Go中的特殊协程g0
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go中的特殊协程g0相关的知识,希望对你有一定的参考价值。
参考技术A 【译文】 原文地址本文基于go 1.13版本
所有在Go中创建的goroutines都由一个内部调度程序的管理。Go调度程序试图给所有的goroutines分配运行时间,并且在当前goroutine被阻塞或终止情况下也能使CPU忙于运行其他goroutines。
Go通过GOMAXPROCS变量来限制操作系统线程同时运行的数量。这意味着,Go必须在每个正在运行的线程上调度和管理所有的goroutines。这个角色通过一个特殊的goroutine来完成,称为g0,这是为每个操作系统线程创建的第一个goroutine:
当goroutine被阻塞在channel上时,当前的goroutine就会被挂起,即处于等待模式将不会推入任何goroutines队列中。
收到消息的goroutine将切换到g0,然后将挂起的goroutine放入到本地调度队列中:
尽管g0这个特殊goroutine是管理调度的,但是它不止这些工作还有其他更多的功能。
与普通goroutine相反,g0有固定且比较大的栈。这允许Go在需要更大栈时,还能执行操作。g0的职责可以如下:
通俗易懂的Go协程的引入及GMP模型简介
本文根据Golang深入理解GPM模型加之自己的理解整理而来
一、协程的由来
1. 单进程操作系统
早期的单进程操作系统每个进程/线程(cpu无法区别线程还是进程)都是顺序执行的,

带来了两个问题:
- 单一执行流程,计算机只能一个任务一个任务的进行处理
- 进程阻塞带来的cpu时间浪费
2. 多线程/多进程操作系统
针对以上不足,引出了多线程/多进程操作系统
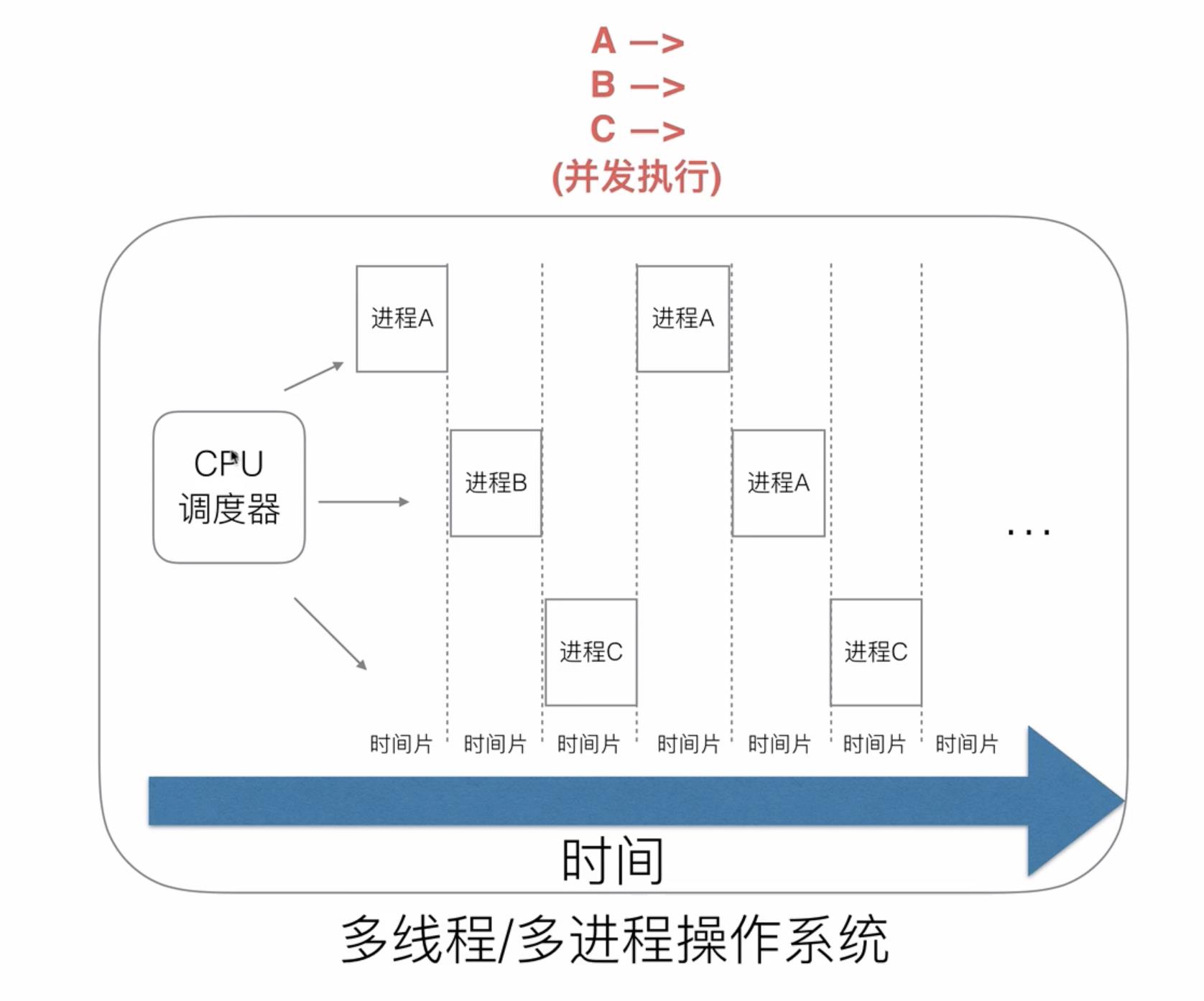
这种方式解决了多线程/多进程间的阻塞问题,但该方式又引入了新的问题,就是切换成本问题,从一个线程切换到下一个线程的时候需要保存当前线程的状态,会涉及各种系统调用、上下文切换、拷贝复制,这些东西我们称之为cpu浪费时间成本。
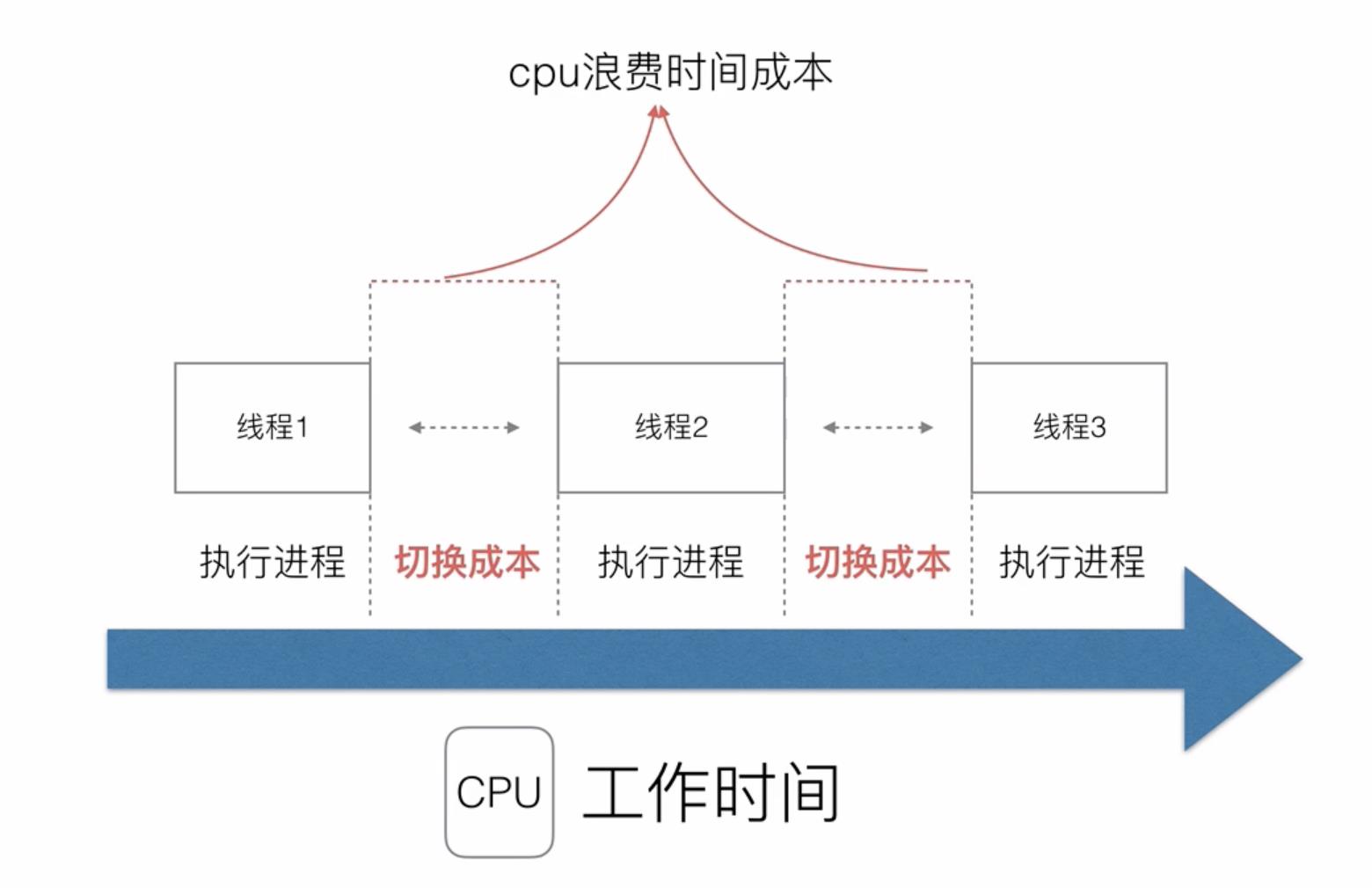
这样会导致,如果进程/线程的数量过多的情况下,切换成本就更大,cpu利用率大大降低,一个cpu看起来可能满负载,但其实其中只有%50用来执行真正的程序,剩余时间都在进行频繁的线程切换。
不仅如此,多线程还往往伴随着同步竞争的问题,因此开发设计越来越复杂,在实际运行中,为了达到更好的并发效果,我们往往给单独的任务分配一个线程进行执行,当任务越来越多的情况下,不仅会造成cpu高消耗调度的问题,还会出现高内存占用的问题,在一个32的操作系统中,往往一个进程会占用4g的虚拟内存,一个线程会占用4m左右内存。
因此 提高cpu利用率、减小内存消耗 才是当今需要解决的事情,那么怎么优化呢?
