基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘相关的知识,希望对你有一定的参考价值。
转载请注明:转载 from http://blog.csdn.net/u011239443/article/details/53735609
from CCF举办的“大数据精准营销中搜狗用户画像挖掘”竞赛
1. 选题背景与意义
1.1 用户画像与精准营销
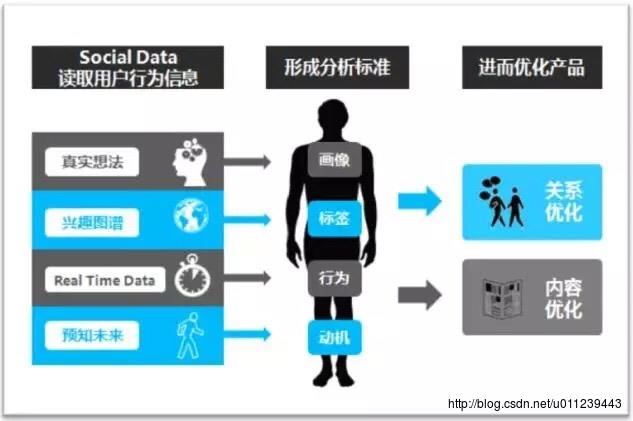
“用户画像”是近几年诞生的名词。很多营销项目或很多广告主,在打算投放广告前,都要求媒体提供其用户画像。在以前,大多媒体会针对自身用户做一个分类,但是有了大数据后,企业及消费者行为带来一系列改变与重塑,通过用户画像可以更加拟人化的描述用户特点。
用户画像,即用户信息标签化,就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌,可以看作是企业应用大数据技术的基本方式。用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息。
消费方式的改变促使用户迫切希望尽快获取自己想要了解的信息,所以说,基于用户画像上的精准营销不管对企业还是对用户来说,都是有需求的,这会给双方交易带来极大便捷,也为双方平等沟通搭建了一个畅通平台。
1.2 搜索引擎下用户画像的挑战

在搜索引擎下,由于搜索引擎本身使用方式的特殊性、用户的流动性、查询的实时性等,带来了与企业传统的对用户信息进行收集与分析有着巨大的不同、更加艰巨的挑战。
例如,我们实时获取到的是用户的查询语句,而由于用户的流动性,并不能直接获取到如年龄、性别、学历等用户的标签信息。这么一来,也就无法根据用户属性对用户进行分群处理,而后再通过推荐系统进行产品上的优化
1.3 本文内容概要
本文内容概要如下:
- 第1章:简介用户画像与搜索引擎下用户画像的精准营销的挑战。
- 第2章:说明实验集群、数据与课题研究目标。
- 第3章:介绍使用分词工具对用户的搜索词列进行分词,以及相关的优化方案。
- 第4章:介绍在分词的基础上,对文本进行特征的抽取与转换,以及相关的优化方案。
- 第5章:介绍在原始特征向量上,进行聚类与降维。
- 第6章:介绍实验中试验过各分类模型
- 第7章:介绍模型参数调优
- 第8章:总结本课题研究中不足与展望后续的优化方案
- 第9章:参考文献
2. 课题实验准备
2.1 Spark集群
| 节点 | 备注 |
|---|---|
| cdh01 | 8核,32G内存,角色:Spark Master,HDFS NameNode,Spark Worker,HDFS DataNode |
| cdh02 | 8核,12G内存,角色:Spark Worker,HDFS DataNode |
| cdh03 | 8核,12G内存,角色:Spark Worker,HDFS DataNode |
| cdh04 | 8核,12G内存,角色:Spark Worker,HDFS DataNode |
2.2 数据集
| 数据文件 | 备注 |
|---|---|
| Train.csv | 带标注的训练集 |
| Test.csv | 测试集 |
2.3 数据介绍
本数据来源于搜狗搜索数据,ID经过加密,训练集中人口属性数据存在部分未知的情况(需要解决方案能够考虑数据缺失对算法性能的影响)。数据所有字段如下表所示:
| 字段 | 说明 |
|---|---|
| ID | 加密后的ID |
| age | 0:未知年龄; 1:0-18岁; 2:19-23岁; 3:24-30岁; 4:31-40岁; 5:41-50岁; 6: 51-999岁 |
| Gender | 0:未知1:男性2:女性 |
| Education | 0:未知学历; 1:博士; 2:硕士; 3:大学生; 4:高中; 5:初中; 6:小学 |
| Query List | 搜索词列表 |
2.4 数据示例
对于train.csv中的数据记录:
00627779E16E7C09B975B2CE13C088CB 4 2 0 钢琴曲欣赏100首 一个月的宝宝眼睫毛那么是黄色 宝宝右眼有眼屎 小儿抽搐怎么办 剖腹产后刀口上有线头 属羊和属鸡的配吗
2.5 课题任务描述
根据提供的用户历史一个月的查询词与用户的人口属性标签(包括性别、年龄、学历)做为训练数据,通过机器学习、数据挖掘技术构建分类算法来对新增用户的人口属性进行判定。
3. 查询词分词
3.1 NLPIR
