theano-windows学习笔记二十——LSTM理论及实现
Posted 风翼冰舟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了theano-windows学习笔记二十——LSTM理论及实现相关的知识,希望对你有一定的参考价值。
前言
上一篇学习了RNN,也知道了在沿着时间线对上下文权重求梯度的时候,可能会导致梯度消失或者梯度爆炸,然后我们就得学习一波比较常见的优化方法之LSTM
国际惯例,参考网址:
LSTM Networks for Sentiment Analysis
简介
传统的循环神经网络RNN在梯度反传阶段,梯度信号经常被上下文连接权重矩阵乘很多次(与时间戳的数目一直),这就意味着转移矩阵的权重大小对学习过程有很大的影响。
如果权重很小(权重矩阵的最大特征值小于1),就会导致梯度消失,梯度信号变得很小,学习就会变得很慢或者停止学习了。这使得对具有长时依赖数据的学习变得困难。反之,如果权重很大(权重值大于1),就会导致梯度信号很大,造成学习发散,这通常称为梯度爆炸。
LSTM模型主要就是引入了记忆单元来减轻这些问题,一个记忆单元包含四个主要成分:输入门,自连接,遗忘门,输出门。自连接权重是1,不受任何外部干扰,记忆单元的状态从一个时间戳到另一个时间戳保持常量。门是为了模拟记忆单元间自身与环境的交互。输入门允许输入信改变记忆单元的状态或者阻止它。输出门允许记忆单元的状态影响到其它单元或者是组织它。遗忘门模拟记忆单元自身的循环连接,允许单元记住或者忘记之前的状态。
理论
下图对比的是传统RNN与具有记忆单元的LSTM的拓扑结构:
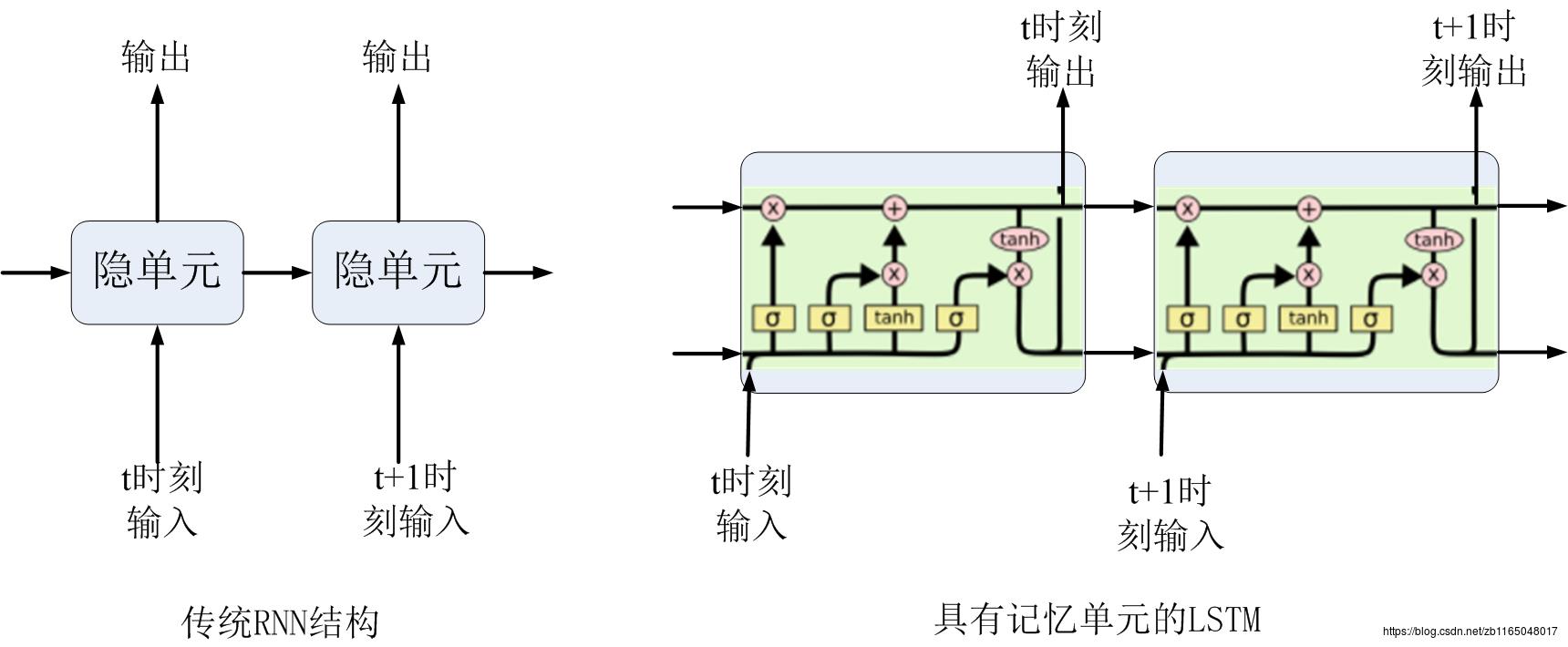
可以发现LSTM与RNN的区别在于后者多了一条线,上行线是记忆信息按时间传递,下行线是与RNN相同的隐层信息按时间传递。
这个记忆细胞的连接看着挺复杂的,虽然暂时看到记住了,但是过段时间肯定忘记,这个得理解性记忆,看看每一部分都代表什么吧,看样子这个记忆单元主要包含三个连接部分,如下图红圈所示:
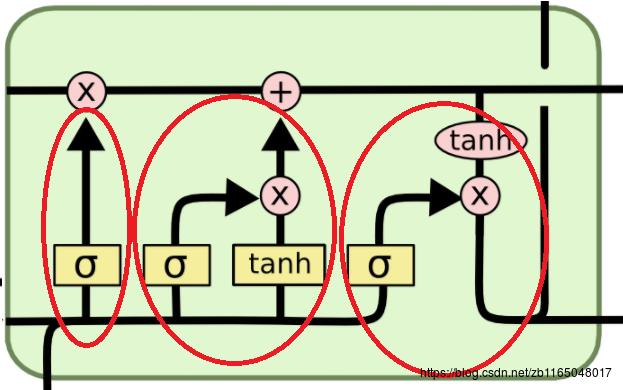
接下来就对这些红圈分别理解,接下来的博文是对第二篇参考博客的翻译与理解,看原文请直接戳前言。
第一部分
ft=σ(Wfxt+Ufht−1+bf) f t = σ ( W f x t + U f h t − 1 + b f )
