论文解读: Learning to AutoFocus
Posted Matrix_11
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读: Learning to AutoFocus相关的知识,希望对你有一定的参考价值。
论文解读: Learning to AutoFocus
今天介绍谷歌计算摄影团队的一篇新文章,Learning to AutoFocus,发表在 CVPR 2020 上。
在摄影中,自动对焦是一个非常重要的环节,相信绝大多数的用户,对于 AF 的要求都是又快又准,相机由于镜头的特性,一般来说只能在一定范围内成像清晰,这个范围叫做景深,为了能让自己关注的区域成像清晰,都需要用到对焦技术,这篇文章也是用上了深度学习的方法来实现的,可以看到,深度学习已经在 low-level 的图像处理中发挥着越来越重要的作用了。
对焦一般来说包含两个环节,一是对焦区域的选择,也就是我们说的 ROI,在图像中,到底选择哪个区域进行对焦,这也是一个比较重要的步骤,现在的手机摄影在智能识别这块已经非常成熟了,一般都有一些自动识别 ROI 的方法,比如人脸检测,检测到人脸的时候,就会优先对焦到人脸,还有一些先验规则,比如中心区域对焦。第二步就是对焦了,其实对焦简单来说就是估计深度,因为我们的世界是三维的,虽然图像是二维的,但是我们拍摄的时候,其实是对三维世界进行成像,选定好 ROI 之后,需要估计该 ROI 所处的深度,这样才能移动镜头,将对焦面选择 ROI 所对应的深度,从而获得正确的景深,所以自动对焦技术,一般是指根据所选择的 ROI 确定对焦距离,并且快速的移动镜头完成对焦的过程。
目前主流的对焦技术一般分为两大类,一类是基于反差的对焦技术,contrast based auto focus;另外一类是基于相位检测的对焦技术,phase detection auto focus。基于反差的对焦技术比较好理解,就是镜头在移动的时候,图像会在某些距离变得模糊,模型距离下又很清晰,可以利用一些图像质量评估的准则,看图像什么时候最清楚,进而确定对焦距离,基于相位的对焦技术是最近才发展起来的,之前在单反上用到的比较多,单反上为了实现相位对焦技术,设计了非常复杂的光路,现在随着 sony 的 dual pixel 技术,手机上也开始使用相位对焦技术。相位对焦技术是利用了双目立体视觉原理,我们都知道,根据双目,我们是可以估计场景深度的,因为双目对环境中的物点会产生视差,而相位对焦技术,就是利用了双目的视差来进行对焦。
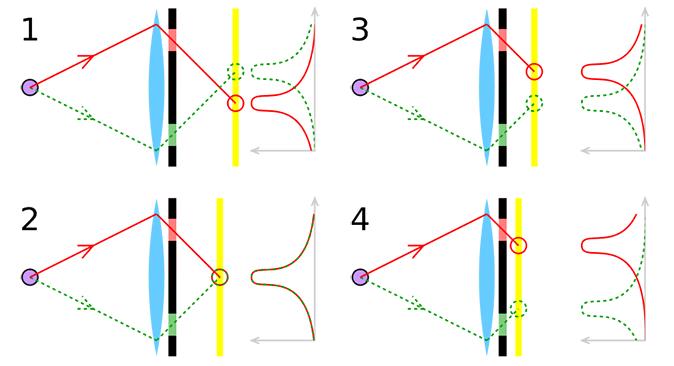
如上图所示,如果对焦准确的话,那么物点发出的光线将在相面汇聚成一点,这个时候没有视差,反之,如果对焦不准确,那么物点发出的光线无法汇聚成一点,而是会被分成两部分,分别被左右两个 pixel 所接收,由于透镜折射光线的性质,可以看到,前景和后景的双目图像是不同的,这样可以区分出当前所处的物面是在焦平面的前面还是后面,从而可以引导镜头的移动。
这篇文章直接用基于学习的方式来处理这个 AF 问题,从文章的介绍来看,网络结构和训练方式都不是特别 novelty,可能构造数据是一个 contribution,还有就是用深度学习的方法来预测对焦,也是一个不错的尝试吧。