NLPIR汉语分词系统(又名ICTCLAS2013),主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取;张华平博士先后倾力打造十余年,内核升级10次。
全球用户突破20万,先后获得了2010年钱伟长中文信息处理科学技术奖一等奖,2003年国际SIGHAN分词大赛综合第一名,2002年国内973评测综合第一名。
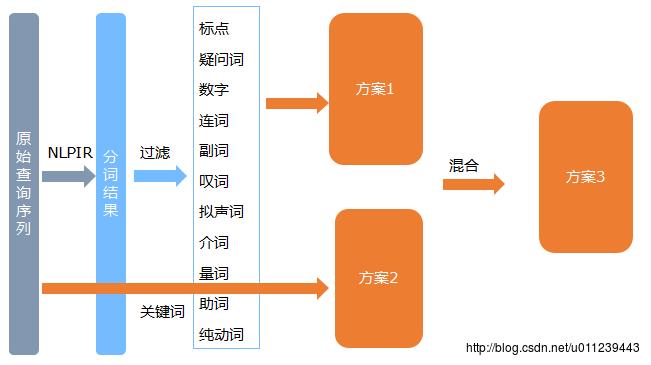
我们传入每个用户的搜索词列,表经过NLPIR分词工具得到的分词。之后,我们做个进一步的优化策略:
3.1.1 去停用词
我们根据分词后词语所带的词性,对一些特征代表性不够强的词语进行过滤:
for (int i = 0; i < sbtmp.length(); ++i)
char cc = sbtmp.charAt(i);
if (cc == ' ')
sbtmp.deleteCharAt(i);
--i;
else if (cc == '/')
// 去词条件
Boolean isdel =
// 1. 去标点
(i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'w')
// 2. 疑问词
|| (i + 2 < sbtmp.length() && sbtmp.charAt(i + 1) == 'r'
&& sbtmp.charAt(i + 2) == 'y')
// 3. 数字
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'm')
// 4. 连词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'c')
// 5. 副词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'd')
// 6. 叹词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'e')
// 7. 拟声词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'o')
// 8. 介词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'p')
// 9. 量词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'q')
// 10. 助词
|| (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) == 'u')
// 11. 纯动词
|| (i + 2 < sbtmp.length() && sbtmp.charAt(i + 1) == 'v'
&& sbtmp.charAt(i + 2) == ' ');
// 去词
if (sbtmp.charAt(i + 1) != 'n' && sbtmp.charAt(i + 1) != 'i' && sbtmp.charAt(i + 1) != 'j'
&& sbtmp.charAt(i + 1) != 'h'
&& !(i + 2 < sbtmp.length() && sbtmp.charAt(i + 2) == 'n'))
while (i + 1 < sbtmp.length() && sbtmp.charAt(i + 1) != ' ')
sbtmp.deleteCharAt(i + 1);
while (i >= 0 && sbtmp.charAt(i) != ',')
sbtmp.deleteCharAt(i);
--i;
// 若无需去词,把‘/’转为‘,’,并去除随后的词性标志
else
sbtmp.setCharAt(i, ',');
while (sbtmp.charAt(i + 1) != ' ')
sbtmp.deleteCharAt(i + 1);
for (int i = 1; i < sbtmp.length() - 1; ++i)
if (sbtmp.charAt(i) == ',' && (sbtmp.charAt(i - 1) == ',' || sbtmp.charAt(i + 1) == ','))
sbtmp.deleteCharAt(i);
--i;
// 去中间单个字
else if (sbtmp.charAt(i - 1) == ',' && sbtmp.charAt(i + 1) == ',')
sbtmp.deleteCharAt(i);
sbtmp.deleteCharAt(i);
--i;
