Redis原理和Jedis
Posted F3nGaoXS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis原理和Jedis相关的知识,希望对你有一定的参考价值。
Redis原理和Jedis
Redis是什么?
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。(B/S架构)
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis的优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
安装Redis
Windows环境下安装
-
下载压缩包
github:https://github.com/tporadowski/redis/releases
-
解压缩
-
配置环境变量
添加REDIS_HOME系统变量:
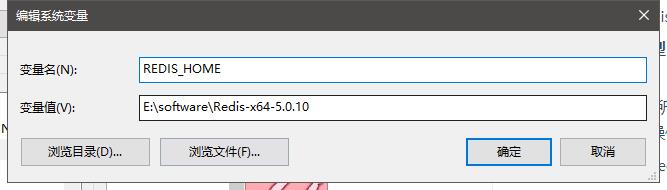
再配置环境变量path(即在path中添加):
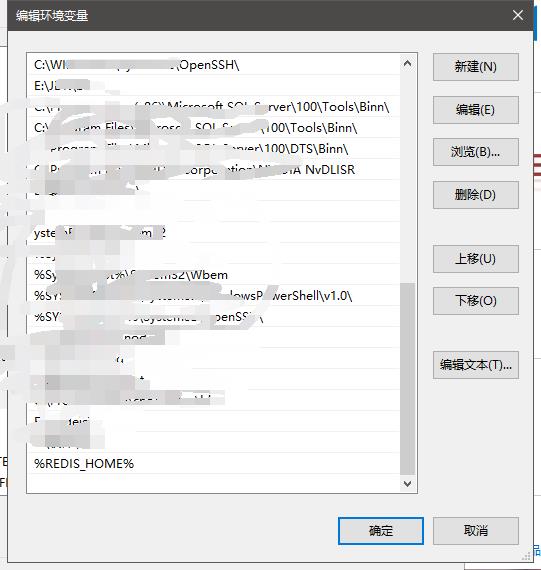
-
试运行
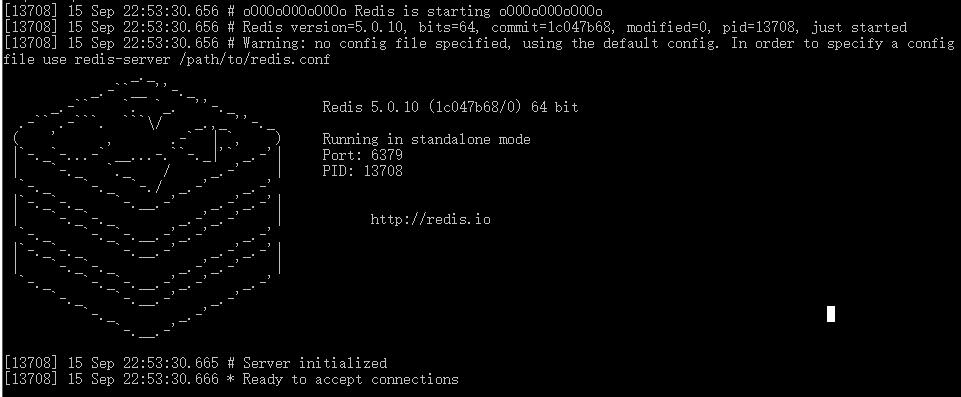
尝试在任何地方使用cmd运行如下命令:
redis-server如果出现如下内容则证明redis安装成功并且环境变量配置成功:
linux环境下安装
Redis默认端口号:6379
Redis服务端
服务端启动Redis服务
-
前台启动
redis-server -
后台启动
redis-server & -
指定配置文件启动
redis-server <config_name> [&] (是否后台启动)
服务端停止Redis服务
redis-cli shutdown
Redis客户端
Redis分为客户端和服务端。客户端用于连接Redis服务,并且向Redis服务端发送命令。
启动cli客户端
使用以下命令即可启动redis的客户端程序
redis-cli #默认连接127.0.0.1:6379的redis服务
[-p port] #指定端口号
[-h hostname] #指定主机地址
退出cli客户端
exit [quit]
Redis基本知识
服务端测试Redis性能
redis-benchmark
客户端查看Redis服务是否正常运行
127.0.0.1:6379>ping
PONG #返回PONG说明Redis服务正常运行
客户端查看Redis服务的统计信息
127.0.0.1:6379>info #返回redis服务的所有相关信息
[section] #查看具体某一指定端的信息
Redis数据库实例
Redis的数据库实例只能由Redis服务来创建和维护,开发人员不能修改和自行创建数据库实例。默认情况下,Redis会自动创建16个数据库实例,并且这些数据库实例由编号来区别,由0—15来使用。Redis的数据库实例本身占用的存储空间很少。Redis客户端默认连接的是编号为0的数据库实例。
客户端切换数据库实例
127.0.0.1:6379>select [index] #根据编号切换数据库实例
客户端查看数据库实例记录数(key的数量)
127.0.0.1:6379>dbsize
(integer) 2 #返回key的数量
客户端查看当前数据库实例所有key
127.0.0.1:6379>keys [pattern] [*] # * 所有
1) "key:__rand_int__"
2) "k1" #返回有哪些key
客户端清空当前数据库实例
127.0.0.1:6379>flushdb
客户端清空所有数据库实例
127.0.0.1:6379>flushall
客户端查看当前Redis服务的配置信息
127.0.0.1:6379>config get [param] [*]
Redis的五种数据结构
Redis支持五种数据类型:string(字符串),list(列表),hash(哈希),set(集合)及zset(sorted set:有序集合)。
string(字符串)
string是redis最基本的类型,一个key对应一个value,是二进制安全的。可以包含任何数据,比如jpg图片或者序列化的对象。
最大能存储512MB
cli> set key value
127.0.0.1:6379> SET runoob "菜鸟教程"
127.0.0.1:6379> GET runoob
"菜鸟教程"
list(列表)
