5种GaussDB ETCD服务异常实例分析处理
Posted 华为云开发者联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5种GaussDB ETCD服务异常实例分析处理相关的知识,希望对你有一定的参考价值。
摘要:一文带你细数几种ETCD服务异常实例状态。
本文分享自华为云社区《【实例状态】GaussDB ETCD服务异常》,作者:酷哥 。
首先确认是否是虚拟机、网络故障
虚拟机故障导致ETCD服务异常告警
问题现象
管控面上报etcd服务异常告警,虚拟机发生重启,热迁移、冷迁移,HA等动作。
问题分析及界定
在告警信息中找到实例ID、节点ID、虚拟机ID,在管控面查看虚拟机状态是否正常,能否正常登录,
如果虚拟机异常无法登录,联系IaaS技术支持修复虚拟机。
检查虚拟机是否发生过重启,热迁移、冷迁移、HA等动作,例如内存、网卡等问题引起热迁移。
处理步骤
联系IaaS技术支持修复虚拟机,确认虚拟机故障原因,例如内存、网卡等问题引起热迁移。
网络故障导致ETCD服务异常告警
问题现象
管控面上报etcd服务异常告警,虚拟机无法登录或ping通其他节点IP, 或者监控显示网络有异常。
问题分析及界定
在该节点上ping其他节点IP,测试是否ping通。
如果ping不通,执行步骤(1)(2),检查该节点网络、IP配置、防火墙配置等。
如果ping通,执行步骤(3)确认告警时间点网络是否断开。
(1)检查IP是否正常:
ifconfig查看etcd使用的IP是否存在,如果不存在,排查IP配置丢失原因,常见原因是虚拟机重启后IP没有重新配置,导致丢失。
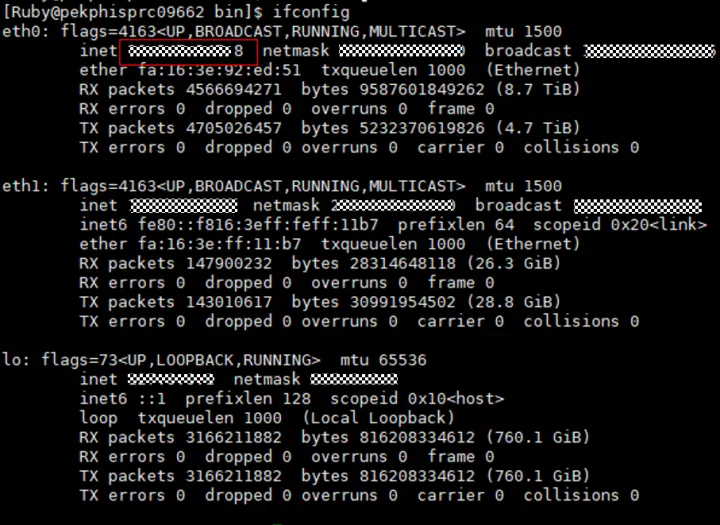
(2)检查防火墙是否正常
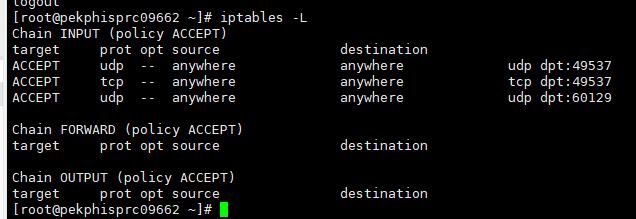
在Ruby用户下查看etcd的IP和端口: ps ux | grep etcd

在root用户下iptables -L命令检查防火墙是否限制了IP和端口,如果有限制,去掉防火墙限制。
(3) 查看etcd日志
进入Ruby用户
cd $GAUSSLOG/cm/etcd
查看对应时间点的etcd_xxx.log日志,如果有如下日志,可能是etcd节点间网络断开, 或者对端的etcd进程down,导致本端etcd连接断开。
排查网络原因或对端的etcd进程是否重启,网络原因可能是网络断开,网卡故障,也有可能是虚拟机故障。
grpc: Server.processUnaryRPC failed to write status: connection error: desc = "transport is closing"
rafthttp: lost the TCP streaming connection with peer c797ab3a61e2ea55 (stream MsgApp v2 reader)
etcdserver: failed to reach the peerURL(https:// X.X.X.X:X) of member c797ab3a61e2ea55 (Get "https://X.X.X.X:X/version": dial tcp X.X.X.X:X: i/o timeout)
rafthttp: health check for peer c797ab3a61e2ea55 could not connect: dial tcp X.X.X.X:X: i/o timeout (prober "ROUND_TRIPPER_RAFT_MESSAGE")
处理步骤
处理步骤同上,已说明。
负载过重导致ETCD服务异常警告
问题现象
管控面上报etcd服务异常告警, 磁盘IO/CPU/内存 很高.
