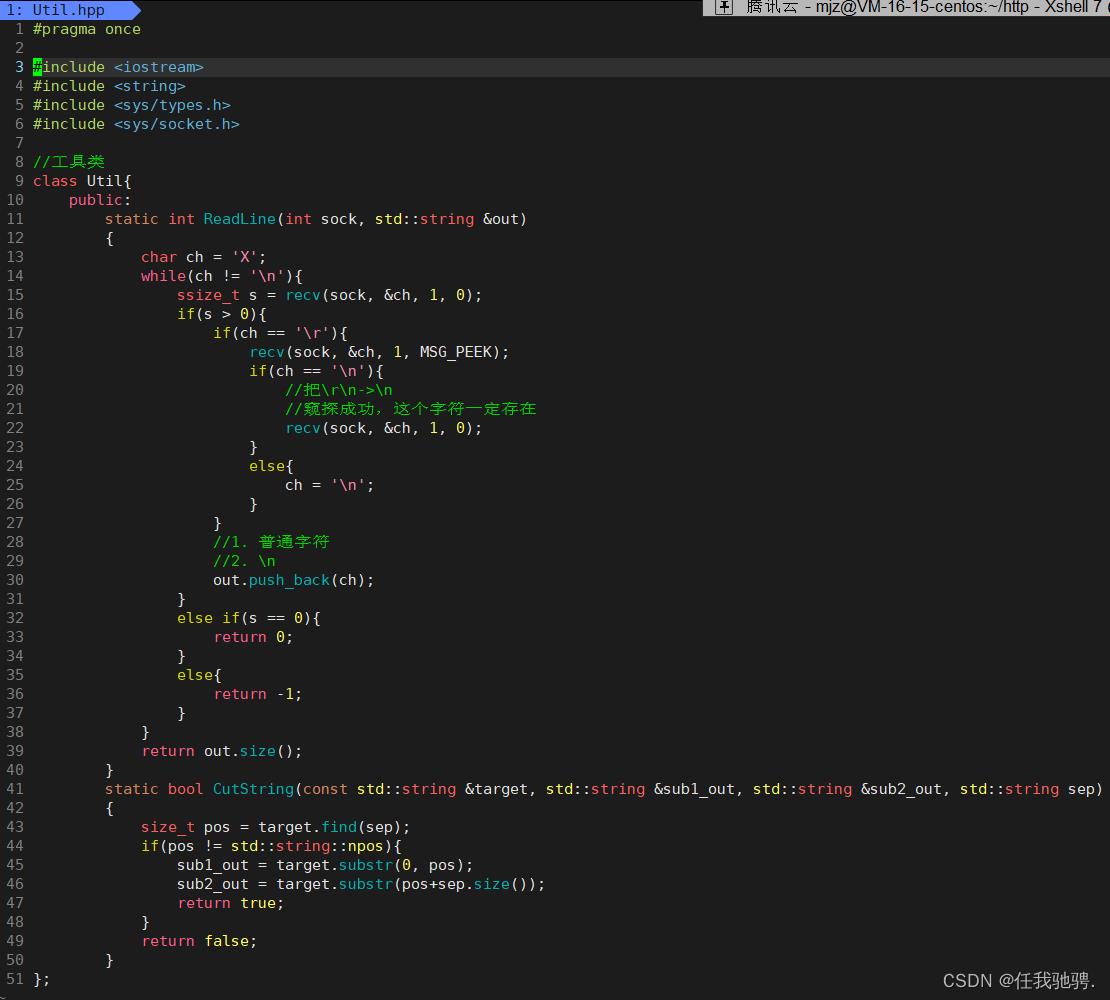
三、工具类
在我们的工具类中,最常用的是ReadLine()函数和Cutstring函数()。ReadLine()函数的作用是将sock中的数据一行一行读取上来,当浏览器发送http请求给服务器的时候,请求行为第一行,请求报头中的每种属性也是按行区分开来的,所以我们会用该函数去读取http请求。其中,不同浏览器发送过来的http请求中行分隔符是不太一样的,有的是“\\n",有的是"\\r\\n",有的是“\\r",因此,我们可以将所有的行分隔符都处理成”\\n".方便我们后续的处理。
recv()函数中携带MSG_PEEK标志位表示的是只查看sock中数据,但是不将数据拿到应用层上,也就是说,不将这次读取sock中的数据给删除掉。
如果拿到的字符是\\r,那么我们需要判断下一个字符是否为\\r\\n,如果不是\\n,那么改行已经结束,但我们不能破坏下一行的数据,因此就MSG_PEEK进行查看。
四、HTTP服务器的构建
当http服务器收到一个请求的时候,服务器需要做4件工作:读取请求,分析请求,构建响应,发送响应。
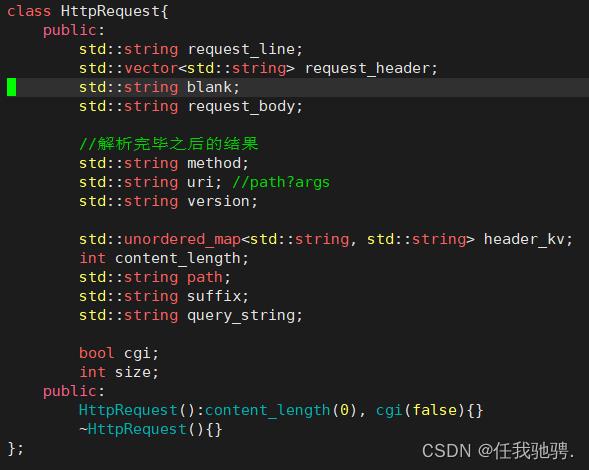
http请求类
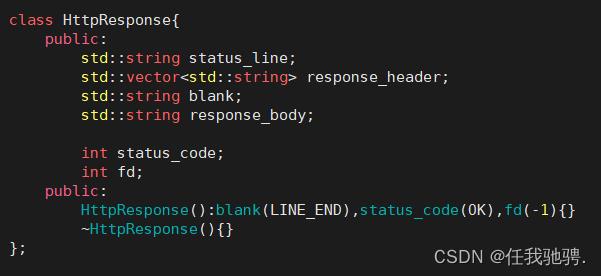
http响应类
读取请求
服务器在sock收到的请求是一堆字符串,那么怎么读取呢?我们可以使用工具类中的ReadLine()函数将sock中的请求一行一行的读取上来然后分类到http请求中的请求行,请求报头,空行,请求正文中。
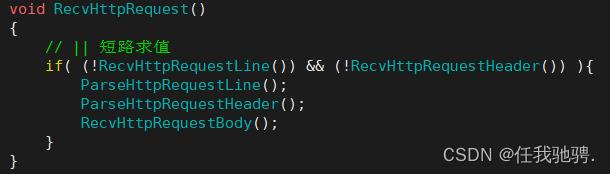
1.读取请求行
因为第一行一定是请求行,将读取到的第一行放进request_line中。
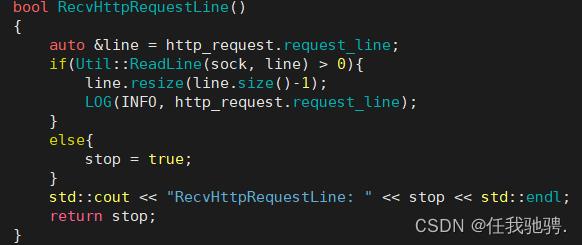
2.读取请求报头
因为在请求报头的每种属性,是按行为单位的,所以我们从sock中一行一行的读取