3. 引入协程
一个线程分为内核态和用户态两个部分,于是工程师们想着将这两部分分开,将一个线程分为用户线程、内核线程两部分,两者之间进行绑定,这样就可以各司其职,内核线程专门用来与硬件底层进行一些交互,而用户线程用来保证业务层面的并发效果,而且这样cpu的视野就只有内核线程,只与内核线程进行交互
将一个线程分开两部分以后,我们将其中的用户空间的部分称之为协程,将内核空间部分称之为线程
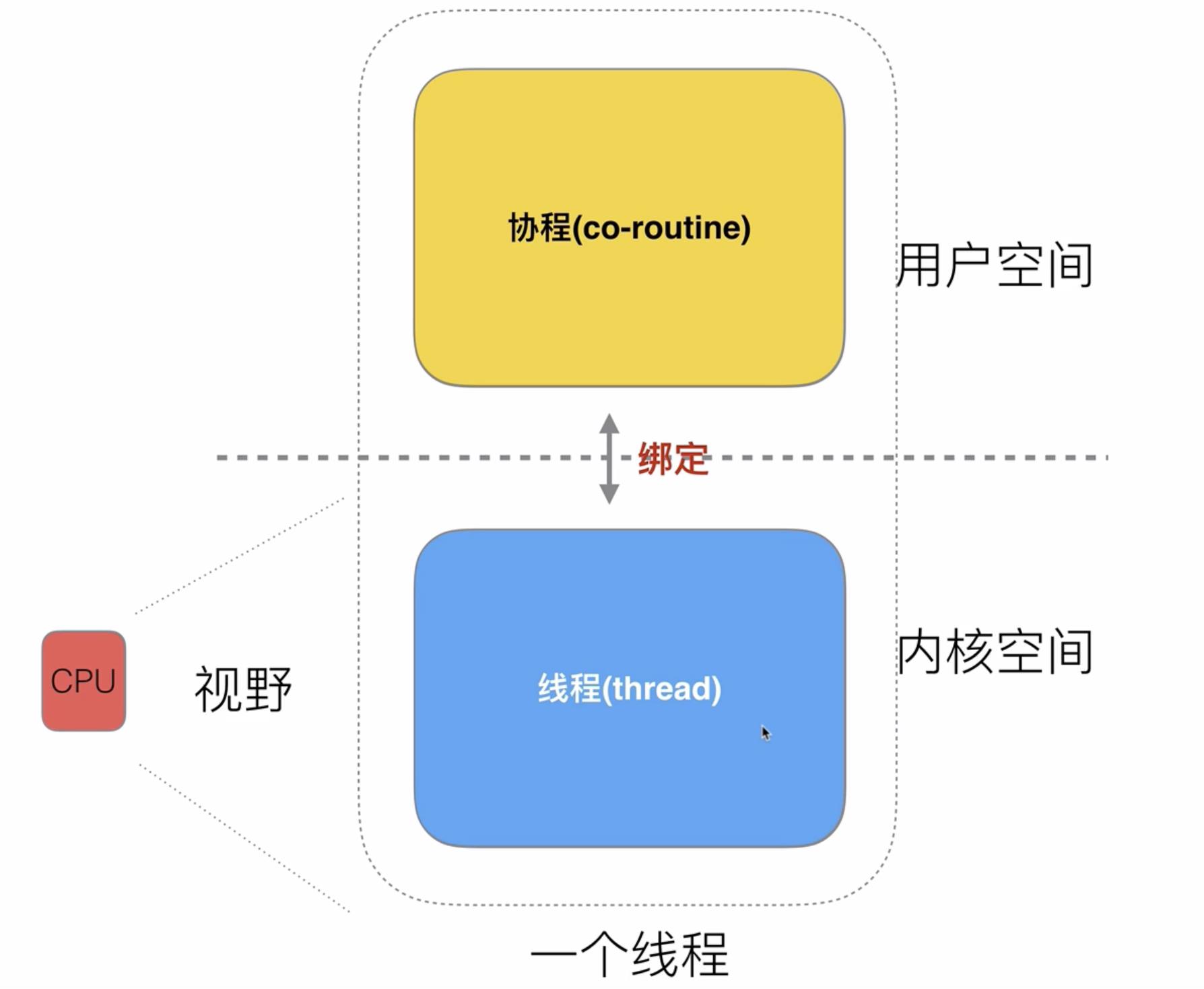
在以上基础上,可以进行进一步优化, 我们可以让一个(内核)线程通过一个协程调度器来绑定多个协程,这样cpu调度时无感,还是只针对(内核)线程,但是上层开了多个协程后,可以让每一个协程挂载一个任务,这样在用户态能够保证并发效果,且由于cpu只针对内核空间的线程,多个协程之间cpu是不需要切换的,这样就解决了前面高消耗cpu的瓶颈