简单的字符串列表,按照插入顺序排序,可以添加元素到头部或者尾部
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
cli> lpush key member
cli> lrange key start end #从start到end遍历key列表
127.0.0.1:6379> lpush runoob redis
127.0.0.1:6379> lpush runoob mongodb
redis 127.0.0.1:6379> lrange runoob 0 10
1) "mongodb"
2) "redis"
set(集合)
字符串的无序集合(基于哈希表实现,故不能插入重复的value)。
cli> sadd key member #成功返回1,失败返回0(如重复)
cli> smembers key #遍历key集合
127.0.0.1:6379> sadd runoob redis
127.0.0.1:6379> sadd runoob mongodb
127.0.0.1:6379> smembers runoob
1) "redis"
2) "mongodb"
hash(哈希)
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
每个 hash 可以存储 232 -1 键值对(40多亿)。
#存入key对象,其中属性field1的值为value1,属性filed2的值为value2
cli> HMSET key field1 value1 field2 value2
#获取key对象中属性为filed的值value
cli> HGET key filed
127.0.0.1:6379> HMSET runoob field1 "Hello" field2 "World"
"OK"
127.0.0.1:6379> HGET runoob field1
"Hello"
127.0.0.1:6379> HGET runoob field2
"World"
zset(有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数(score)。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
cli> zadd key score member
cli> zrangebyscore key start end #根据具体分数(score必须在start和end范围内)排序
cli> zrange key start end #排序(根据分数)
redis 127.0.0.1:6379> zadd runoob 0 redis
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 mongodb
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabbitmq
(integer) 1
redis 127.0.0.1:6379> zadd runoob 0 rabbitmq
(integer) 0
redis 127.0.0.1:6379> ZRANGEBYSCORE runoob 0 1000
1) "mongodb"
2) "rabbitmq"
3) "redis"
Redis命令的基本语法
cli> COMMAND KEY_NAME
COMMAND是命令,KEY_NAME是键
如
127.0.0.1:6379> DEL runoobkey
DEL是删除命令,runoobkey是一个键,该命令的目的是删除runoobkey
Redis关于key的命令
查询key的命令(keys)
基本语法格式
cli> keys [pattern] #pattern是匹配规则
[*] #匹配0个或者多个字符
[?] #只匹配1个字符
[[]] #只匹配[]中的1个字符
[a*] #以'a'字符开始的key
[a*b] #以'a'开始,'b'结尾的key
如
127.0.0.1:6379> keys * #查看所有key
1) "ageZset"
2) "name"
3) "osList"
4) "citySet"
5) "key:__rand_int__"
6) "k1"
127.0.0.1:6379> keys k* #查看以'k'字符开头的key
1) "key:__rand_int__"
2) "k1"