请求报头的属性,然后再将读取的属性插入到请求报头中。
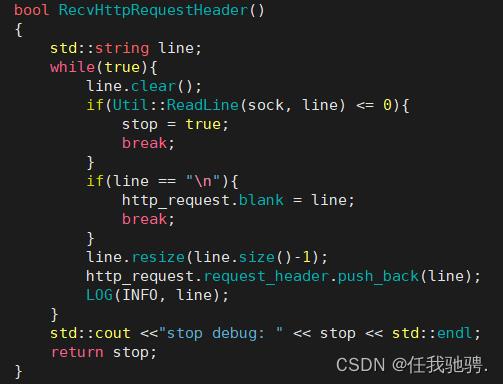
3.解析请求行
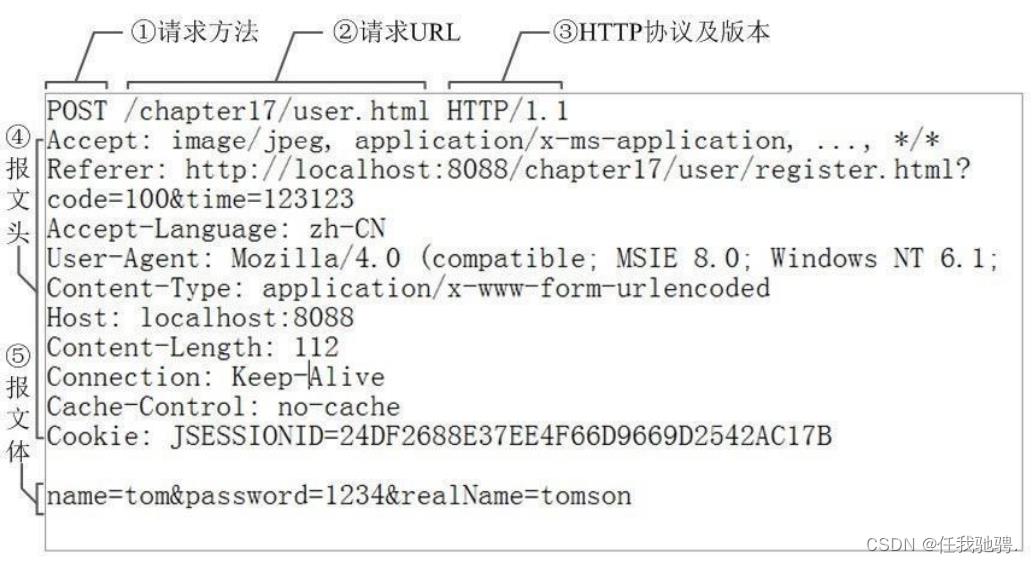
分析请求行:我们需要将读取到的请求行拆分成三个部分:请求方法,URI,请求版本,以便我们后续根据请求方法,URI和版本构建响应。

解析URL
URI中包含请求资源的路径或者包含请求资源的路径和参数,资源的路径是指明指明浏览器要访问的资源的位置,参数是直接给传递给找到的资源。所以需要将URI拆分成请求路径和参数。
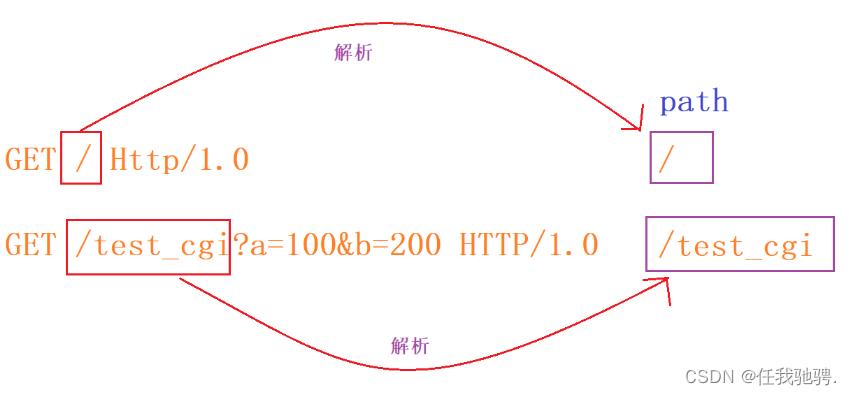
在GET方法中,URI中可能包含请求资源的路径和参数,路径与参数是怎么用?相隔开的,如下:
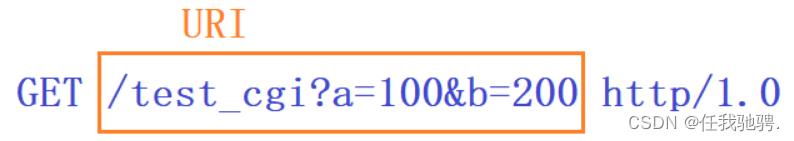
其中/test_cgi是请求路径,a=100&b=200是参数,参数与参数之间是用&分隔开的。
也可能只包含请求路径:

右上图可以得知,我们判断一个GET方法是否带路径,我们只需要判断URI中是否存在?,如果存在,我们将URI拆分成两部分path和parameter,如果不存在直接将URI赋值path。
如果是POST方法,URI只可能包含路径,如果有参数,参数是存放在正文中的,因此如果是POST方法,我们直接将URI赋值给path即可。
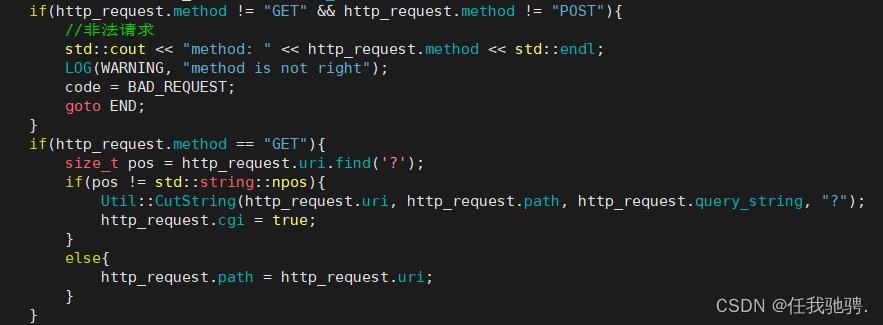
分析请求报头
请求报头中包含了请求中的各种信息,但是它们都是以 ”属性名:属性信息“ 的形式存储在vector中,例如:“Content-Length: 10",为了方便我们找到请求报头中的各种信息,我们需要将请求报头中的每种属性拆分成属性名-属性信息键对值存放在unordered_map。
每种报头中每种属性里,属性名和属性信息都是用 “:”分隔开的。如下:

因此我们需要根据”:“将属性名和属性信息分隔开来。