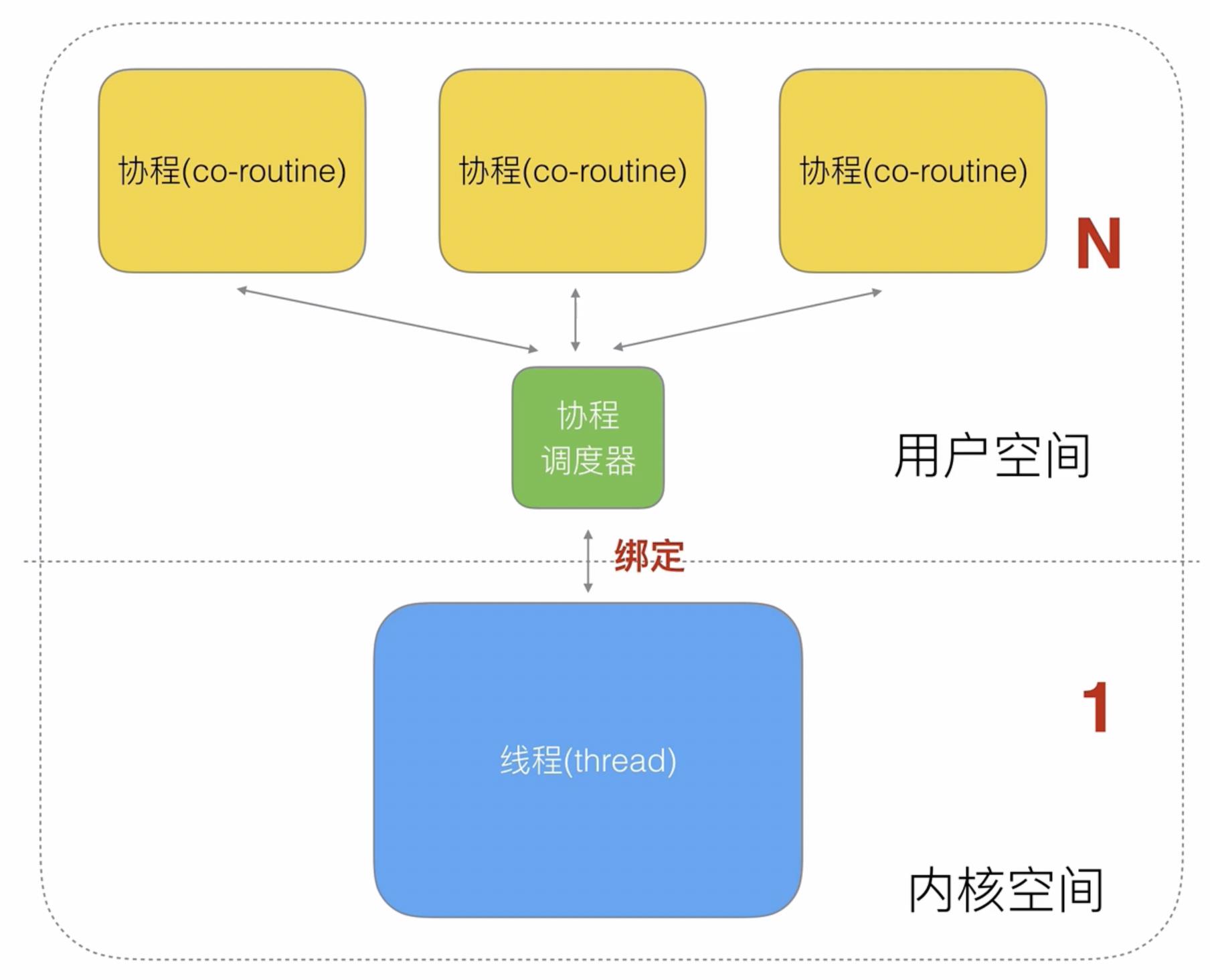
也就形成了上图一个线程对应多个协程的关系,当今计算机都是多核的,因此线程和协程之间往往采用以下多对多的方式,每个cpu针对一个线程来绑定多个协程,这样可以达到更好的并发效果
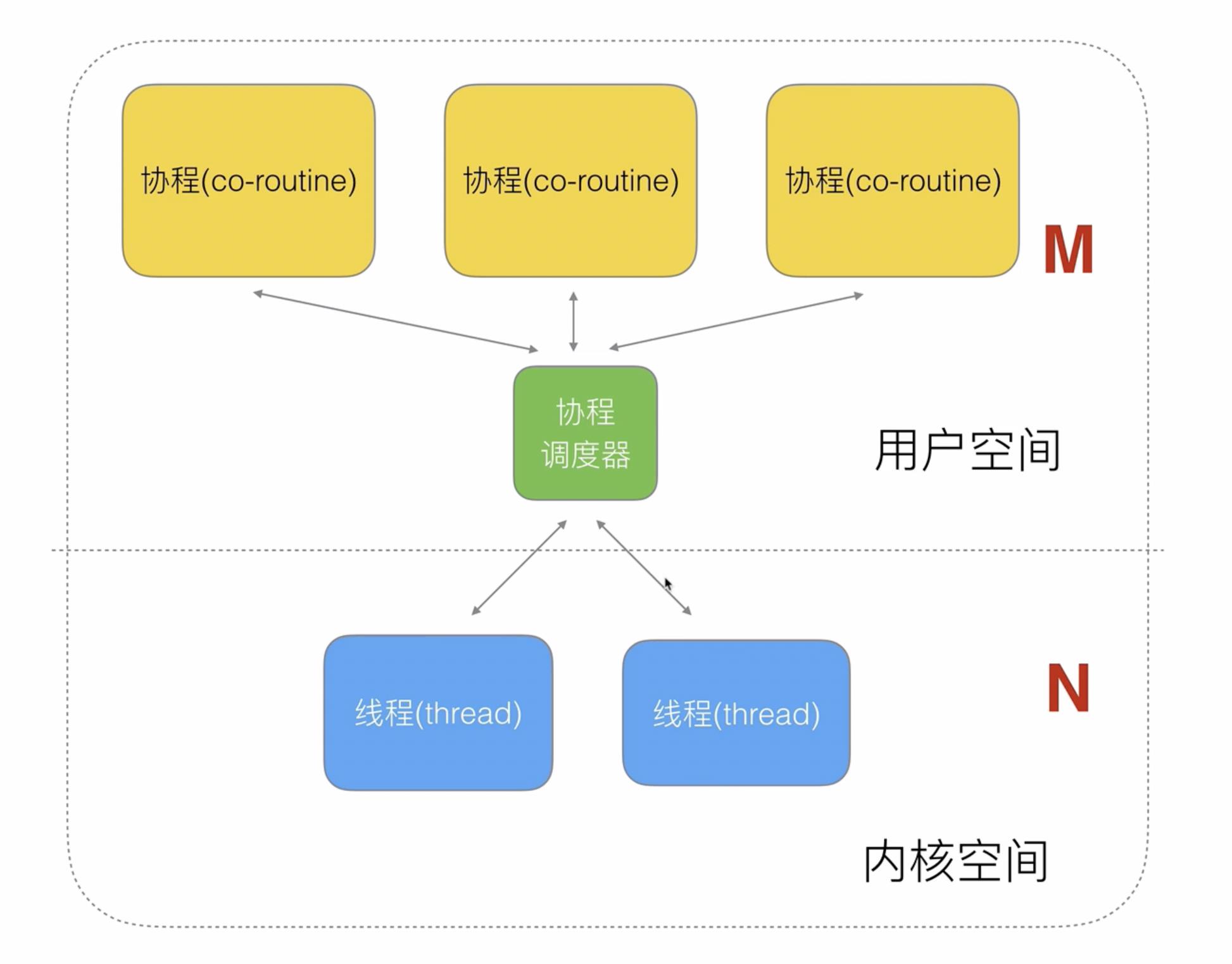
由于内核空间的cpu对线程的调度无法干涉,因此优化的主要目标移动到了用户空间里对协程调度器的优化,如果对其进行优化能够达到更高的并发性。
二、golang对协程的处理
1. 对co-routine对处理
golang在对协程调度器处理之前,首先对co-routine协程进行了处理,首先将其改名字为goroutine,其次修改了goroutine的所占的内存大