决定即将通过记忆单元的信息是什么,通过一个由sigmoid层构成的遗忘门决定,此门接收的输入包含原始数据的输入与上一时刻的隐状态,计算结果即:
比如语言建模中,想基于之前所有的状态预测下一个词,记忆状态可能包括主语的性别,这样才能使用正确的代词(他/她),当新的主语出现,我们可能要忘记之前的主语性别。第二部分
it=σ(Wixt+Uiht−1+bi) i t = σ ( W i x t + U i h t − 1 + b i )
决定什么信息可以被存储在记忆单元中,分为两个部分:
①一个sigmoid层称为输入门决定将更新什么值;
②tanh层计算新的候选值向量 Ct^ C t ^ ,这个值可以被加到状态中。下一步就是将这两个值结合起来更新状态
Ct^=tanh(Wcxt+Ucht−1+bc) C t ^ = tanh ( W c x t + U c h t − 1 + b c )
如果按照语言建模的例子,这部分做的就是,我们想将新的主语性别加入到单元状态中,去替代想忘记的旧的主语的性别。结合第一部分和第二部分
Ct=it∗Ct^+ft×Ct−1 C t = i t ∗ C t ^ + f t × C t − 1
我们已经计算了想传递什么,以及是否去忘记它,怎么去更新状态。
假设旧的记忆状态是 Ct−1 C t − 1 ,想要更新到 Ct C t ,之前我们已经计算了去做什么,现在我们只需要做它就行了,方法就是将 ft f t 与旧状态相乘即可忘记那些早想忘记的事情。
之后将 it×Ct^ i t × C t ^ 加进去,这是新的候选值,并且依据对于每个状态我们所决定的更新量去缩放它。
这就相当于在语言模型中,我们确实丢失了旧主语的性别信息,并且新增了我们在上一步已经决定添加的新信息。第三部分
otht=σ(Woxt+Uoht−1+bo)=ot×tanh(Ct) o t = σ ( W o x t + U o h t − 1 + b o ) h t = o t × tanh ( C t )
最后就是决定我们要输出啥。这个输出单元状态,但是需要被过滤一下。首先使用sigmoid决定哪一部分单元状态需要被输出,然后将单元状态通过tanh(将值归一化到-1至1),使用sigmoid遗忘门的输出乘以它,因此就仅仅会输出我们想要的那部分。
还是语言建模的例子,一旦见到一个主语,就想输出相关的动词相关的信息,比如是单数还是复数,这样我们可以知道所连接 的动词形式。
总结一波,假如面试的时候,面试官让你画LSTM的结构图,怎么下手?