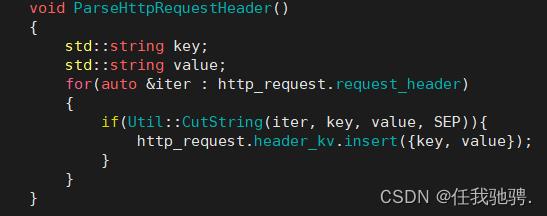
读取请求正文
当解析请求行和请求报头完后,我们就可以知道method和Content-Length,我们就可以判断请求正文中有内容?如果请求正文中有内容,那么就需要读取多少?
在GET方法中,请求正文是被设置为空,所以GET方法是不需要读取请求正文的,如果是POST方法,它的请求正文有可能为空,也有可能存在,如果POST方法中的请求正文存在,Content-Length是不等于0的,在sock读取多少个字节呢,根据Content-Length判断即可,如果POST方法中的请求正文不存在,那么Content-Length是为0,因此是不需要读取请求正文的。
判断是否需要读取request正文
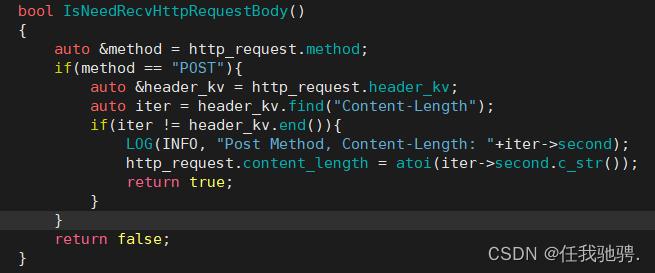
读取正文
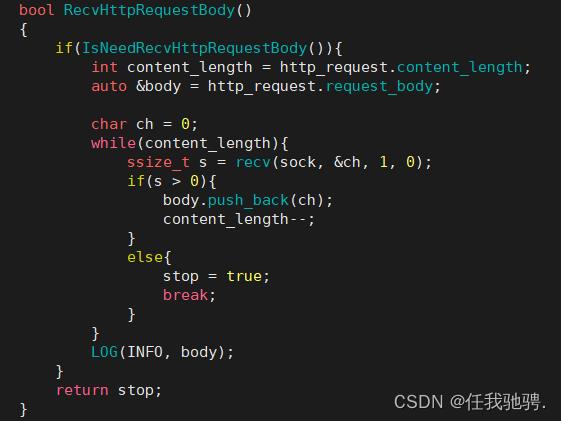
五、构建响应的预处理操作
浏览器给服务器发出一个http请求目的是让服务器完成某种任务,可能是想访问服务器上的某种资源(文本文件,视频,音频等等),也可能让服务器处理某些数据等等,服务器完成的结果是需要返回给我们的浏览器,文本文件的内容,视频,音频,或数据处理的结果都需要返回给浏览器,但服务器的处理结果是不能直接返回给浏览器,是需要构建一个http响应返回浏览器的,处理结果就放在http的响应正文中。
http响应的构建需要包含:响应行,响应报头,响应空行,响应正文。
构建响应行:版本 响应状态码 响应状态码描述
构建响应报头:构建响应报头至少需要构建 Content-Type 和
Content-Length属性,Content-Type描述的是服务器返回资源是什么类型,Content-Length描述的服务器返回的资源的大小。每种属性都以空行作为结尾。构建响应行:将响应报头和响应正文分隔开。
构建响应正文:存放文本文件的内容,视频,音频或数据的处理结果。
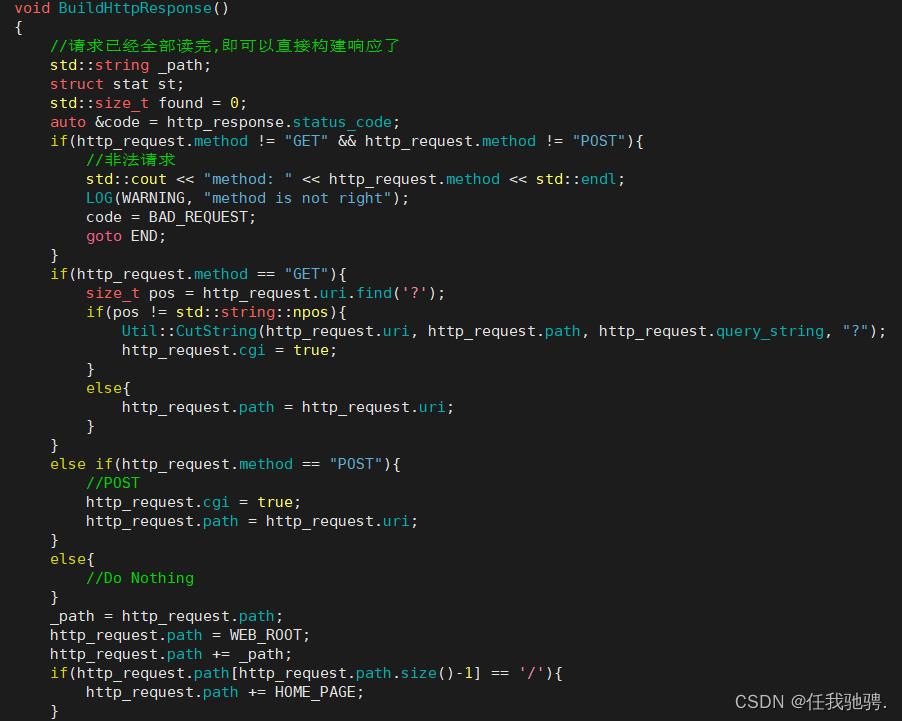