这个网络的输入是一个 focal stack,也就是不同对焦距离下图像序列,简单来说,文章就是把 AF 问题,转换成一个图像序列的选帧问题,这个图像序列的每一帧对应不同的对焦距离,根据选择的帧,来确定对焦距离。
文章的方法是将连续的对焦距离先离散化成 n n n 个,这样可以获得 n n n 张不同对焦距离下的图, I k , k ∈ 1 , 2 , . . . n I_k, k \\in \\ 1,2,...n \\ Ik,k∈1,2,...n,这样一组图像称为 focal stack, 每帧图像称为 focal slice, k k k 是对应的 slice 下标,称为 focal index,根据使用的图像数量的不同,AF 的算法又可以分成以下几种,如下图所示:
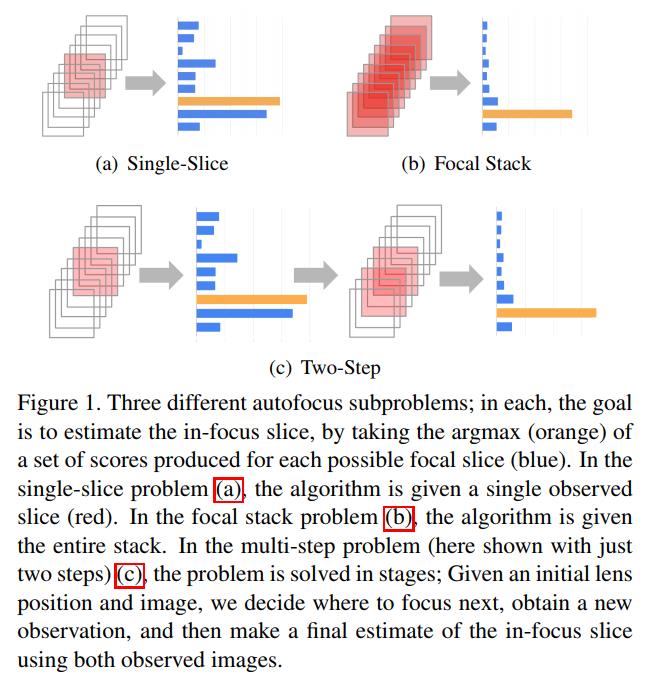
- Focal stack
这类算法,需要从整个 focal stack 中,找到最佳的 focal index:
f : I k ∣ k = 1 , 2 , . . . n → k ∗ f: \\ I_k | k=1, 2, ...n \\ \\rightarrow k^* f:Ik∣k=1,2,...n→k∗
一般基于反差的对焦方法都得这么干,需要遍历整个 focal stack,然后才能选择出最佳的一个对焦距离。
- Single slice
f : I k → k ∗ , ∀ k ∈ 1 , 2 , . . . n f: I_k \\rightarrow k^*, \\forall k \\in \\ 1, 2, ... n \\ f:Ik→k∗,∀k∈1,2,...n
这种方法应该是最具挑战的,直接从一帧图中,估计出最佳的对焦距离。
- Multi step
f 1 : I k 0 → k 1 f 2 : I k 0 , I k 1 → k 2 . . . f m : I k 0 , . . . , I k m − 1 → k m f_1: I_k_0 \\rightarrow k_1 \\\\ f_2: I_k_0, I_k_1 \\rightarrow k_2 \\\\ ... \\\\ f_m: I_k_0, ..., I_k_m-1 \\rightarrow k_m f1:Ik0→k1f2:Ik0,Ik1→k2...fm:Ik0,...,Ikm−1→km
k 0 ∈ i , 2 , . . . n k_0 \\in i, 2, ... n k0∈i,2,...n, m m m 表示事先设定好的一个值,表示迭代最多进行 m m m 次,
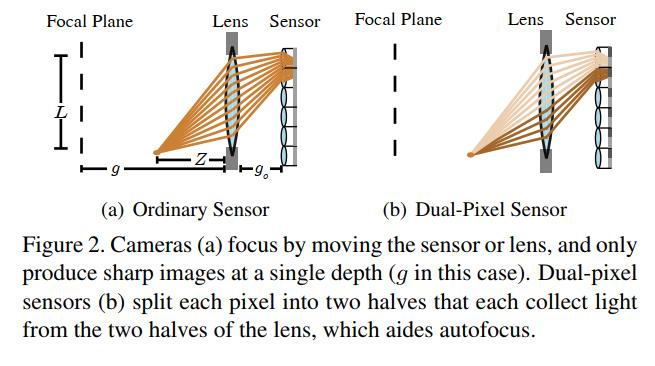
文章接下来探讨了 AF 面临的挑战,文章给出了对焦距离与离焦程度的关系:
L f 1 − f / g ( ∣ 1 g − 1 Z ∣ ) \\fracLf1 - f/g \\left( |\\frac1g - \\frac1Z| \\right) 1−f/gLf(∣g1−Z1∣)
