Hash一致性算法
Posted 青冬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hash一致性算法相关的知识,希望对你有一定的参考价值。
Hash一致性算法
序
在进行一般的负载均衡、查询负载、分布式缓存、Shuffle等等中的时候,都需要计算这条数据/请求/查询去往哪一个节点。一般来说我们直接进行MessageKey取Hash后的结果对后续节点数进行取余操作就能标识这条数据去往哪里:
W
h
e
r
e
G
o
=
H
a
s
h
(
M
e
s
s
a
g
e
K
e
y
)
%
N
o
d
e
N
u
m
WhereGo=Hash(MessageKey) \\% NodeNum
WhereGo=Hash(MessageKey)%NodeNum
这样的计算在一定业务场景下是没有问题的,但是对于强业务场景的情况下可能就会有问题。
普通Hash取余的缺陷
当我们使用Redis进行数据的缓冲时,时常将数据从数据库中取出,然后插入到Redis中进行缓存。而Redis进行扩容的时候,如果采用的是上面的算法进行计算的时候,MessageKey取Hash不变,但由于NodeNum的变化导致得出WhereGo的编号也会发生变化,如下图:
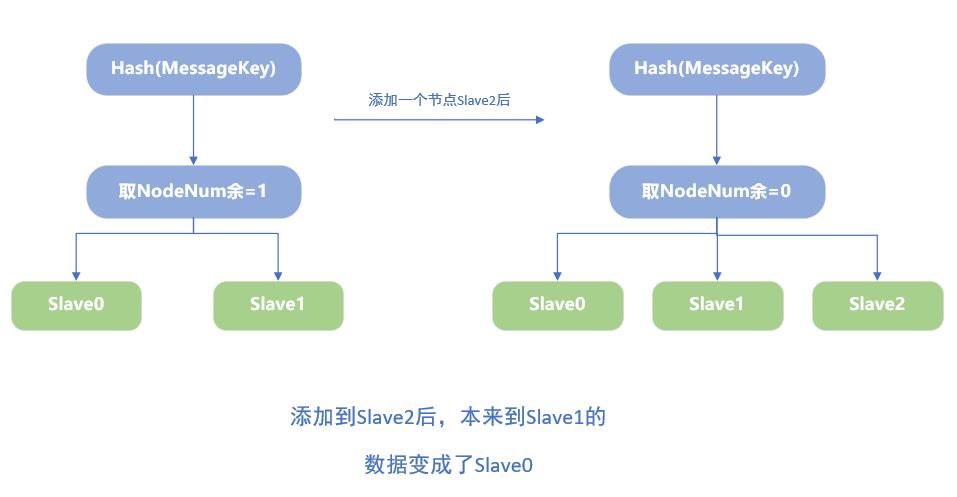
我们想象的添加Slave2后,让其分担Slave0和Slave1的负担,但其是将整个顺序打乱了,进行了一次混洗。该情况对于Redis来说是不可容忍的,因为缓存数据就在这里,不能进行移动。如果每次添加节点,或者删除节点,就引起缓存失效,那么扩容的代价也太大了。
一致性Hash
顾名思义,我们想在无论什么情况之下,都能保证我原有的集群不会因为某个节点的连接,或者某个节点的退出导致我整体数据链路的转变。无论进行什么样的变化,最好都是变化的节点与没有变化的节点之间发生一些网络交换(必要的替换),而没有变换的节点之间不会有什么变化(非必要交换)。