在我们构建响应之前,我们需要根据浏览器发出的http请求来找到我们服务器上的资源,也就是我们的请求路径path。path在解析URI中就已经处理好了,接下来我们直接用就可以了。
我们解析看到的path都是以/开头,此时就有一个问题,浏览器访问资源的路径是从服务器上的根目录下开始找的吗?答案是不一定,在哪里找资源取决于我们把所有资源放在哪一个目录下。举个例子:
我将我的服务器上所有的资源都放在wwwroot目录下,那么浏览器想要访问的服务器上的资源,就需要到wwwroot目录下去寻找资源
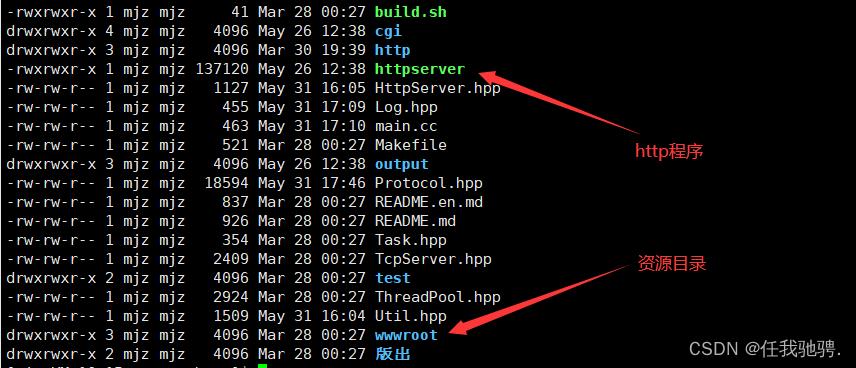
可浏览器发送过来的路径都是以根路径开始的,http进程是怎么到wwwroot目录下寻找资源?答案是http进程在接收到浏览器的访问路径是,首先会对路径进行修饰。比如请求路径是/test_cgi,修饰后路径就变为wwwroot/test_cgi,这样我们的http进程就回去wwwroot目录下查找资源。
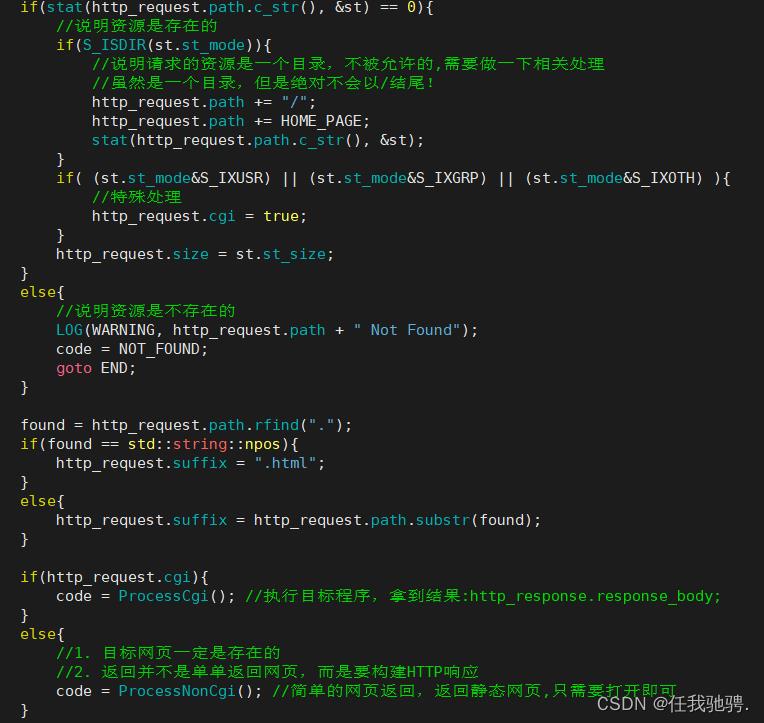
然后我们就需要判断该路径下的资源是否存在,如果不存在,就将状态码设置为404。如果存在的话就进行下一步判断,如果访问的是文本文件,就记录文件大小,构建一个http响应,如果是一个可执行程序,那么我们就将cgi标记为真,执行cgi内部的逻辑。如果访问的资源是一个目录呢?解决方法如下:
我们可以在每一个目录下建立一个index.html文件,这个文件代表的是该目录的首页,如果访问到该目录,并且没指明访问该目录的哪一个资源时,http就会直接将该目录下的index。html中的内容返回给浏览器。
除此之外,我们还需要构建响应报头中的Content-Type,所以再拿去已经找到的资源的后缀将其放进suffix中,如果没有后缀,则统一设置为".html",然后根据后缀去构建Content-Type。
六、返回网页
网页本质是一个超文本文件,也就是我们的前端代码,当返回这些代码给浏览器的时候,浏览器就会解析成一个网页。
