论文解读:Hierarchical Question-Image Co-Attention for Visual Question Answering
Posted yealxxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读:Hierarchical Question-Image Co-Attention for Visual Question Answering相关的知识,希望对你有一定的参考价值。
这是关于VQA问题的第七篇系列文章。本篇文章将介绍论文:主要思想;模型方法;主要贡献。有兴趣可以查看原文:Hierarchical Question-Image Co-Attention for Visual Question Answering
1,主要思想:
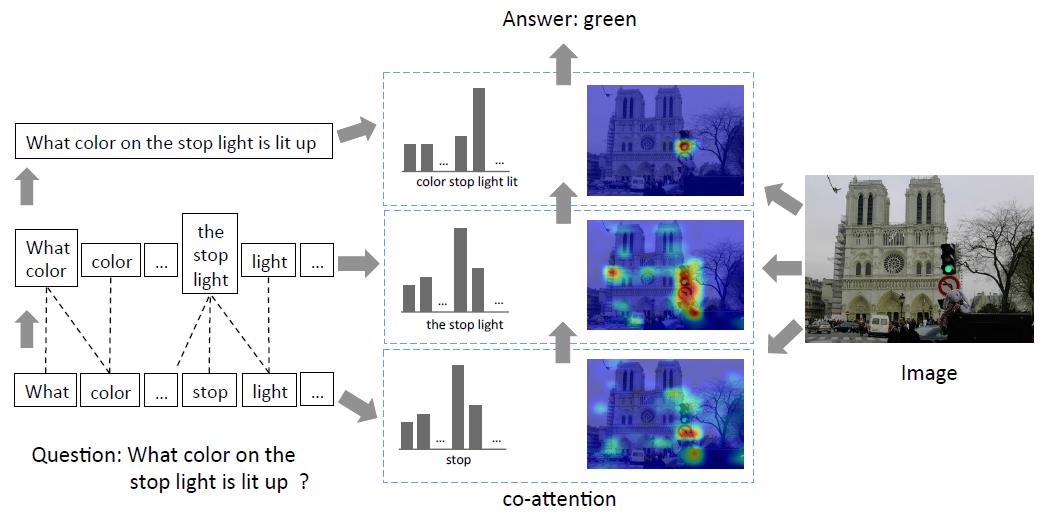
当前基于视觉注意的些VQA方法主要关注:”where to look”或者 visual attention。本文认为基于问题的attention “which word to listen to ” 或者question attenion也相当重要。基于这个动机,文中提出一种多模态注意模型:Co-attention + Question Hierarchy。即是图像和问题文本相互关注。
2,模型介绍
模型有两部分组成:
- Co-Attention:这个部分包括基于图像的attention和基于问题的attention。
- Question Hierarchy:论文提出一种图像和问题协同注意的分层架构,主要分为三层。word level。将每个单词表示成向量 ;phrase level 利用一个1D CNN提取特征 ;question level 利用RNN编码整个问题。
a.Question Hierarchy
- word-level feature:问题映射到一个向量空间,换成词向量
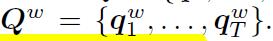
- phrase-level feature:利用1-D CNN作用于Qw,在每个单词位置计算单词向量和卷积核的内积,卷积核有三个size,unigram, bigram and trigram。


- question-level feature:将得到的max-pooling结果送入到LSTM中提取特征。全部过程如下图。

b.Co-Attention
图像和问题的关注机制,论文提出了两种方法:
-
Parallel Co-Attention:通过计算image和question特征之间的相似性,使image和question联系起来。
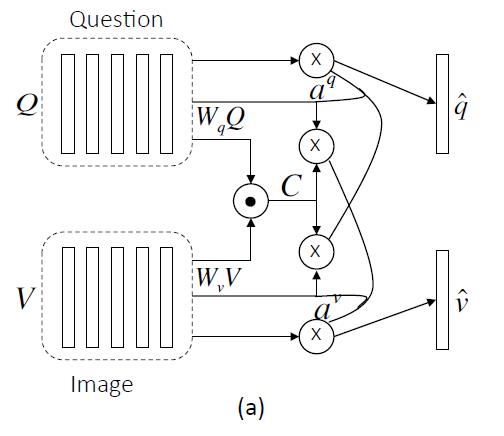
给定image feature map V和question 表示Q,计算相关矩阵C:
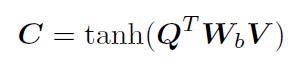
将C当作是一种特征,可以预测image和question attention maps:
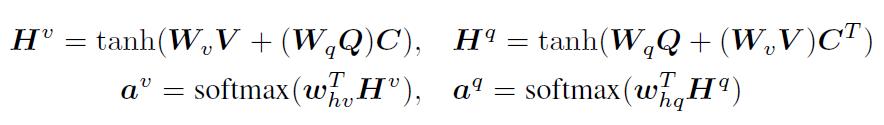
基于以上的attention weight,image和question attention map可以计算image features和question features:

-
Alternating Co-Attention:主要由三步组成:1.将问题总结成一个单向量q;2.基于q,集中注意于image;3.基于attended image feature,集中注意question。
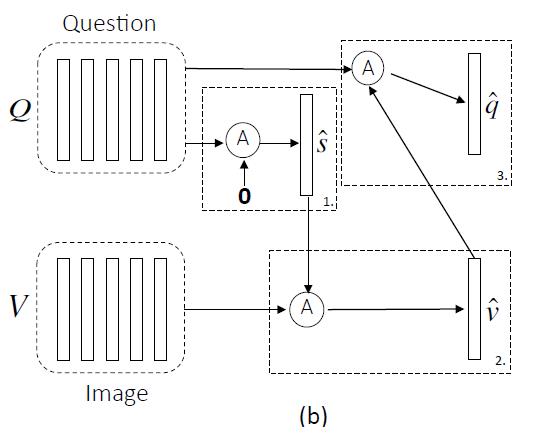
论文先定义了一个关注操作的函数:
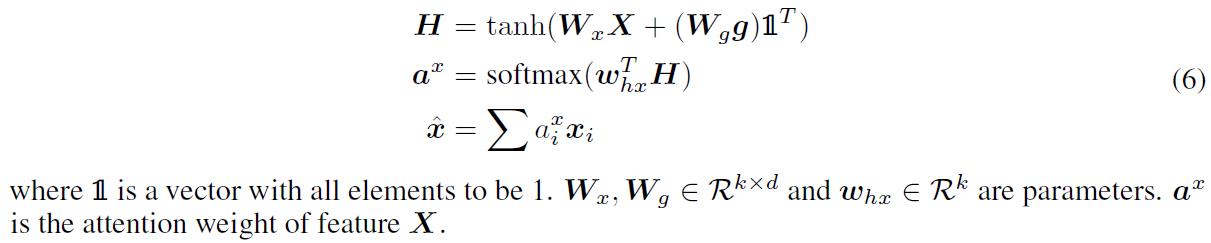
第一步:X = Q, and g is 0;
第二步:X = V where V is the image features,guidance g is intermediate attended question feature ^s from the first step
第三步:we use the attended image feature ^v as the guidance to attend the question again, i.e., X = Q and g = ^v. -
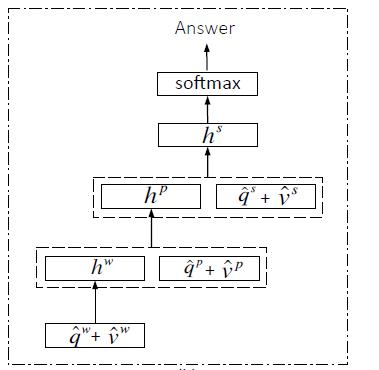
Encoding for Predicting Answers:利用MLP编码attention features。w,p,s是word level, phrase level and question level三个维度的提取的特征。
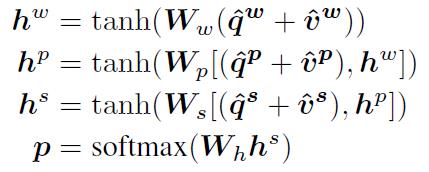
3,主要贡献:
- 提出co-attention mechanism 机制处理VQA任务,并且采用两种策略应用这中机制,parallel and alternating co-attention。
- 采用分层结构表示问题,因此构建的image-question co-attention maps分为三个层次:word level, phrase level and question level.
- 在phrase level,采用convolution-pooling strategy 自适应选择phrase size。
以上是关于论文解读:Hierarchical Question-Image Co-Attention for Visual Question Answering的主要内容,如果未能解决你的问题,请参考以下文章