①首先一个框,竖着两条线分别代表输入输出,再横着两条线,一条是隐层的自连接,一条是记忆单元的信息传递。就相当于先画个RNN,然后横着添一条记忆线就行。
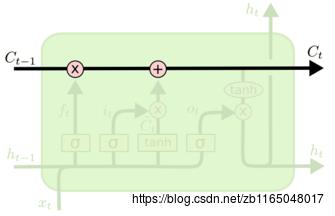
②画第一个单元:决定需要传递的信息,连接输入和隐层,使用sigmoid激活
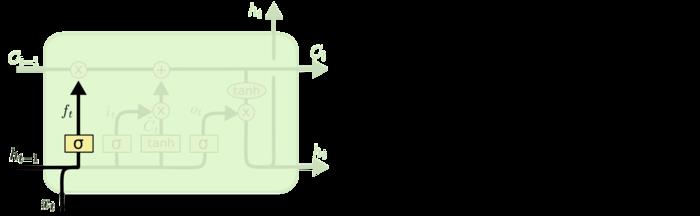
③画第二个单元:更新记忆单元状态,连接输入和隐层,分别使用sigmoid和tanh激活
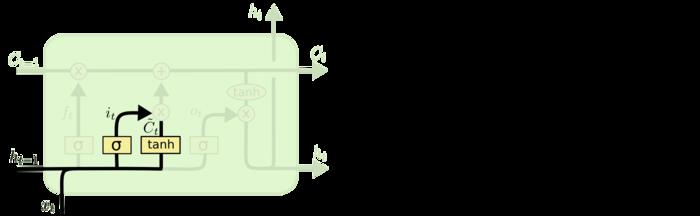
④连接第一二个单元:第一个单元的输出与历史细胞状态做乘积,第二个单元的sigmoid和tanh做乘积,然后与前一个单元做加和
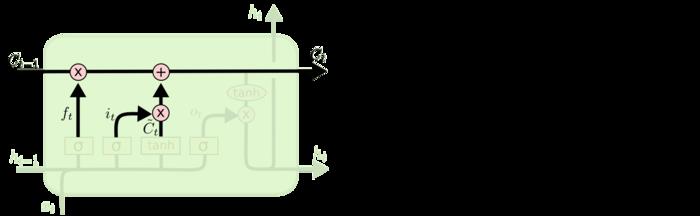
⑤画第三个单元:确定输出,依旧是连接输入和隐层,使用sigmoid激活得到
ot
o
t
,将第一二部分更新的状态值使用tanh归一化一下与
ot
o
t
相乘即可得到隐层输出。
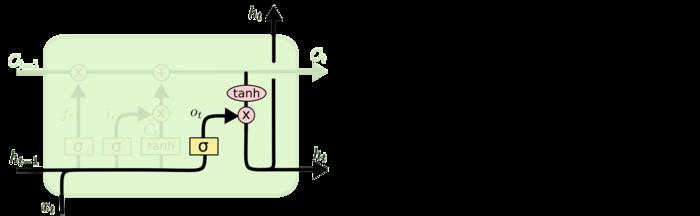
其实整个流程就是:决定更新啥,更新状态,确定输出。
实例
主要有官方提供的两个实例以及自己修改的将LSTM套入到上一篇RNN博客的序列预测中。官方实例戳这里,基本无需配置,下载那几个文件就能用了,文末我也会放网盘。
另一个实例是我自己将上一篇RNN的博客中代码替换成LSTM的理论进行序列预测,原始的Elman-RNN的循环代码如下:
def step(x_t,h_tm1):
h_t=self.activation(T.dot(x_t,self.W_in)+ T.dot(h_tm1,self.W)+self.bh)
y_t=T.dot(h_t,self.W_out)+self.by
return h_t,y_t
[self.h,self.y_pred],_=theano.scan(step,sequences=self.input,outputs_info=[self.h0,None])改成LSTM就是:
#针对LSTM对RNN做相关改进
def step(x_t,h_tm1,C_tm1):
preact=T.dot(x_t,self.W_in)+ T.dot(h_tm1,self.W)+self.bh
f_t=T.nnet.sigmoid(preact)
i_t=T.nnet.sigmoid(preact)
hatC_t=T.tanh(preact)
C_t=i_t*hatC_t+f_t*C_tm1
o_t=T.nnet.sigmoid(preact)
h_t=o_t*T.tanh(C_t)
y_t=T.dot(h_t,self.W_out)+self.by
return h_t,C_t,y_t
[self.h,self.C_t,self.y_pred],_=theano.scan(step,sequences=self.input,outputs_info=[self.h0,self.C0,None])但是比较奇怪的是,实验效果竟然
以上是关于theano-windows学习笔记二十——LSTM理论及实现的主要内容,如果未能解决你的问题,请参考以下文章