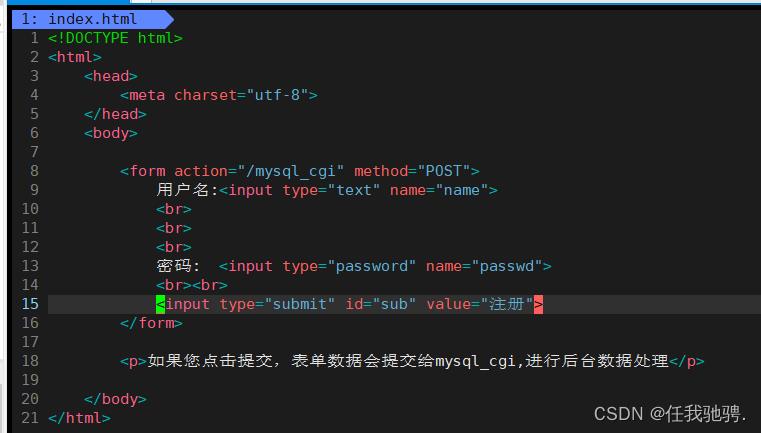

因此如果浏览器访问的资源是是一个文件,那么http进程就直接将该文本文件直接打开,等到发送的响应的时候直接通过sendfile将文件的内容发送给浏览器即可。

七、CGI机制
CGI机制的基本概念
CGI(Common Gateway Interface) 是WWW技术中最重要的技术之一,有着不可替代的重要地位。CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。
其实,要真正理解CGI并不简单,首先我们从现象入手
浏览器除了从服务器下获得资源(网页,图片,文字等),有时候还有能上传一些东西(提交表单,注册用户之类的),看看我们目前的http只能进行获得资源,并不能够进行上传资源,所以目前http并不具有交互式。为了让我们的网站能够实现交互式,我们需要使用CGI完成,时刻记着,我们目前是要写一个http,所以,CGI的所有交互细节,都需要我们来完成。
在我们实现上,要理解CGI,首先的理解GET方法和POST方法的区别
GET方法从浏览器传参数给http服务器时,是需要将参数跟到URI后面的,具体如下:

POST方法从浏览器传参数给http服务器时,是需要将参数放的请求正文的。我们稍后代码中演示。
GET方法,如果没有传参,http按照一般的方式进行,返回资源即可
GET方法,如果有参数传入,http就需要按照CGI方式处理参数,并将执行结果(期望资源)返回给浏览器
POST方法,一般都需要使用CGI方式来进行处理
一张图解释一下我们的HTTP CGI
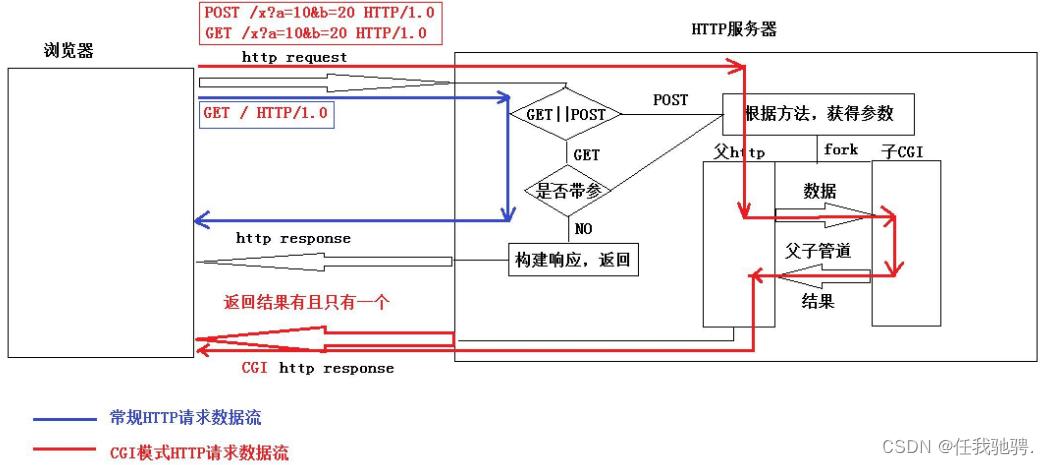
接下来,我们就可以完成剩下的代码了


(ps:putenv()函数的作用是导入环境变量)
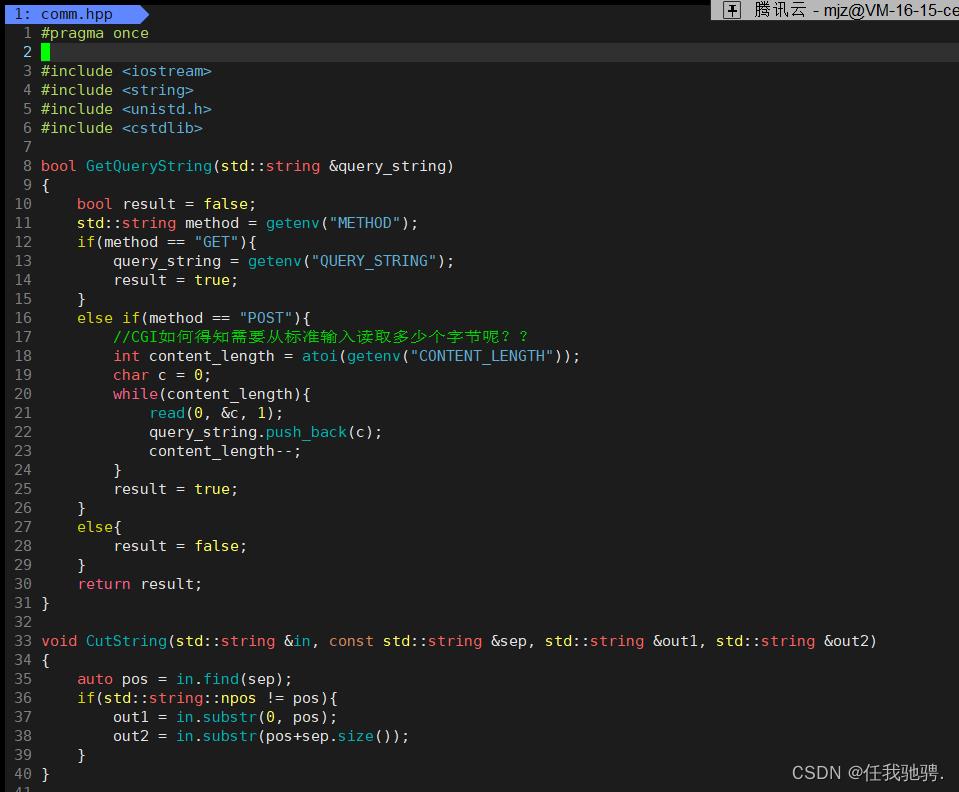
子cgi程序
八、构建响应
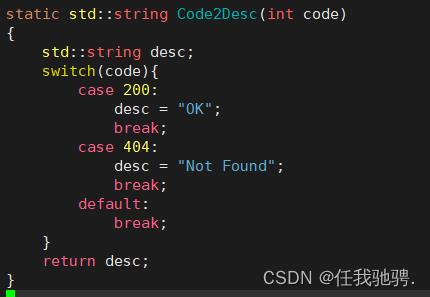