127.0.0.1:6379> keys a*t #查看以'a'开头,t结尾的key
1) "ageZset"
127.0.0.1:6379> keys n?me #查看第1个字符为n,第34字符为me的key
1) "name"
127.0.0.1:6379> keys n[abc]me #查看第1个字符为n,第2个字符为[abc]其中一个,第34字符为me的key
1) "name"
判断key是否存在(exists)
cli> exists key [key key key...] #判断key是否存在
#存在返回1(或存在的数量),否则返回0
如
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379> exists name osList ageZset citySet
(integer) 4
127.0.0.1:6379> exists name osList ageZset citySet test
(integer) 4
移动key到指定的数据库实例(move)
cli> move key index #移动key到index数据库实例
查看key剩余生存时间(ttl)
单位是秒。(TTL:time to live)
cli> ttl key #查看key的剩余生存时间
#返回-1,永不过期(默认)
#返回-2,key不存在
设置定key的生存时间(expire)
cli> expire key seconds #给key设置生存时间seconds秒(超出即被删除)
查看key的数据类型(type)
cli> type key #查看key的数据类型
重命名key(rename)
cli> rename key newkey
删除key(del)
cli> del key [key key key...]
#返回成功删除key的条数
总结
- 增
- 删
- del:删除key
- 改
- move:移动key
- expire:设置key的生存时间
- rename:重命名
- 查
- keys:查询key
- exists:判断key是否存在
- ttl:查询key的剩余生存时间
- type:查看key的数据类型
Redis操作string类型
单key——单value
存string类型数据(set)
cli> set key value
#如果key已经存在,会发生覆盖
取string类型数据(get)
cli> get key
追加字符串(append)
cli> append key value #往key中追加字符串value
#返回值是追加后字符串长度
#如果key不存在,相当于set
获取字符串长度(strlen)
cli> strlen key #返回key的字符串长度
将字符串数值进行加1运算(incr)
cli> incr key #key的value+1并且返回
Tips:
- 如果key不存在,则先创建该key-value,value初始化为0然后+1
- key的value必须是数值,否则报错
将字符串数值进行减1运算(decr)
cli>decr key
与incr同理
将字符串数值进行加offset(指定数值)运算(incrby)
cli>incrby key offset #key的vaule+offset并且返回
将字符串数值进行减offset(指定数值)运算(decrby)
cli>decrby key offset #key的vaule-offset并且返回
获取字符串中字符串(getrange)
cli>getrange key startIndex endIndex
#截取key中value从startIndex到endIndex
设置字符串中字符串(setrange)
会改变数据库中的值
cli>setrange key startIndex value
#用value覆盖从下标为startIndex开始的字符串
设置字符串的同时设置生命周期(setex)
cli>setex key seconds value
#给key-value设置seconds秒后过期
cli> setex k1 30 v1
OK
cli> ttl k1
(integer) 27
设置字符串数据当key不存在才设置,key存在则不设置(setnx)
cli>setnx key value
批量设置字符串数据(mset)
cli>mset key1 value1 key2 value2 key3 value3 ...
批量获取字符串数据(mget)
cli>mget key1 key2 key3 ...