其中, L L L 表示光圈孔径大小, f f f 表示 focal length, Z Z Z 表示选择的场景深度, g g g 表示需要对焦距离, g g g 和镜头与sensor 之间的距离 g 0 g_0 g0 有关,一般来说给定 L , f L, f L,f 以及 Z Z Z,通过调整 g 0 g_0 g0 可以得到清晰的图像,所以一般来说,如果能够准确的估计场景深度,可以很好的实现对焦,dual-pixel sensor 可以通过两张子图很好地达到这个目的,视差可以满足如下的关系式:
d = α L f 1 − f / g ( 1 g − 1 Z ) d = \\alpha \\fracLf1 - f/g \\left( \\frac1g - \\frac1Z \\right) d=α1−f/gLf(g1−Z1)
如下图所示:
不过文章也指出,这种基于 defocus 的方法在实际应用中,也会受到一些假设的限制,文章列举了四点:
- Unrealistic PSF Models,我们可以通过 defocus 的程度来判断对焦是否准确,defocus 就类似一个清晰图像与一个 PSF 的卷积,一般我们会假设 PSF 类似一个高斯分布的函数,不过实际场景中,PSF 的形态会比这复杂,从而大的 PSF 不一定会导致更 blur 的图像
- Noise in Low Light Environments,暗光下的噪声,会影响很大东西,包括视差的估计,反差的估计,这个应该是比较好理解的了
- Focal Breathing,这个在我们实际拍摄的时候,有的时候会遇到,就是在对焦的时候,你会看到预览画面一会儿清晰,一会儿模糊,这个也是经常会遇到的问题。
- Hardware Support,现在的智能手机都会用 voice coil motors (VCMs) 来操控镜头模组,VCM 可以通过调整电压来移动镜头,不过 VCM 也会带来误差,从而导致对焦出现偏差。
这篇文章就提出了一种基于学习方法来解决自动对焦问题。既然是基于学习的方法,首先需要解决的就是数据集的问题,为了得到一个有效,鲁棒的模型,数据集的规模和质量是非常关键的,模型需要通过数据集来学习预测能力。

这篇文章的目的是解决对焦问题,所以输入是一组不同对焦距离下的图像,输出是最佳对焦距离的预测,这篇文章选择的对焦距离是从 0.102m 到 3.91m,分成了 49 等分,文章用到的网络模型是 Mobilenet-V2,以往的输入是 RGB 三通道图像,现在的输入就换成了 focal stack,如果有 49 张图,那么输入就是 49 个通道的图像,如果是 dual pixel 的形式,那么输入就是 98 个通道的图像。文章和通常的分类识别问题有点区别,区别之处就在于这个模型是 ordinal regression problem,简单来说,顺序是有一定相关性的,不像一般的分类问题,顺序是无关的。
这篇文章介绍的还是比较详细的,而且作者也公布了代码。
- Reference:
https://photographylife.com/how-phase-detection-autofocus-works
以上是关于论文解读: Learning to AutoFocus的主要内容,如果未能解决你的问题,请参考以下文章