小,砍掉了多余不必要的空间,使得每个goroutin所占内存大小为几kb,实现了可以存在大量的goroutine,解决了高内存消耗的问题。
2. 对调度器的优化(早期)
然后便对协程调度器进行了优化,实现了灵活调度

golang早期调度器形式如下图所示,协程与线程之间是多对多的关系,其中维护了一个全局的goroutine队列,每创建一个协程,都将起放到这个队列中。当其中的线程要调度协程时,首先会获取全局队列的锁,然后尝试去执行goroutine,队列中剩余goroutine向队列头移动,当执行完后,将 执行完的goroutine放回队列尾部。
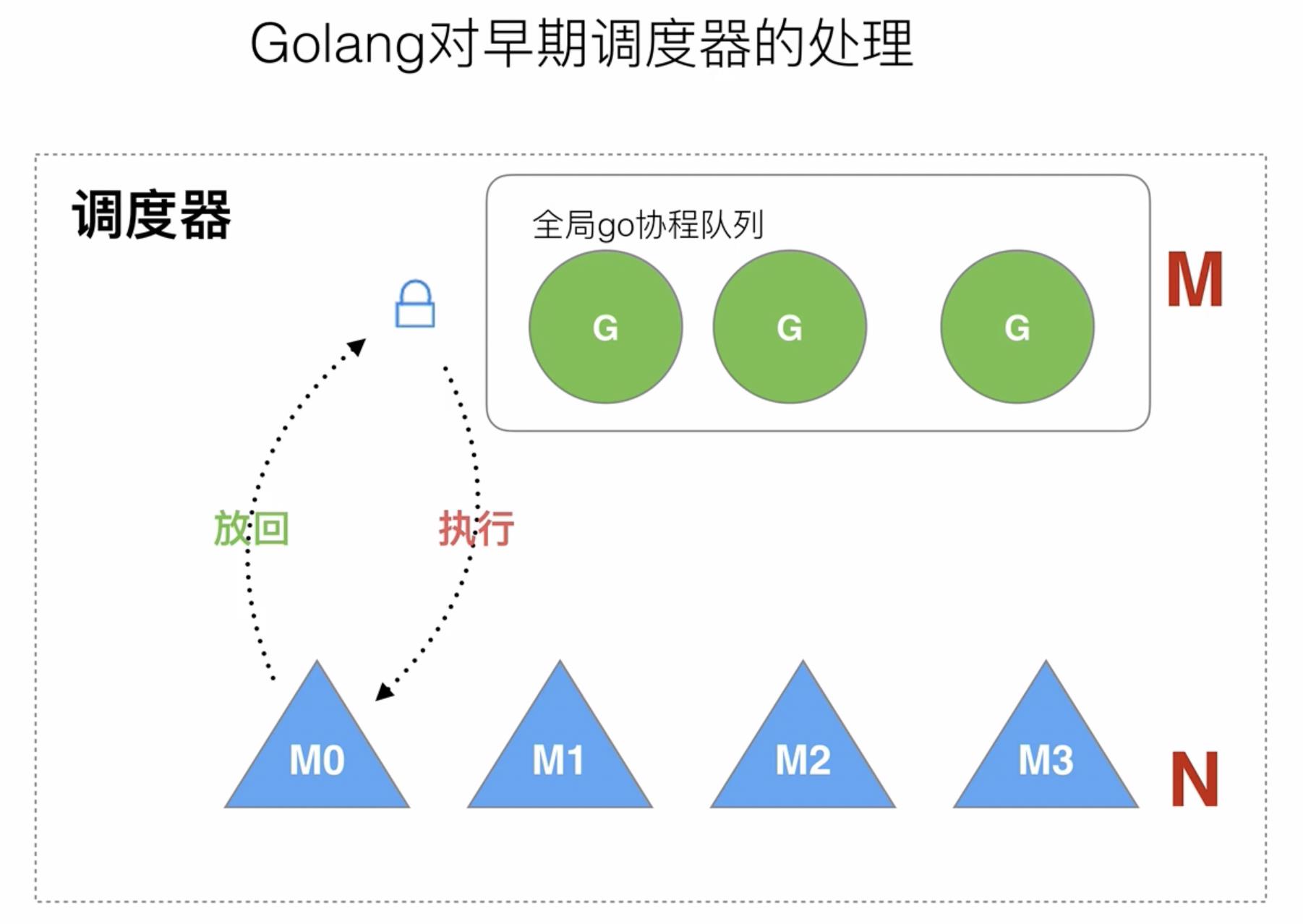
早期的调度器简单,但是存在很多的弊端:
- 创建、销毁、调度G都需要每个M获取锁,这就形成了激烈的锁竞争。