总结
Redis操作string类型
- 增
- set:最基本的存储string类型数据的方式(如果存在则会覆盖)
- setex:存储数据的同时设置生命周期
- setnx:如果存在则不存储
- mset:批量存储
- 删
- 改
- set:修改string类型的数据(如果存在则会覆盖,也就是修改)
- append:在原有的基础上追加数据
- incr:数值字符串增加
- decr:数值字符串减少
- setrange:修改字符串中指定下标的数据
- 查
- get:获得数据
- mget:批量获得数据
- getrange:获得字符串中子串
- strlen:字符串长度
Redis操作list类型
单key——多有序value。顺序跟插入元素的顺序有关
从左侧起存list类型数据(lpush)
依次往左侧(头部)添加元素
cli>lpush key value [value value...]
cli> lpush list1 1 2 3 4
(integer) 4
cli> lrange list1 0 4
1) "4"
2) "3"
3) "2"
4) "1"
#可以看到lpush的顺序后插入的元素在列表中越靠前
从右侧起存list类型数据(rpush)
依次从右侧(尾部)添加元素
cli>rpush key value [value value...]
获取指定列表中指定下标区间的元素(lrange)
cli>lrange key startIndex endIndex
#获取key列表中startIndex到endIndex的元素
cli> lrange list1 0 4
1) "4"
2) "3"
3) "2"
4) "1"
cli> lrange list1 0 -1 #获取从头到尾的全部元素,-1表示倒数第一个,即尾部
1) "4"
2) "3"
3) "2"
4) "1"
从指定列表中移除并返回表头(左侧)元素(lpop)
cli> lpop key
从指定列表中移除并返回表尾(右侧)元素(rpop)
cli> rpop key
获取列表中指定下标的元素(lindex)
cli> lindex key index
获取指定列表的长度(元素个数)(llen)
cli> llen key
移除指定列表中数据(lrem)
cli>lrem key count value
#移除key列表count个中值为value的元素
# count > 0 从左侧起移除
# count < 0 从右侧起移除
# count = 0 移除所有
总结
Redis操作list类型
- 增
- lpush:从左边添加元素
- rpush:从右边添加元素
- 删
- lpop:从左边弹出元素
- rpop:从右边弹出元素
- lrem:移除指定元素
- 改
- 查
- lrange:遍历
- lindex:指定下标的元素
- llen:长度
Redis操作set类型
单key——多无序且不可重复value
将一个或多个元素添加到指定集合中(sadd)
cli> sadd key value [value value ...] #若元素重复,则忽略
cli> sadd set1 a b c a
(integer) 3 #成功添加元素的个数
#只添加成功三个
获取指定集合中的元素(smembers)
cli> smembers key
cli> smembers set1
1) "c"
2) "b"
3) "a"
判断元素在集合中是否存在(sismember)
cli> sismember key member
(integer) 1 #返回1则存在
(integer) 0 #返回0则不存在
获取集合的长度(scard)
cli> scard key
移除集合中1个或者多个元素(srem)
cli> srem key member [member ...]
#返回成功移除的元素的个数
随机获取集合中的一个或多个元素(srandmember)
cli> srandmember key [count]
#count>0 随机获取的元素不会重复
#count<0 随机获取的元素可能重复
随机移除集合中的一个或多个元素(spop)
cli> spop key [count]
将集合中的元素移动到另一集合(smove)
cli> smove source dest member #将source集合中的member移动到dest集合
获取集合的差集(sdiff)
即一个集合中有,但是其他集合中没有的元素
cli> sdiff key1 key2 [key3 ...]
#即key1集合中有,其他集合中没有的元素
cli> smembers set1
1) "f"
2) "c"
3) "e"
4) "g"
5) "a"
6) "b"
cli> smembers set2
1) "d"
2) "c"
3) "g"
4) "f"
5) "e"
6) "i"
7) "b"
8) "a"
9) "h"
cli> sdiff set2 set1 #set2中有hid,但是set1中没有
1) "i"
2) "d"
3) "h"
获取集合的交集(sinter)
即指定集合中都有的元素
cli> sinter key key [key key...]
127.0.0.1:6379> smembers set1
1) "f"
2) "c"
3) "e"
4) "g"
5) "a"
6) "b"
127.0.0.1:6379> smembers set2
1) "d"
2) "c"
3) "g"
4) "f"
5) "e"
6) "i"
7) "b"
8) "a"
9) "h"
127.0.0.1:6379> sinter set1 set2
1) "f"
2) "c"
3) "e"
4) "g"
5) "a"
6) "b"
#set1和set2中都有abcefg
获取集合的并集(sunion)
即指定集合中的所有元素
cli> sunion key key [key key...]
