GraphX 图数据建模和存储
Posted 张包峰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GraphX 图数据建模和存储相关的知识,希望对你有一定的参考价值。
背景
简单分析一下GraphX是怎么为图数据建模和存储的。
入口
可以看GraphLoader的函数,
def edgeListFile(
sc: SparkContext,
path: String,
canonicalOrientation: Boolean = false,
numEdgePartitions: Int = -1,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY)
: Graph[Int, Int]- path可以是本地路径(文件或文件夹),也可以是hdfs路径,本质上是使用sc.textFile来生成HadoopRDD的,numEdgePartitions是分区数。
- Graph的存储是分EdgeRDD和VertexRDD两块,可以分别设置StorageLevel。默认是内存。
- 这个函数接受边文件,即’1 2’, ‘4 1’这样的点到点的数据对组成的文件。把这份文件按分区数和存储level转化成一个可以操作的图。
流程
- sc.textFile读文件,生成原始的RDD
- 每个分区(的计算节点)把每条记录放进PrimitiveVector里,这个结构是spark里为primitive数据优化的存储结构。
- 把PrimitiveVector里的数据一条条取出,转化成EdgePartition,即EdgeRDD的分区实现。这个过程中生成了面向列存的结构:src点的array,dst点的array,edge的属性array,以及两个正反向map(用于对应点的local id和global id)。
- 对EdgeRDD 做一次count触发这次边建模任务,真正persist起来。
- 用EdgePartition去生成一个RoutingTablePartition,里面是vertexId到partitionId的对应关系,借助RoutingTablePartition生成VertexRDD。
- 由EdgeRDD和VertexRDD生成Graph。前者维护了边的属性、边两头顶点的属性、两头顶点各自的global vertexID、两头顶点各自的local Id(在一个edge分区里的array index)、用于寻址array的正反向map。后者维护了点存在于哪个边的分区上的Map。
以下是代码,比较清晰地展现了内部存储结构。
private[graphx]
class EdgePartition[
@specialized(Char, Int, Boolean, Byte, Long, Float, Double) ED: ClassTag, VD: ClassTag](
localSrcIds: Array[Int],
localDstIds: Array[Int],
data: Array[ED],
index: GraphXPrimitiveKeyOpenHashMap[VertexId, Int],
global2local: GraphXPrimitiveKeyOpenHashMap[VertexId, Int],
local2global: Array[VertexId],
vertexAttrs: Array[VD],
activeSet: Option[VertexSet])
extends Serializable /**
* Stores the locations of edge-partition join sites for each vertex attribute in a particular
* vertex partition. This provides routing information for shipping vertex attributes to edge
* partitions.
*/
private[graphx]
class RoutingTablePartition(
private val routingTable: Array[(Array[VertexId], BitSet, BitSet)]) extends Serializable 细节
分区摆放
EdgeRDD的分区怎么切分的呢?因为数据是根据HadoopRDD从文件里根据offset扫出来的。可以理解为对边数据的切分是没有任何处理的,因为文件也没有特殊排列过,所以切分成多少个分区应该就是随机的。
VertexRDD的分区怎么切分的呢?EdgeRDD生成的vertexIdToPartitionId这份RDD数据是RDD[VertexId, Int]型,它根据hash分区规则,分成和EdgeRDD分区数一样大。所以VertexRDD的分区数和Edge一样,分区规则是Long取hash。
所以我可以想象的计算过程是:
对点操作的时候,首先对vertexId(是个Long)进行hash,找到对应分区的位置,在这个分区上,如果是内存存储的VertexRDD,那很快可以查到它的边所在的几个Edge分区的所在位置,然后把计算分到这几个Edge所在的分区上去计算。
第一步根据点hash后找边分区位置的过程就类似一次建好索引的查询。
配官方图方面理解:
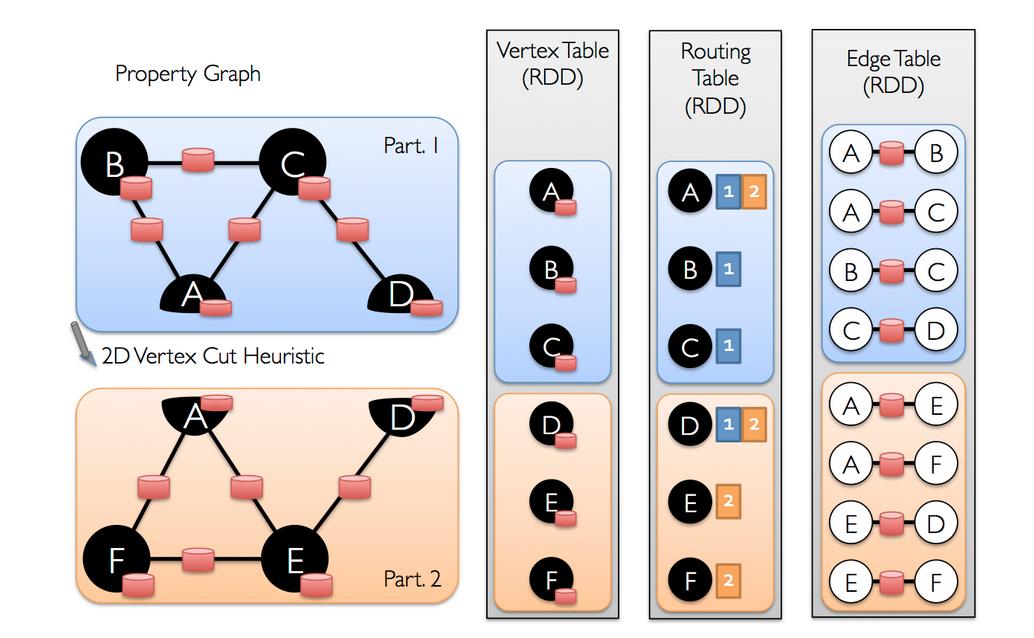
高效数据结构
对原生类型的存储和读写有比较好的数据结构支持,典型的是EdgePartition里使用的map:
/**
* A fast hash map implementation for primitive, non-null keys. This hash map supports
* insertions and updates, but not deletions. This map is about an order of magnitude
* faster than java.util.HashMap, while using much less space overhead.
*
* Under the hood, it uses our OpenHashSet implementation.
*/
private[graphx]
class GraphXPrimitiveKeyOpenHashMap[@specialized(Long, Int) K: ClassTag,
@specialized(Long, Int, Double) V: ClassTag](以及之前提到的vector
/**
* An append-only, non-threadsafe, array-backed vector that is optimized for primitive types.
*/
private[spark]
class PrimitiveVector[@specialized(Long, Int, Double) V: ClassTag](initialSize: Int = 64)
private var _numElements = 0
private var _array: Array[V] = _全文完 :)
以上是关于GraphX 图数据建模和存储的主要内容,如果未能解决你的问题,请参考以下文章