// 去首个单个字
else if (sbtmp.charAt(i) == ',' && i == 1)
sbtmp.deleteCharAt(i - 1);
sbtmp.deleteCharAt(i - 1);
--i;
3.1.2 提取关键词
分词并不能很好的将常用的短语提取出来,如词语“用户画像”,使用分词工具更倾向于将其分成“用户”和“画像”,而失去了词语本身的含义。NLPIR还提供了提取一段话的关键词的功能,我们可以使用它:
int numofIm = 1000;
String nativeByte = CLibrary.Instance.NLPIR_GetKeyWords(sInput, numofIm, false);
经过分词后,平均每位用户搜索词列所得到的词量在600个左右,这里我们设置提取1000个关键词,但实际上一个用户的关键词提取的数量在60~200左右。由于关键词的很强的特征性,并且提取出的数量又少,若后续我们直接使用如词语的词频作为用户的特征属性进行分类的话,很可能各个用户特征属性有巨大的差异,即用户之间拥有的相同关键词过少。
3.1.3 混合提取
在用户搜索词列分词基础上,在增加N次对其进行M个关键词提取的结果。
3.2 “结巴”分词
jieba,即“结巴”中文分词,一个优秀的开源的分词工具,一直致力于做最好的 Python 中文分词组件。我们直接使用它对用户搜索词列进行1000个关键词的提取,所能提取到的关键词比NLPIR数量有所提高。显然,关键词提取的数量增加,每个关键词的代表性就有所减弱。但在后续的分类实验中证明了,使用该分词方案,对比上节的各个分词方案,在模型相同的情况下,会有2%~5%的准确率的提升。
关键词抽取可基于以下两种算法,后续实验实践证明基于 TF-IDF 算法的关键词的抽取,在该数据集和我们后续所选择的模型中会得到更好的效果。
3.2.1 基于 TF-IDF 算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
代码示例 (关键词提取)
import sys
sys.path.append('../')
import jieba
import jieba.analyse
from optparse import OptionParser
USAGE = "usage: python extract_tags.py [file name] -k [top k]"
parser = OptionParser(USAGE)
parser.add_option("-k", dest="topK")
opt, args = parser.parse_args()
if len(args) < 1:
print(USAGE)
sys.exit(1)
file_name = args[0]
if opt.topK is None:
topK = 10
else:
topK = int(opt.topK)
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content, topK=topK)
print(",".join(tags))
3.2.2 基于 TextRank 算法的关键词抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
- jieba.analyse.TextRank() 新建自定义 TextRank 实例
- 基本思想[1]:
- 将待抽取关键词的文本进行分词
- 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
- 计算图中节点的PageRank,注意是无向带权图
4. 特征抽取与转换
4.1 TF-IDF
- TF(Term Frequency) 词频
- DF (Document Frequency) 词语出现的文档数目
- N 总共的文档数目
- IDF (Invert Document Frequency) 逆文档频率: I D F k = l o g 2 N D F k \\large IDF_k = log_2\\fracNDF_k IDFk=log2DFkN
- IDF (Invert Document Frequency) 逆文档频率: I D F k = l o g 2 ( N D F k + 0.05 ) \\large IDF_k = log_2(\\fracNDF_k + 0.05) IDFk=log2(DFkN+0.05)
- V a l u e k = T F k ∗ I D F k \\large Value_k = TF_k * IDF_k Valuek=TFk∗IDFk