构建响应行:
当我们处理完cgi函数后和非cgi函数后,我们就已经确定状态码,所以我们就可以构建我们的响应行,在响应行中,版本,状态码和状态码描述两两之间是以空格分隔开的,最后响应行以\\r\\n结尾。

构建OK的响应报头:
根据之前解析出来的资源后缀,我们就可以通过后缀判断出返回的资源是一个什么样的类型,接下来就可以构建出报头中的Content-Type,最后在以”\\r\\n"结尾
ContentTypeTable()函数可以根据后缀类型判断相应的文件类型并返回
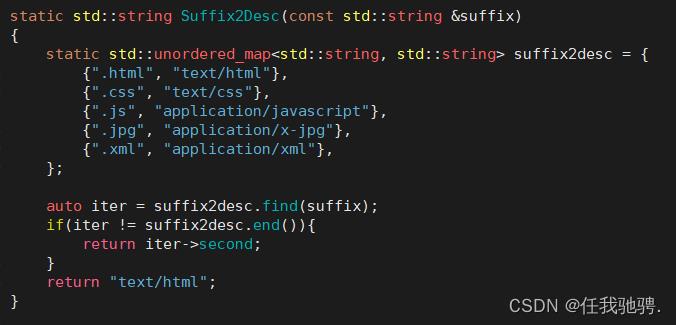
接下来就开始构建Content-Length,构建Contnet-Length需要根据cgi去判定,如果之前是cgi处理,那么它之前处理的结果已经放进了响应正文中了,也就是response_body,所以Content-Length就是我们response_body的大小,如果是非cgi处理,那么它就直接将文件中的所有内容返回给浏览器,文件的大小放在http_response.size,所以Content-Length就是http_response.size.最后在以”\\r\\n"结尾。
九、发送响应
构建完响应后,我们就需要响应中的响应行,响应报头,响应空行,和响应正文依次发送给浏览器。在发送响应正文的时候,如果是cgi处理,cgi的处理结果已经放进响应正文中,所以直接将其发送给sock即可,如果是非cgi处理(返回错误页面,返回请求网页),因为之前未构建响应正文,但我们已经将需要返回的网页已经打开,所以在发送响应行,响应报头,响应空行后,我们最后再将文件中的内容发送出去
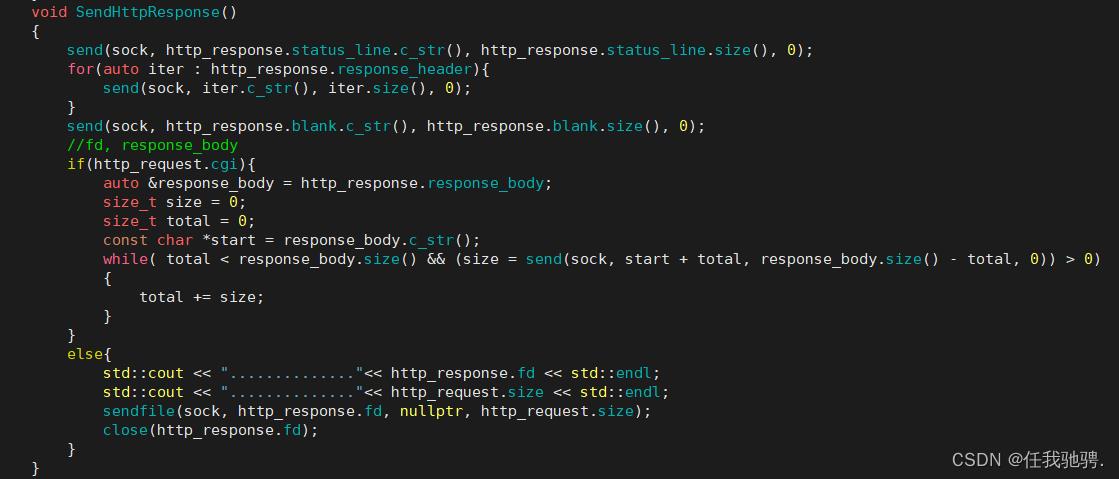
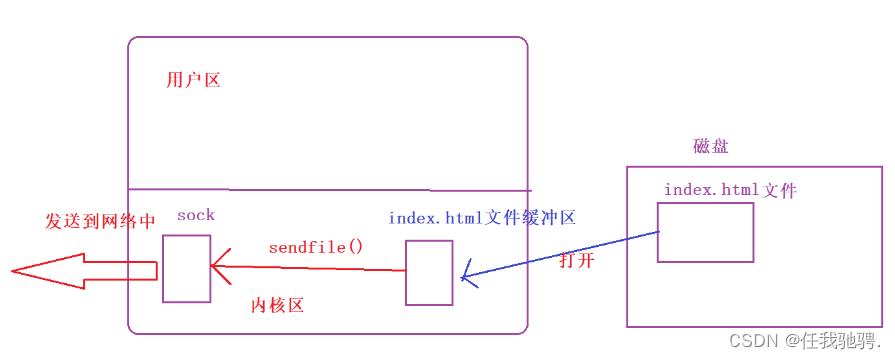
为什么非cgi处理(返回错误页面,或者返回请求网页)不直接将文件内容存放到响应正文response_body中,而是使用sendfile()函数发送给浏览器呢?