问题分析及界定
进入Ruby用户
cd $GAUSSLOG/cm/etcd
查看对应时间点的etcd_xxx.log日志,告警时间点有如下日志,说明etcd节点负载过重, 磁盘IO、CPU等压力大。
2021-04-09 10:57:40.112936 W | wal: sync duration of 2.00201804s, expected less than 1s ===通常这个表示磁盘IO压力大。
2021-04-09 10:57:40.112993 W | etcdserver: failed to send out heartbeat on time (exceeded the 1s timeout for 2.124414ms, to c8eccd97bed22939)
2021-04-09 10:57:40.112999 W | etcdserver: server is likely overloaded
2021-04-09 10:57:43.126444 W | etcdserver: read-only range request "key:\\"/Ruby/ignoreNodeNumKey\\" " with result "error:context canceled" took too long (1.999877971s) to execute
cd $GAUSSLOG/cm/cm_agent
搜索对应时间点的cm_agent-xxx.log, 如果有如下日志,表示当时磁盘io比较高, io util 100 表示磁盘io 达到100%
2021-04-09 11:06:24.047 tid=15822 LOG: device vdb1, tot_ticks 889640579, cputime 1798651342, io util 100
处理步骤
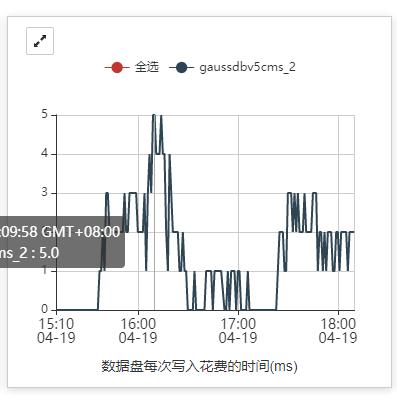
1、在管控面查看该节点当时磁盘IO、CPU、内存监控指标是否很高,
示例1:数据盘写延时在16:00左右升高,影响etcd状态。
示例2: etcd故障时刻,cpu、内存、磁盘写延时都有增长,尤其是磁盘写延时很明显,需要分析磁盘写延时升高的原因。
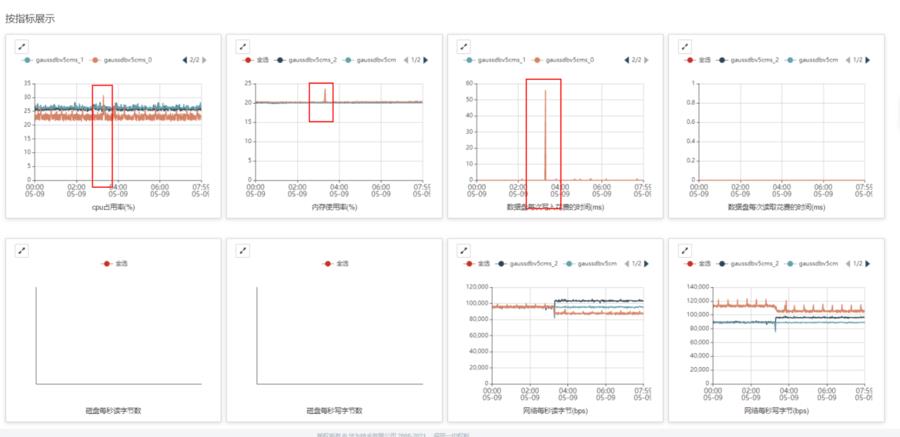
2、如果故障现场还在: iostat -mx 1 查看磁盘IO状态,top和free命令查看cpu、内存使用情况, 分析磁盘IO高、CPU高,内存高的原因。
