随机森林
Posted 已删除ddd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了随机森林相关的知识,希望对你有一定的参考价值。
1. 算法简介
随机森林由LeoBreiman(2001)提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
2. 算法原理
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
随机森林模型的基本思想是:首先,利用bootstrap抽样从原始训练集抽取k个样本,且每个样本的样本容量都与原始训练集一样;其次,对k个样本分别建立k个决策树模型,得到k种分类结果;最后,根据k种分类结果对每个记录进行投票表决决定其最终分类,如下图所示。
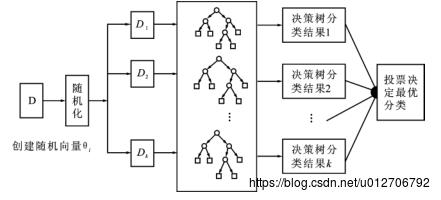
在建立每一棵决策树的过程中,有两点需要注意采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤——剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
分裂特征点的选择:
1) 信息增益
2) 信息增益比
3) 基尼指数
3. 算法流程
随机森林的具体实现过程如下:
(1) 给定训练集S,测试集T,特征维数F。确定参数:决策树的数量t,每棵树的深度d,每个节点使用到的特征数量f,终止条件:节点上最少样本数s,节点上最少的信息增益m
对于第i棵树,i=1: t:
(2) 从S中有放回的抽取大小和S一样的训练集S(i),作为根节点的样本,从根节点开始训练
(3) 如果当前节点上达到终止条件,则设置当前节点为叶子节点,如果是分类问题,该叶子节点的预测输出为当前节点样本集合中数量最多的那一类c(j),概率p为c(j)占当前样本集的比例;如果是回归问题,预测输出为当前节点样本集各个样本值的平均值。然后继续训练其他节点。如果当前节点没有达到终止条件,则从F维特征中随机选取f维特征(f << F)。利用这f维特征,寻找分类效果最好的一维特征k及其阈值th,当前节点上样本第k维特征小于th的样本被划分到左节点,其余的被划分到右节点。继续训练其他节点。
(4) 重复(2)(3)直到所有节点都训练过了或者被标记为叶子节点。
(5) 重复(2),(3),(4)直到所有决策树都被训练过。
利用随机森林的预测过程如下:
对于第i棵树,i=1: t
(1)从当前树的根节点开始,根据当前节点的阈值th,判断是进入左节点(<th)还是进入右节点(>=th),直到到达,某个叶子节点,并输出预测值。
(2)重复执行(1)直到所有t棵树都输出了预测值。如果是分类问题,则输出为所有树中预测概率总和最大的那一个类,即对每个c(j)的p进行累计;如果是回归问题,则输出为所有树的输出的平均值。
以上是关于随机森林的主要内容,如果未能解决你的问题,请参考以下文章