sendfile()函数可以将内核中的文件缓冲区直接拷贝给另一个文件缓冲区,如下:
十、处理错误
如果是服务器处理的逻辑错误,例如创建子进程失败,http请求路径错误等,那么我们直接返回一个错误页面即可,但如果是服务器在读http请求的时候,服务器读到一半请求,浏览器就将连接关掉,那么此时服务器就可能会崩掉,因此服务器读到错误的请求的时候,服务器中不会对http请求进行处理,然后关掉该连接即可
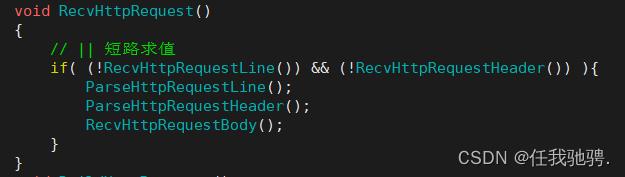
如果读取正文失败,就会设置stop为真,然后就不会构建响应和发送响应,直接与浏览器连接给关闭
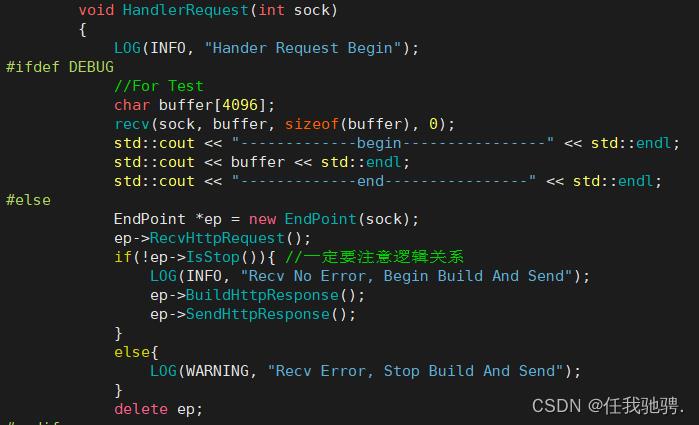
如果是服务器正往sock中写入,而浏览器将连接关掉后,那么浏览器就会收到一个SIGPIPE的信号,此时服务器就会崩掉,因此我们在初始化服务器的时候需要忽略该SIGPIPE信号。
十一、套接字编程
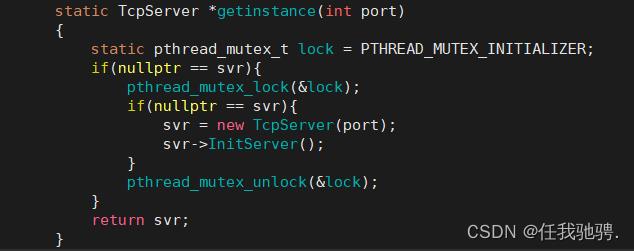
我们这里使用单例模式创建TcpServer对象进行编程,用于我们这个服务器进行网络通信,用单例模式是为了可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序的模块共享,简化了在复杂环境下的配置管理
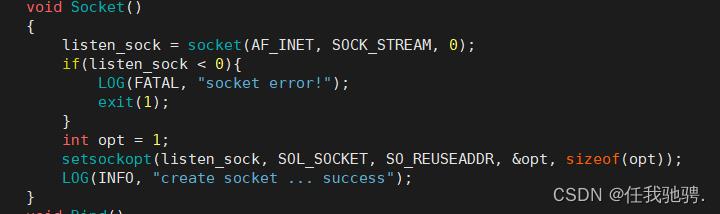
接下来,我们先创建套接字,打开一个网络通讯端口,就像open()一样返回一个文件描述符,这样应用程序就可以像读写文件一样用read/write在网络上收发数据;
这里对于IPv4,family参数指定为AD_INET。
接着,我们绑定端口号bind(),服务器程序所监听的网络地址和端口号通常是固定不变的,客户端程序得知服务器程序的地址和端口号后就可以向服务器发起连接;服务器需要调用bind绑定一个固定的网络地址和端口号。
bind()的作用是将参数sockfd和myaddr绑定在一起,使sockfd这个用于网络通讯的文件描述符监听myaddr所描述的地址和端口号。

再然后我们listen()声明sockdf处于监听状态,并且最多允许拥有backlog个客户端处于连接等待状态。如果有更多则忽略
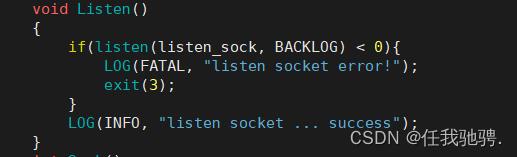
到这里我们的TcpServer就初始化完毕,到我们后面的启动程序再使用。
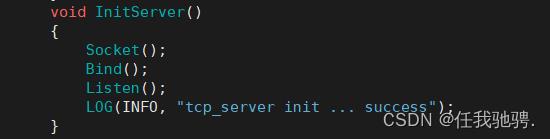
十二、线程池优化
我们先来介绍一下线程池。它是一种线程使用模式, 线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护者多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保持内核的充分利用,还能防止过分调度。可用线程数量取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
适合的应用场景:
- 需要大量的线程来完成任务,且完成任务的时间比较短。WEB服务器完成网页请求这样的任务,使 用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。 但对于 长时间的任务,比如一个Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间太多了。
- 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没 有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程 可能使内存到达极限,出现错误.