3、root用户查看该节点的系统日志, cd /var/log, 查看该时间点message日志是否有异常记录。例如:节点内存耗尽了,分析占用内存的原因,是否内存泄漏等。
如果仍无法确认原因,联系华为工程师。
etcd进程故障导致ETCD服务异常告警
问题现象
etcd进程down、重启,管控面上报etcd服务异常告警
问题分析及界定
登陆故障etcd节点, 进入Ruby用户,执行命令ps ux | grep etcd, 查看etcd进程是否在运行。
如果进程在,查看etcd进程启动时间,告警时是否重启过,联系华为工程师确认重启原因。

如果进程不在,查看etcd无法启动原因:
(1)cd $GAUSSLOG/bin, 查看目录下是否有cluster_manual_start 和 etcd_manual_start 两个文件,
如果有表示集群被停止,确认停止集群的原因,之后启动集群,定位结束。
(2)cd $GAUSSHOME/bin 查看目录下是否存在etcd这个文件,文件权限是否正确,确认文件不存在或权限不正确的原因。
(3)检查etcd的数据目录所在磁盘是否满了或者故障,etcd目录如下:cm_ctl query -Cvipd查看
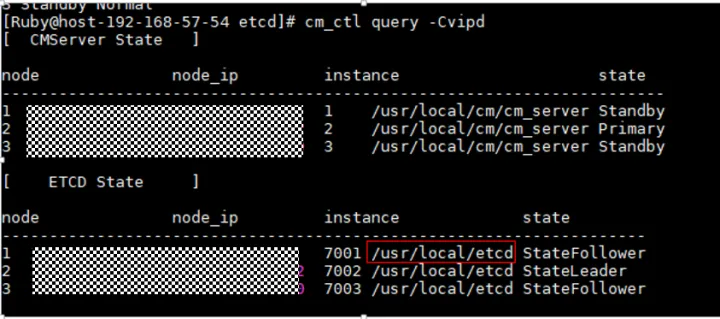
检查etcd的数据目录所在磁盘是否满了或者目录权限不正确(正确是700)或者故障,
如果磁盘满,检查占用磁盘的文件并清除或者转存到其他盘,如果是etcd本身的文件占满,联系华为工程师分析原因。
如果目录权限不正确,修改为正确的目录权限。如果是磁盘故障,联系IaaS技术支持分析定位。
处理步骤
参照上述处理,如果不是以上原因,请联系华为工程师
OM接口无法正确返回结果导致ETCD服务异常告警
问题现象
管控面上报etcd服务异常告警, 管控无法获取集群状态
问题分析及界定
查看管控面是否获取集群状态成功,是否获取空消息,联系华为工程师分析定位。
cd $GAUSSLOG/om/
查看gs_om-xxx.log,是否有如下异常日志
例如: The status file does not exist. Path: /usr/local/temp/local_status_1611355718.58.dat.
处理步骤
参照上面描述步骤。
以上是关于5种GaussDB ETCD服务异常实例分析处理的主要内容,如果未能解决你的问题,请参考以下文章
华为云原生之数据仓库服务GaussDB(DWS)的深度使用与应用实践