IDF反映了一个特征词在整个文档集合中的情况,出现的愈多IDF值越低,这个词区分不同文档的能力越差。
示例代码:
import org.apache.spark.ml.feature.HashingTF, IDF, Tokenizer
val sentenceData = spark.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(0, "I wish Java could use case classes"),
(1, "Logistic regression models are neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
val featurizedData = hashingTF.transform(wordsData)
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("features", "label").take(3).foreach(println)
/*输出结果为:
[(20,[0,5,9,17],[0.6931471805599453,0.6931471805599453,0.28768207245178085,1.3862943611198906]),0]
[(20,[2,7,9,13,15],[0.6931471805599453,0.6931471805599453,0.8630462173553426,0.28768207245178085,0.28768207245178085]),0]
[(20,[4,6,13,15,18],[0.6931471805599453,0.6931471805599453,0.28768207245178085,0.28768207245178085,0.6931471805599453]),1]
*/
值得一提的是,Spark所提供的TF并不是数组,而是一个使用 MurmurHash 3 函数的哈希表。其默认向量维度为 2^18=262,144。我们运行上节示例代码可以发现,我们将哈希表大小设置成了20,第二条sentence:"I wish Java could use case classes"有7个不同的单词,经过hash函数却被映射成了只有5个属性为非零值,即有2个位置放了2个不同的单词。这具有很大的随机性,将两个无关词义的词语,甚至词义相反的词语,如“男”与“女”,映射到哈希表的同一位置,作为相同的用户属性来处理。
4.2 CountVectorizer
为了解决上节所提到的HashingTF哈希函数映射后导致词语重叠问题,我们使用了Spark的CountVectorizer。我们会先想CountVectorizer传入一个互斥的字符串数组,文本经过CountVectorizer转换后,会对该数组中所有的词语进行与属性的一一对应。
我们对互斥的字符串数组进行的优化,过滤掉了词频为1的词语,将CountVectorizer的维度减少到原来的50%,极大的降低了后续训练模型时所需的内存,而且除去的数据噪音,增加了预测的准确度:
val diffTrain = Triandata.map line =>
val temp = line.split("\\t")
if (temp.length == 5) temp(4) else ""
val diffTest = Testdata.map line =>
val temp = line.split("\\t")
if (temp.length == 5) temp(1) else ""
val diffAll = diffTrain.union(diffTest).flatMap(_.split(",")).map((_, 1)).reduceByKey(_ + _).collect.filter(line => line._1 != "" && line._2 > 14).map(line => line._1)
val cvm = new CountVectorizerModel(diffAll).setInputCol(tokenizer.getOutputCol).setOutputCol("features")
4.3 StopWordsRemover
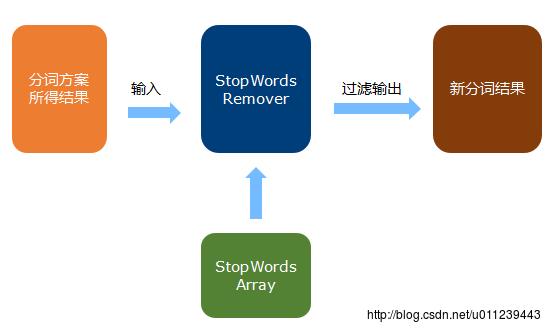
在上一章中ÿ
以上是关于基于Spark的大数据精准营销中搜狗搜索引擎的用户画像挖掘的主要内容,如果未能解决你的问题,请参考以下文章