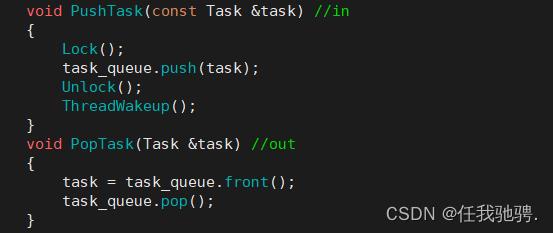
对于我们这个项目,我们先将任务队列要做的什么先处理好,通过回调来处理我们的sock网络请求:
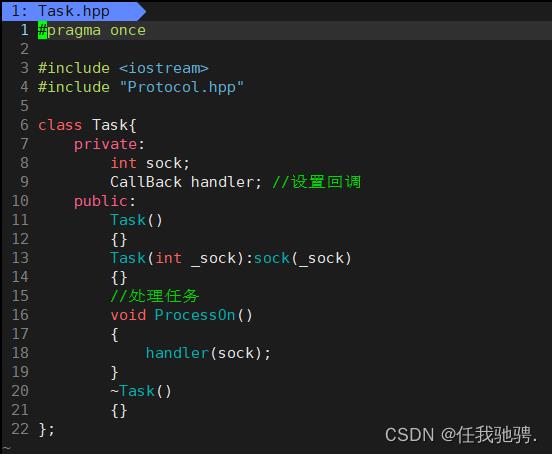
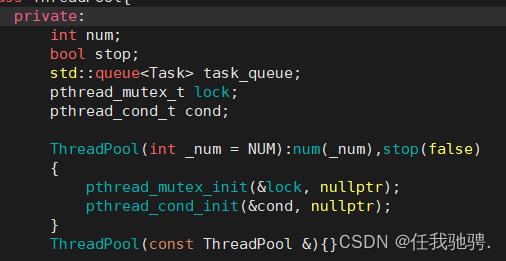
然后我们再完成我们线程池的创建,我们的线程池使用的是queue空间适配器进行线程的使用,方便调度。因为我们这项目用于web服务器的测试搭建,所以线程池的数量较少。
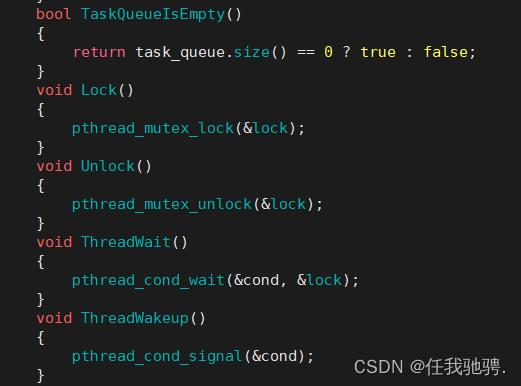
因为我们单个线程在执行任务时,为防止其他线程来抢占,所以我们要用互斥锁和条件变量来进行控制,使线程能够同步正确的执行任务。
这里我们也通过单例模式来初始化线程池对象,便于我们对它进行配置和管理。这里使用双重判定空指针,降低锁冲突的概率。使用互斥锁,保证多线程的情况下也只调用一次new。
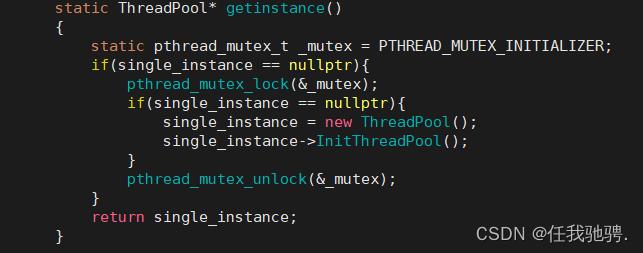
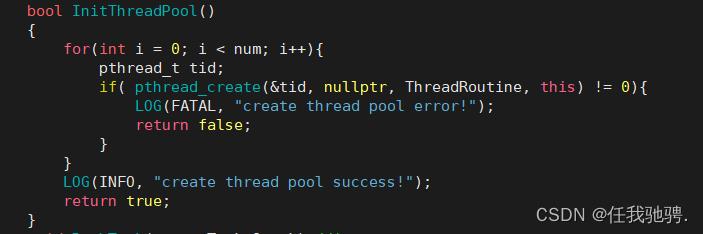
接下来是将互斥锁和条件变量相关的函数进行封装,方便我们去调用。
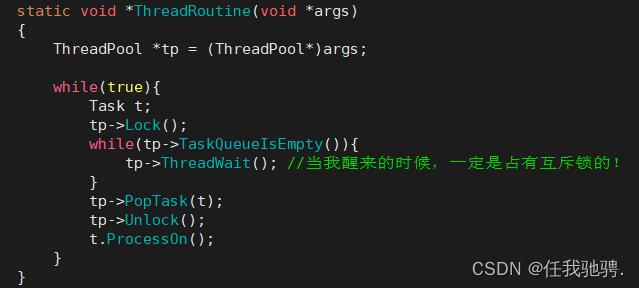
当我们有任务到来时,先将其放入我们的阻塞队列,然后线程池进行判断,当任务队列不为空时,我们就将对应的线程进行唤醒进行任务处理,将任务处理完成后若任务队列里还有任务的话就继续处理任务,直到所有任务全部都处理完成出队列之后,我们的线程再次进入等待状态。
这里附上Gitee链接:web服务器项目
以上是关于自主实现的web服务器的主要内容,如果未能解决你的问题,请参考以下文章