- M转移G会造成延迟和额外的系统负载。
- 系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
三、goroutine调度器的GMP模型
1. gmp模型简介

G指的是goroutine,协程,也就是上述一个线程分半后用户状态下的线程P指的是processor,用于处理执行goroutine,包含了每一个goroutine所需要的上下文环境。每个P维护了一个本地队列,存放当前P即将要执行的goroutine,此外还有一个全局队列,用于存放等待运行的goroutine。每个P的本地队列有数量限制,一般不超过256G,新建一个goroutine的时候,优先放到P的本地队列中,如果队列满了,才会尝试放到全局队列中。P的数量可以通过GOMAXPROCS()来设置,它代表了真正的并发度,即有多少个goroutine可以同时运行M指的是Machine,物理线程,也就是上述一个线程分半后内核状态下的线程
GMP模型的整个流程图如下所示,由全局队列、P的本地队列、P列表、M列表几个部分组成:
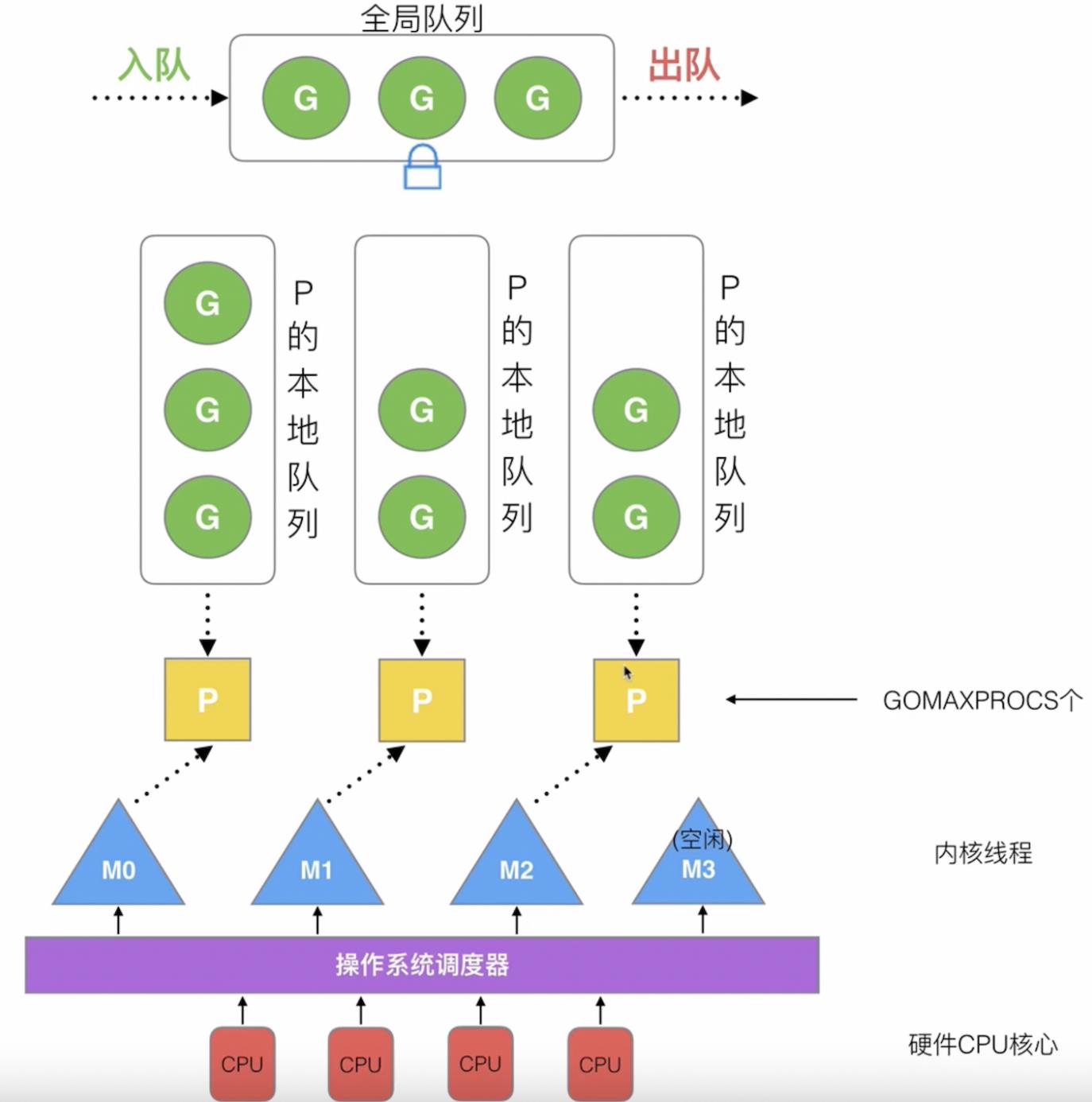
其中P列表是在程序启动时创建的,其数量最多有GOMAXPROCS个,有两种配置方式:
- 通过配置环境变量$GOMAXPROCS
- 在程序中通过runtime.GOMAXPROCS()方法来设置
M列表的数量表示当前操作系统分配给当前go程序的内核线程数,与P的数量无关,go语言本身限定了M的最大量为10000个,我们一般不对其数量进行设置,因为其数量是动态变化的,因为有一个M阻塞就会创建一个新的M,如果有M空闲,就会对其回收或者睡眠;如果需要对其数量进行设置,可以通过runtime/debug包下的SetMaxThreads函数进行设置