总结
Redis操作set类型
- 增
- sadd:新增元素到集合中
- 删
- srem:移除元素
- spop:弹出元素
- smove:移动过元素到另一集合
- 改
- sadd:新增元素到集合中,如果value已经存在则会覆盖
- 查
- smembers:遍历集合元素
- sismember:判断元素是否存在
- scard:集合长度
- srandmember:随机获取集合元素
- sdiff:差集
- sinter:交集
- sunion:并集
Redis操作hash类型
单key——field-value
field-value
field-value
适合存储对象
将一个或多个field-value(属性—值)对存入hash表,会覆盖(hset)
如果key中的filed之前是存在的,则会强制覆盖(使用hsetnx不会强制覆盖)
cli> hset key field1 value1 [field2 value2 ...]
cli> hset student1 name wqk age 20
(integer) 2
获取指定hash表中指定field值(hget)
cli> hget key field #获取key哈希表中field的值
cli> hget student1 name
"wqk"
批量获取指定hash表中field的值(hmget)
cli> hmget key field1 [field2 field3 ...]
cli> hmget student1 name age
1) "wqk"
2) "20"
获取hash表中所有的field和value(hgetall)
cli> hgetall key
cli> hgetall student1
1) "name"
2) "wqk"
3) "age"
4) "20"
移除hash表中指定一个或者多个field(hdel)
cli> hdel key field1 [field2 field3 ...]
统计hash表中field数量(hlen)
cli> hlen key
判断hash表中是否存在某field(hexists)
cli> hexists key field
#返回0表示不存在,1表示存在
获取hash表中所有的field列表(hkeys)
cli> hkeys key
cli> hkeys student2
1) "id"
2) "name"
3) "age"
获取hash表中所有的value(hvals)
cli> hvals key
cli> hvals student2
1) "10001"
2) "test"
3) "18"
对hash表中指定field的value进行整数加法运算(hincrby)
cli> hincrby key field incrment
#对key哈希表中的field属性的值进行加incrment值运算
cli> hget student2 age
"18"
cli> hincrby student2 age 2
(integer) 20
对hash表中指定field的value进行浮点数加法运算(hincrbyfloat)
cli> hincrbyfloat key field incrment
cli> hset student2 score 85
(integer) 1
cli> hincrbyfloat student2 score 1.5
"86.5"
将一个或多个field-value(属性—值)对存入hash表,不会覆盖(hsetnx)
如果key的field已经存在则放弃设置
cli> hsetnx key filed1 value1 [field2 value2]
总结
Redis操作hash类型
- 增
- hset:存入hash类型数据
- hsetnx:存入数据,如果存在则不存入
- 删
- hdel:删除hash表中field及其value
- 改
- hset:存入hash类型数据,如果field存在则会覆盖
- hincrby:value是数值,则会增加
- 查
- hget:获取hash表中指定field的value
- hmget:批量获取hash表中指定field的value
- hgetall:获取hash表中所有field及其value
- hlen:获取hash表中field的数量
- hexists:判断hash表中该field是否存在
- hkeys:获取hash表中所有field
- hvals:获取hash表中所有value
Redis操作zset类型
有序集合。顺序跟score有关
将一个或多个member及其score值加入有序集合(zadd)
score必须是数值。如果member已经存在,则会覆盖
cli> zadd key score member [score member]
cli> zadd zset1 95 wqk 90 lk 98 zp
(integer) 3
获取有序集合中指定下标区间的元素(zrange)
cli> zrange key startIndex endIndex [withscores] #获取key集合startIndex到endIndex区间的元素(是否显示分数)