简单来说就是团队新来一个人,他最多也就接手所有人的一部分工作,或者接手部分人的部分工作;而不是说所有人的计划安排重新来过。
Hash环
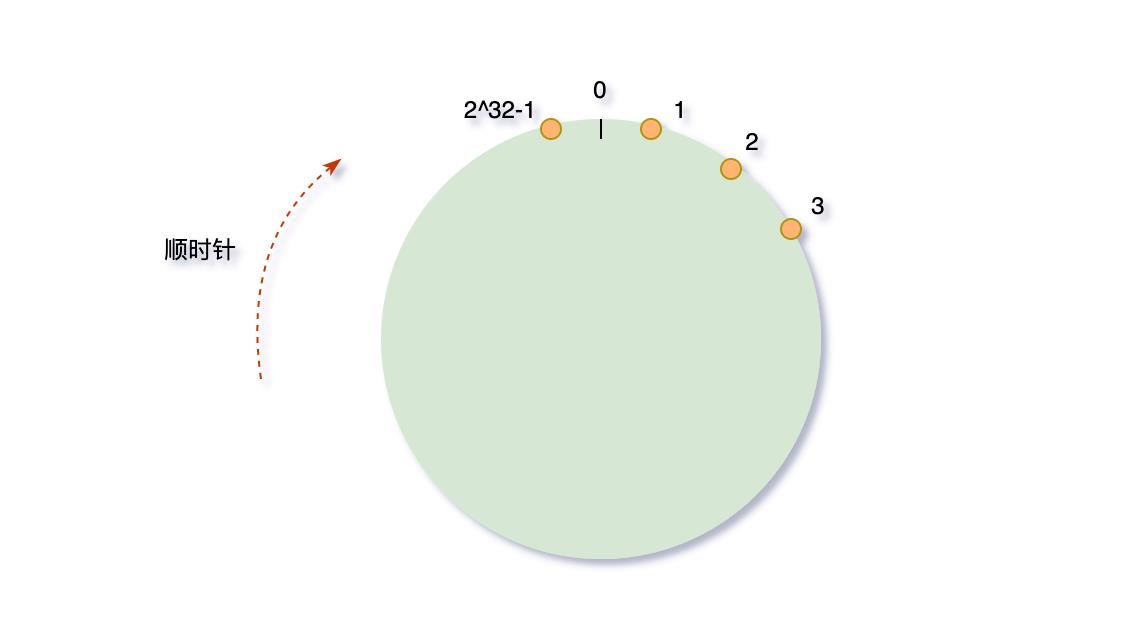
在进行上面的映射时,我们将Hash得到的值进行取余,而取余的是NodeNum,只要这个值发生变化,那么就会造成整体变化。那么我们直接固定这个值为一个大值如 2^32。那么每次一个MessageKey进行计算后都不会变化,那么怎么指定后续路径呢?使用Hash环。
我们构建Hash环为0 ~ 2^32,如图:
然后我们Slave节点登陆的时候,也进行一次SlaveKeyHash操作:
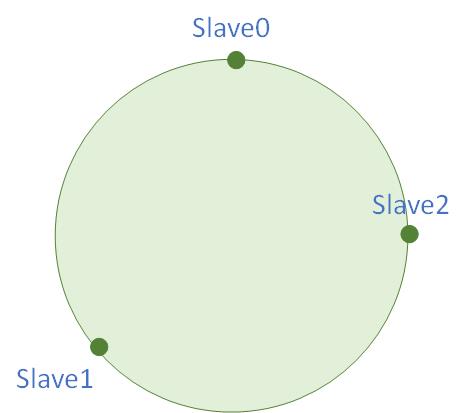
那么Slave0对应的Hash环上点就是到下一个Slave节点的位置:
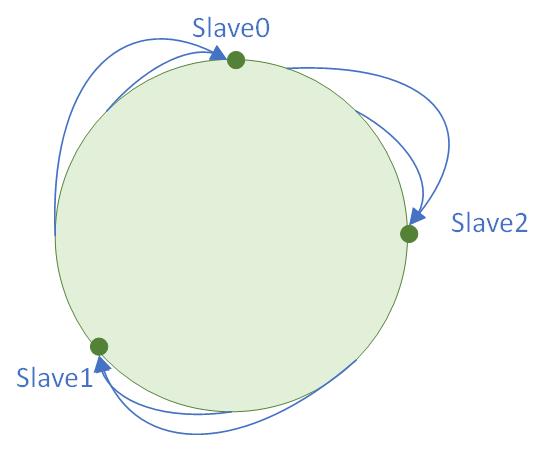
如果这个时候新增了一个节点,那么HashSlot就回被分配如:
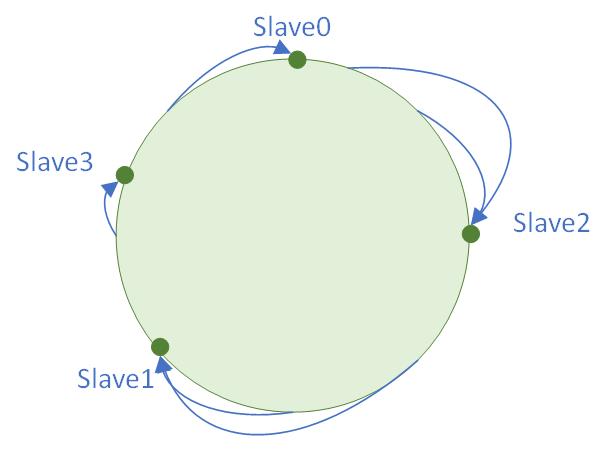
这样的话就能适配到新增和退役节点的变化,并且尽量减少影响变化。
二次优化
上面有优点但也有缺点,如果不行出现Hash(SlaveKey)的距离过段或者过长,就会导致整体Slave节点的不均衡如:
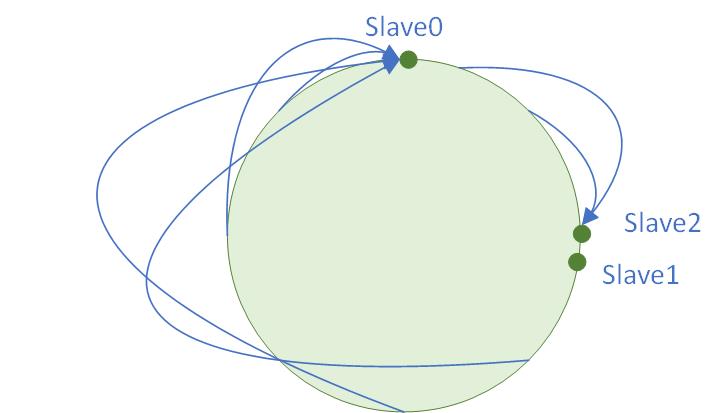
上面Slave2和Slave1的hash结果过于接近,导致Slave1的负载过低,Slave0的负载过高,那么有什么解决办法呢?
其实也很简单,直接让每个点进行一些扩容,最简单的操作就是添加一些不同的Salt值如:Slave0变成Slave0#1、Salve0#1、Slave0#3。这样随机的N个点变为N*M个散列点进行负载操作。这样当随机点足够多的时候,他们就能够足够均匀的分配负载:
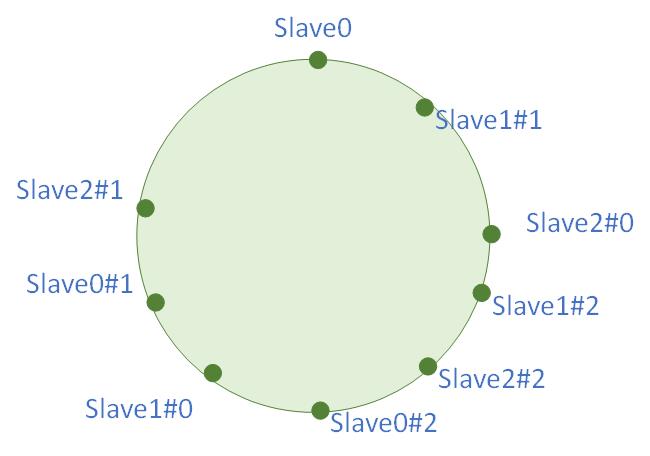
Redis HashSlot
在Redis Cluster中的哈希算法是用来判断用户上传的一个Key,value应该保存在哪一个节点之中(集群模式Redis有多台主节点,每台主节点对应一台或多台备节点)。
Redis类似于有16384大小的Hash环,具体算法为:
H
A
S
H
_
S
L
O
T
=
C
R
C
16
(
M
e
s
s
a
g
e
K
e
y
)
m
o
d
16384
HASH\\_SLOT=CRC16(MessageKey)\\ mod\\ 16384
HASH_SLOT=CRC16(MessageKey) mod 16384
当我们有三个节点的时候,他们会平均分配所占有的槽位:
- 节点A覆盖0-5460;
- 节点B覆盖5461-10922;
- 节点C覆盖10923-16383.
如果这个时候新增了一个节点,那这个节点会向之前的节点抢夺一些Slot:
- 节点A覆盖1365-5460
- 节点B覆盖6827-10922
- 节点C覆盖12288-16383
- 节点D覆盖0-1364,5461-6826,10923-12287
如果A节点被删除了,那么A节点的Slot会被移动到其他节点,然后删除空白A节点就可以了。
这里可能有人问其实CRC16算法产生的为
2
1
6
−
1
=
65535
2^16-1=65535
216−1=65535
个映射,但只是用了16384个,这个涉及到Redis自身的考量,感兴趣的可以去查查。
所以Redis 的实现Hash我认为并不是最有解,但是他主打的也并不是Slot槽这点,而是主从复制,高可用性,而且可以自己分配槽位,方便管理。

以上是关于Hash一致性算法的主要内容,如果未能解决你的问题,请参考以下文章