mysql数据库要放1亿条信息怎样分表?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql数据库要放1亿条信息怎样分表?相关的知识,希望对你有一定的参考价值。
数据库要求用mysql的 (虽然我感觉PGSQL更强悍一些,但是...)
分表可以由我来控制,,但要求这一个库3年能存放存放1亿条的信息
现在想问问,,建几个表比较合适呢??
如果只建1个表,可以承受吗?
推荐建立几个表呢?
mysql数据库对1亿条数据的分表方法设计:
目前针对海量数据的优化有两种方法:
(1)垂直分割
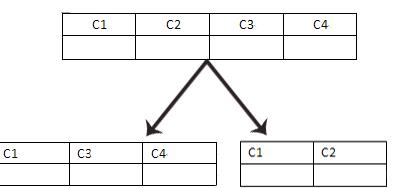
优势:降低高并发情况下,对于表的锁定。
不足:对于单表来说,随着数据库的记录增多,读写压力将进一步增大。
(2)水平分割
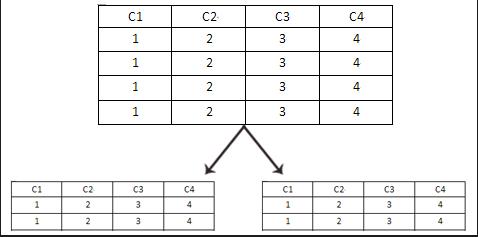
如果单表的IO压力大,可以考虑用水平分割,其原理就是通过hash算法,将一张表分为N多页,并通过一个新的表(总表),记录着每个页的的位置。
假如一个门户网站,它的数据库表已经达到了1亿条记录,那么此时如果通过select去查询,必定会效率低下(不做索引的前提下)。为了降低单表的读写IO压力,通过水平分割,将这个表分成10个页,同时生成一个总表,记录各个页的信息,那么假如我查询一条id=100的记录,它不再需要全表扫描,而是通过总表找到该记录在哪个对应的页上,然后再去相应的页做检索,这样就降低了IO压力。
参考技术A MySQL表最大能达到多少?MySQL 3.22限制的表大小为4GB。由于在MySQL 3.23中使用了MyISAM存储引擎,最大表尺寸增加到了65536TB(2567 – 1字节)。由于允许的表尺寸更大,MySQL数据库的最大有效表尺寸通常是由操作系统对文件大小的限制决定的,而不是由MySQL内部限制决定的。
InnoDB存储引擎将InnoDB表保存在一个表空间内,该表空间可由数个文件创建。这样,表的大小就能超过单独文件的最大容量。表空间可包括原始磁盘分区,从而使得很大的表成为可能。表空间的最大容量为64TB。
在下面的表格中,列出了一些关于操作系统文件大小限制的示例。这仅是初步指南,并不是最终的。要想了解最新信息,请参阅关于操作系统的文档。
操作系统
文件大小限制
Linux 2.2-Intel 32-bit
2GB (LFS: 4GB)
Linux 2.4+
(使用 ext3 文件系统) 4TB
Solaris 9/10
16TB
NetWare w/NSS 文件系统
8TB
win32 w/ FAT/FAT32
2GB/4GB
win32 w/ NTFS
2TB(可能更大)
MacOS X w/ HFS+
2TB
在Linux 2.2平台下,通过使用对ext2文件系统的大文件支持(LFS)补丁,可以获得超过2GB的MyISAM表。在Linux 2.4平台下,存在针对ReiserFS的补丁,可支持大文件(高达2TB)。目前发布的大多数Linux版本均基于2.4内核,包含所有所需的LFS补丁。使用JFS和XFS,petabyte(千兆兆)和更大的文件也能在Linux上实现。然而,最大可用的文件容量仍取决于多项因素,其中之一就是用于存储MySQL表的文件系统。
关于Linux中LFS的详细介绍,请参见Andreas Jaeger的“Linux中的大文件支持”页面:http://www.suse.de/~aj/linux_lfs.html。
Windows用户请注意: FAT和VFAT (FAT32)不适合MySQL的生产使用。应使用NTFS。
在默认情况下,MySQL创建的MyISAM表允许的最大尺寸为4GB。你可以使用SHOW TABLE STATUS语句或myisamchk -dv tbl_name检查表的最大尺寸。
1
mysql > show table status like 't_user';
如果需要使用大于4GB的MyISAM表(而且你的操作系统支持大文件),可使用允许AVG_ROW_LENGTH和MAX_ROWS选项的CREATE TABLE语句。
创建了表后,也可以使用ALTER TABLE更改这些选项,以增加表的最大允许容量。
以下语句将表的最大容量设成了1000G(1TB)
1
mysql > alter table t_user max_rows = 200000000000 avg_row_length = 50;
处理MyISAM表文件大小的其他方式:
如果你的大表是只读的,可使用myisampack压缩它。myisampack通常能将表压缩至少50%,因而,从结果上看,可获得更大的表。此外,myisampack还能将多个表合并为1个表。
MySQL包含一个允许处理MyISAM表集合的MERGE库,这类MyISAM表具有与单个MERGE表相同的结构。
下面是一个例子:
这是一个存储天气的表:
mysql> describe weather; +-----------+--------------+------+-----+------------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+--------------+------+-----+------------+-------+ | city | varchar(100) | | MUL | | | | high_temp | tinyint(4) | | | 0 | | | low_temp | tinyint(4) | | | 0 | | | the_date | date | | | 0000-00-00 | | +-----------+--------------+------+-----+------------+-------+ 4 rows in set (0.01 sec)
看看它的容量大小限制,我们使用 SHOW TABLE STATUS
mysql> show table status like 'weather' \G *************************** 1. row *************************** Name: weather Type: MyISAM Row_format: Dynamic Rows: 0 Avg_row_length: 0 Data_length: 0 Max_data_length: 4294967295 Index_length: 1024 Data_free: 0 Auto_increment: NULL Create_time: 2003-03-03 00:43:43 Update_time: 2003-03-03 00:43:43 Check_time: 2003-06-14 15:11:21 Create_options: Comment: 1 row in set (0.00 sec)
注意 Max_data_length 为4GB. 我们把它改大:
mysql> alter table weather max_rows = 200000000000 avg_row_length = 50; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show table status like 'weather' \G *************************** 1. row *************************** Name: weather Type: MyISAM Row_format: Dynamic Rows: 0 Avg_row_length: 0 Data_length: 0 Max_data_length: 1099511627775 Index_length: 1024 Data_free: 0 Auto_increment: NULL Create_time: 2003-06-17 13:12:49 Update_time: 2003-06-17 13:12:49 Check_time: NULL Create_options: max_rows=4294967295 avg_row_length=50 Comment: 1 row in set (0.00 sec)
现在的表可以存储更多的内容了.
是否行数太多?
修改容量后,你会发现(上面例子)Create_options 中多了最大行数的限制4294967295,是的,它仍然有一定的限制,但现在的限制是行数,并不是表的容量大小了。也就是说你的最大行数不能超过4294967295.
为什么?
因为系统是32位,如果你移到64位的系统里,这个行数限制就会增加.
标签设计方案
设计目标: 400W用户 200个标签
总涉及标签数据 8亿条数据
1. mysql表结构设计
| ID | uid | 身份标签ID | 状态 |
|---|---|---|---|
| 1 | 1 | 1 | 1 |
| 2 | 1 | 2 | 1 |
| 3 | 2 | 2 | 1 |
| 4 | 3 | 3 | 0 |
采用一对多的存储方式 即一个用户对应多条身份标签
2. mysql分表设计 2000W数据分一个表(不涉及大数据量存储 所以2000W数据为一个表)
分表数量 为40个表
根据用户ID取模分片 保证数据均匀落表(同时保证同一用户的身份信息在同一个表上)(缺点:扩容需要做大数据量数据迁移)
3. nosql存储方式
redis bitmaps存储方式
存储key值设计下面为准
耗费内存预估
-
按照400W用户 200个标签来设计的话
单个标签预计消耗内存0.5M
对于存储所有的标签的key值 大约100M的空间足以支持 -
如果需要单独存储用户下面所有的标签 耗费的内存 :
单个用户耗费的内存 0.0000248M
400W用户耗费内存 99.2M左右
// 所有身份标签ID为1的用户身份标识
"userlab:1":
"01001001"
,
// 所有身份标签ID为2的用户身份标识
"userlab:2":
"01001001"
,
// 用户ID为1的用户所有的标签状态位
"useralllab:user:1":
"0101101011010010001"
4.洗标签方式
采用redis队列+go协程来进行洗标签。结合go高并发来实现标签的快速清洗入库以及存储bitmaps
以上是关于mysql数据库要放1亿条信息怎样分表?的主要内容,如果未能解决你的问题,请参考以下文章