获取有序集合中指定分数区间(闭区间)的元素(zrangebyscore)
cli> zrangebyscore key min max [withscores] #获取key集合min到max分数区间的元素(是否显示分数)
删除有序集合中一个或者多个元素(zrem)
cli> zrem key member [member]
获取有序集合中元素个数(zcard)
cli> zcard key
获取有序集合中分数在指定区间的元素个数(zcount)
cli> zcount key min max #获取key有序集合中min到max区间的元素个数
获取有序集合中指定元素的排名(升序)(zrank)
cli> zrank key member
获取有序集合中指定元素的排名(降序)(zrevrank)
cli> zrevrank key member
获取有序集合指定元素的分数(zscore)
cli> zscore key member
总结
Redis操作zset类型
- 增
- zadd:往集合中存入元素
- 删
- zrem:移除集合中的元素
- 改
- 查
- zrange:遍历集合元素
- zrangebyscore:根据score遍历集合元素
- zcard:集合元素个数
- zcount:指定分数区间元素个数
- zrank:元素的排名(正序)
- zrevrank:元素的排名(倒序)
- zscore:元素的分数
Redis配置文件
Redis根目录下有个默认的配置文件:.\\redis.conf,里面有一些redis默认的配置参数
cli> redis-server [config_name] #默认使用默认的配置的文件
网络配置
-
port
指定redis服务所使用的端口号,默认6379
-
bind
指定客户端连接redis服务时,所能使用的主机地址,默认是redis服务所在主机名,一般情况下都需要指定主机名
-
tcp-keeplive
TCP连接保活策略,单位是秒。指的是Redis服务端会在指定秒内向连接他的客户端发送一次ACK请求,以确保连接有效。默认是60秒
如果以上配置在配置文件中生效,则在客户端中连接需使用:
redis-cli -h bind -p 6380
常规配置
-
loglevel
配置日志级别,分为四个级别:debug、verbose、notice、warning。默认是notice
-
logfile
日志文件持久化存储的地方。默认不会持久化,只会输出到终端
-
databases
配置Redis服务默认创建的数据库实例个数。默认是16个。
安全配置
-
requirepass
配置Redis客户端访问Redis服务时的密码,需要
protected-mode = yes时生效
如配置了requirepass,则在客户端连接中需使用:
redis-cli [-h hostname] [-p port] [-a pwd]
Redis数据持久化
Redis提供持久化策略,可以在适当的时机采用适当的手段把内存中的数据持久化的磁盘。
RDB策略(Redis默认启用的持久化策略)
RDB(Redis DataBase)策略是指,在指定时间间隔内,Redis服务执行指定次数的写操作,会自动触发一次持久化操作。如需修改可以在redis的配置文件中修改RDB相关的配置(dbfilename持久化数据的文件名,默认是dump.rdb,dir持久化数据的目录,默认是./,即根目录)。
AOF策略
记录每一次Redis服务的完整写操作进入日志,每次Redis服务启动时,都会重新执行一遍完整的操作日志以便恢复数据。效率不高,默认不开启AOF(appendonly配置是否开启AOF策略,appendfilename配置操作日志文件)。
Redis事务
数据库事务:一组对数据库的操作一起执行,保证操作的原子性,要么同时成功,要么同时失败。
Redis事务:允许一组Redis命令放在一起,将命令序列化,然后按队列执行,保证部分原子性。
multi
标记一个Redis事务的开始(与exec成对存在)。
exec
标记一个Redis事务的结束(与multi成对存在),即立即开始执行上述事务。
一个完整的Redis事务的输入格式应该是如下
cli> multi #标识事务开始了
cli> set k1 v1 #操作1
cli> set k2 v2 #操作2
cli> exec #标识事务结束了(即立即开始执行)
cli> multi
OK #事务开启
cli> set str1 value1
QUEUED #操作1加入队列
cli> set str2 value2
QUEUED #操作2加入队列
cli> exec
1) OK #操作1执行结果
2) OK #操作2执行结果
Tips:
Redis事务不是脚本命令。而是在cli执行
multi后接着一行一行输入操作的命令(操作会插入队列),最后执行exec才会按队列执行上述操作。为保证事务的部分原子性,Redis事务遵循以下两则规则:
输入
以上是关于Redis原理和Jedis的主要内容,如果未能解决你的问题,请参考以下文章