《搜索和推荐中的深度匹配》——经典匹配模型 2.1 匹配学习
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《搜索和推荐中的深度匹配》——经典匹配模型 2.1 匹配学习相关的知识,希望对你有一定的参考价值。
2. 经典匹配模型
已经提出了使用传统的机器学习技术进行搜索中的查询文档匹配和推荐中的用户项目匹配的方法。这些方法可以在一个更通用的框架内形式化,我们称之为“学习匹配”。除了搜索和推荐外,它还适用于其他应用,例如释义,问题解答和自然语言对话。本节首先给出学习匹配的正式定义。然后,它介绍了传统学习以匹配为搜索和推荐而开发的方法。最后,它提供了该方向的进一步阅读。
2.1 匹配学习
2.1.1 匹配函数
匹配问题的学习可以定义如下。假设存在两个空间X和Y。在两个空间 x ∈ X x∈X x∈X和 y ∈ Y y∈Y y∈Y的两个对象上定义了一个匹配函数 F = f ( x , y ) F = f(x,y) F=f(x,y),其中每个函数 f : X × Y → R f:X×Y →R f:X×Y→R表示两个对象x和y之间的匹配程度。两个对象x和y及其关系可以用一组特征 Φ ( x , y ) Φ(x,y) Φ(x,y)来描述。
匹配函数f(x,y)可以是特征的线性组合:

其中w是参数向量。它也可以是广义线性模型,树模型或神经网络。
2.1.2 匹配学习函数
可以采用监督学习来学习匹配函数f的参数,如图2.1所示。

监督学习的匹配通常包括两个阶段:离线学习和在线匹配。在离线学习中,给出了一组训练实例
D
=
(
x
1
,
y
1
,
r
1
),
.
.
.
,(
x
N
,
y
N
,
r
N
)
D = \\ (x_1,y_1,r_1),...,(x_N,y_N,r_N)\\
D=(x1,y1,r1),...,(xN,yN,rN),其中
r
i
r_i
ri是指示对象之间匹配程度的布尔值或实数
x
i
x_i
xi和
y
i
y_i
yi,N是训练数据的大小。进行学习以选择可以在匹配中表现最好的匹配函数f∈F。在在线匹配中,给定一个测试实例(一对对象)
(
x
,
y
)
∈
X
×
Y
(x,y)∈X×Y
(x,y)∈X×Y,学习到的匹配函数f用来预测对象对之间的匹配度,表示为
f
(
x
,
y
)
f(x,y)
f(x,y)。
与其他监督学习问题类似,我们可以将学习匹配的目标定义为最小化损失函数,该函数表示匹配函数在训练数据和测试数据上可以达到多少精度。更具体地,给定训练数据D,学习等于解决以下问题:
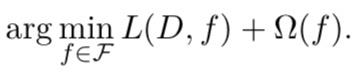
目标由两部分组成:经验损失
L
(
D
,
f
)
L(D,f)
L(D,f)衡量匹配函数f对训练数据产生的总损失,而正则化器
Ω
(
f
)
Ω(f)
Ω(f)防止过拟合训练数据。通常选择
Ω
(
f
)
Ω(f)
Ω(f)来惩罚f的复杂度。流行的正则化器包括l1,l2以及它们的混合。
经验损失函数 L ( D , f ) L(D,f) L(D,f)的不同定义导致不同类型的学习以匹配算法。文献中已广泛使用三种类型的损失函数,分别称为点向损失函数(pointwise loss function),成对损失函数(pairwise loss function)和列表损失函数(listwise loss function)【1】。接下来,我们简要描述三种类型的损失函数。
Pointwise Loss Function
Pointwise Loss Function 仅在一个实例(即源对象和目标对象)上定义。假设存在一对真正匹配度为r的对象 ( x , y ) (x,y) (x,y)。此外,假设由匹配模型给出的 ( x , y ) (x,y) (x,y)的预测匹配度是 f ( x , y ) f(x,y) f(x,y)。逐点损失函数定义为表示匹配度之间差异的度量,表示为 l p o i n t ( r , f ( x , y )) l^point(r,f(x,y)) lpoint(r,f(x,y))。$ f(x,y)$与r越近,损失函数的值越小。
在学习中,给定训练数据集
D
=
(
x
1
,
y
1
,
r
1
),
.
.
.
,(
x
N
,
y
N
,
r
N
)
D = \\(x_1,y_1,r_1),... ,(x_N,y_N,r_N)\\
D=(x1,y1,r1),...,(xN,yN,rN),我们将训练数据的总损失或对象对损失的总和最小化:
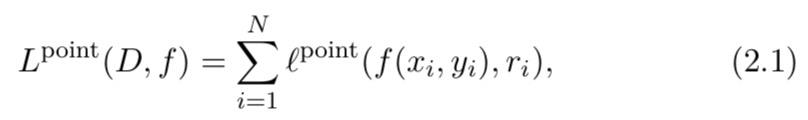
其中
r
i
r_i
ri是训练实例
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的真实匹配度。
作为 Pointwise Loss Function 的一个示例,均方误差(MSE)是广泛使用的损失函数。给定一个带标签的实例
(
x
,
y
,
r
)
(x,y,r)
(x,y,r)和匹配模型f,MSE定义为:

另一个例子是交叉熵损失函数。交叉熵损失函数假设
r
∈
0
,
1
r∈0,1
r∈0,1,其中1表示相关,否则为0。进一步假设
f
(
x
,
y
)
∈
[
0
,
1
]
f(x,y)∈[0,1]
f(x,y)∈[0,1]是x和y相关的预测概率。然后,交叉熵损失定义为:

Pairwise Loss Function
假设有两对对象 ( x , y + ) (x,y ^+) (x,y+)和 ( x , y − ) (x,y ^-) (x,y−),其中一个对象x是共享的。我们称x源对象(例如查询或用户)、 y + y^+ y+和 y − y^- y−为目标对象(例如文档或项目)。进一步假设在给定对象x的情况下,在对象 y + y^+ y+和 y − y^- y−之间存在顺序,表示为 r + > r − r^+> r^- r+>r−。在此, r + r^+ r+和 r − r^- r−分别表示 ( x , y + ) (x,y ^+) (x,y+)和 ( x , y − ) (x,y ^-) (x,y−)的匹配度。对象之间的顺序关系可以显式或隐式获得。
我们使用 f ( x , y + ) f(x,y ^+) f(x,y+)和 f ( x , y − ) f(x,y^−) f(x,y−)分别表示匹配模型f给出的 ( x , y + ) (x,y ^+) (x,y+)和 ( x , y − ) (x,y ^-) (x,y−)的匹配度。Pairwise Loss Function 定义为表示匹配度和阶数关系之间差异的度量,表示为 l p a i r ( f ( x , y + ), f ( x , y − )) l^pair(f(x,y +),f(x,y−)) lpair(f(x,y+),f(x,y−))。 f ( x , y + ) f(x,y ^+) f(x,y+)比 f ( x , y − ) f(x,y^−) f(x,y−)越大,损失函数值越小。
在学习中,给定训练数据集D,一组有序对象对P的推导如下:

训练数据上的总经验损失是有序对象对上的损失之和:

我们可以看到Pairwise Loss Function是在对象的有序对上定义的。
例如,通常采用pairwise hinge loss。给定一个偏好对
(
x
,
y
+
,
y
−
)
(x,y ^+,y^−)
(x,y+,y−)和匹配模型f,pairwise hinge loss定义为
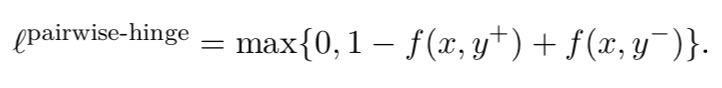
推荐中 pairwise loss 的另一种常见选择是贝叶斯个性化排序(BPR)损失【6】,其目的是最大程度地提高正例预测和负例预测之间的余量:
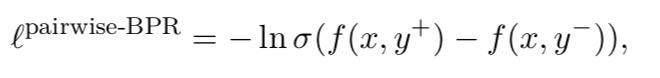 其中
σ
(
⋅
)
σ(·)
σ(⋅)是sigmoid形函数。
其中
σ
(
⋅
)
σ(·)
σ(⋅)是sigmoid形函数。
Listwise Loss Function
在搜索和推荐中,源对象(例如,查询或用户)通常与多个目标对象(例如,多个文档或项目)相关。用于搜索和推荐的评估措施通常将目标对象列表作为一个整体来处理。因此,合理的是在目标对象列表上定义损失函数,称为Listwise Loss Function。假设源对象x与多个目标对象
y
=
y
1
,
y
2
,
以上是关于《搜索和推荐中的深度匹配》——经典匹配模型 2.1 匹配学习的主要内容,如果未能解决你的问题,请参考以下文章