gmp模型的调度过程可以理解为,当一个任务需要执行时,首先由cpu调度分配一个线程M,然后M会获取该线程的P,P从本地队列/全局队列中取出一个G进行执行,也就是同一时间一个P只能执行一个G,因此一个程序当前所能执行最高的G的数量就是P的数量,也就是GOMAXPROCS个
2. gmp模型调度器设计策略
gmp模型对调度器的优化主要集中在以下几个策略:
- 复用线程
- 利用并行
- 抢占
- 全局G队列
1. 复用线程
为了避免频繁的创建、销毁线程,而是对线程进行复用,gmp模型调度器采用了两种机制work stealing 和 hand off
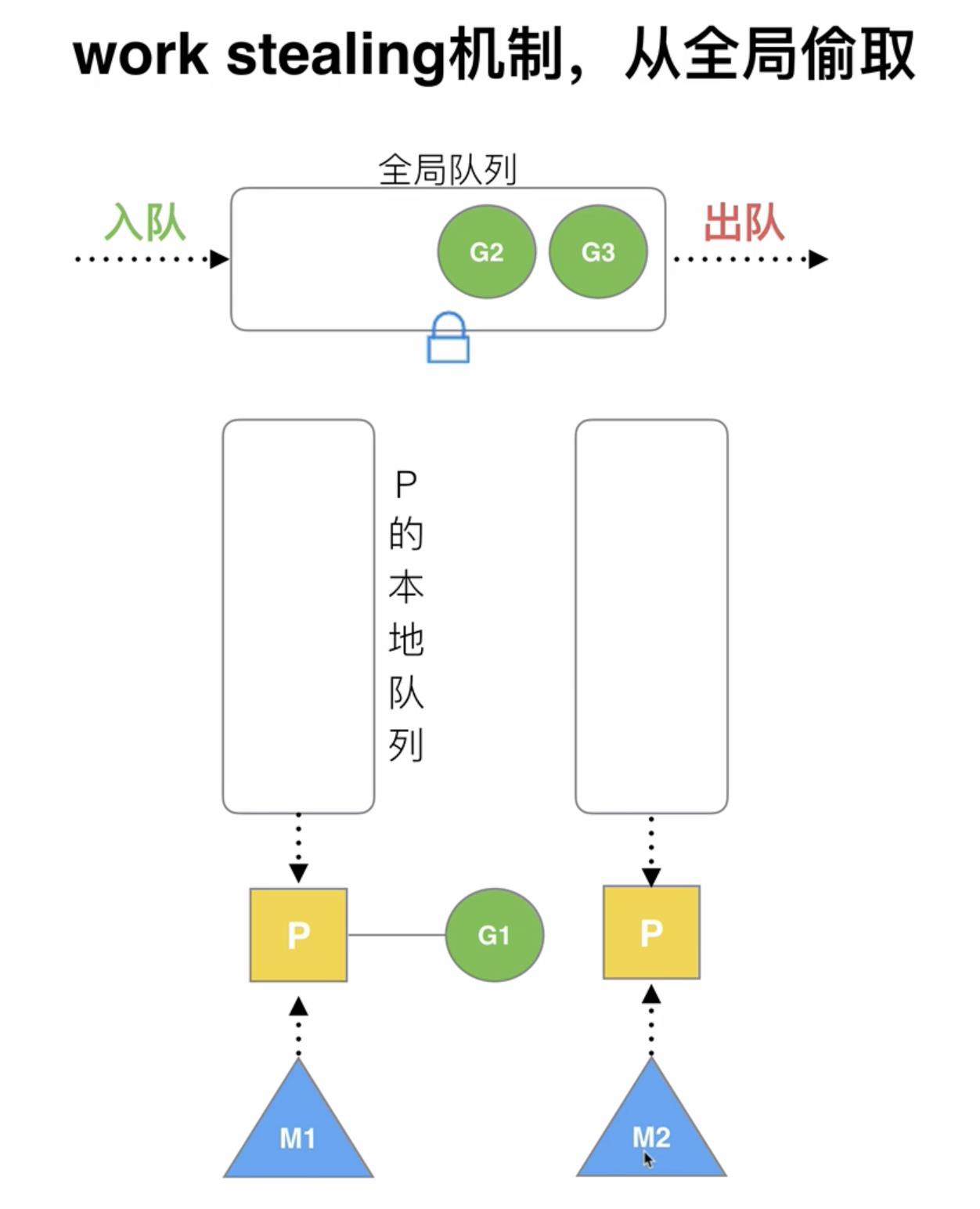
1️⃣ work stealing
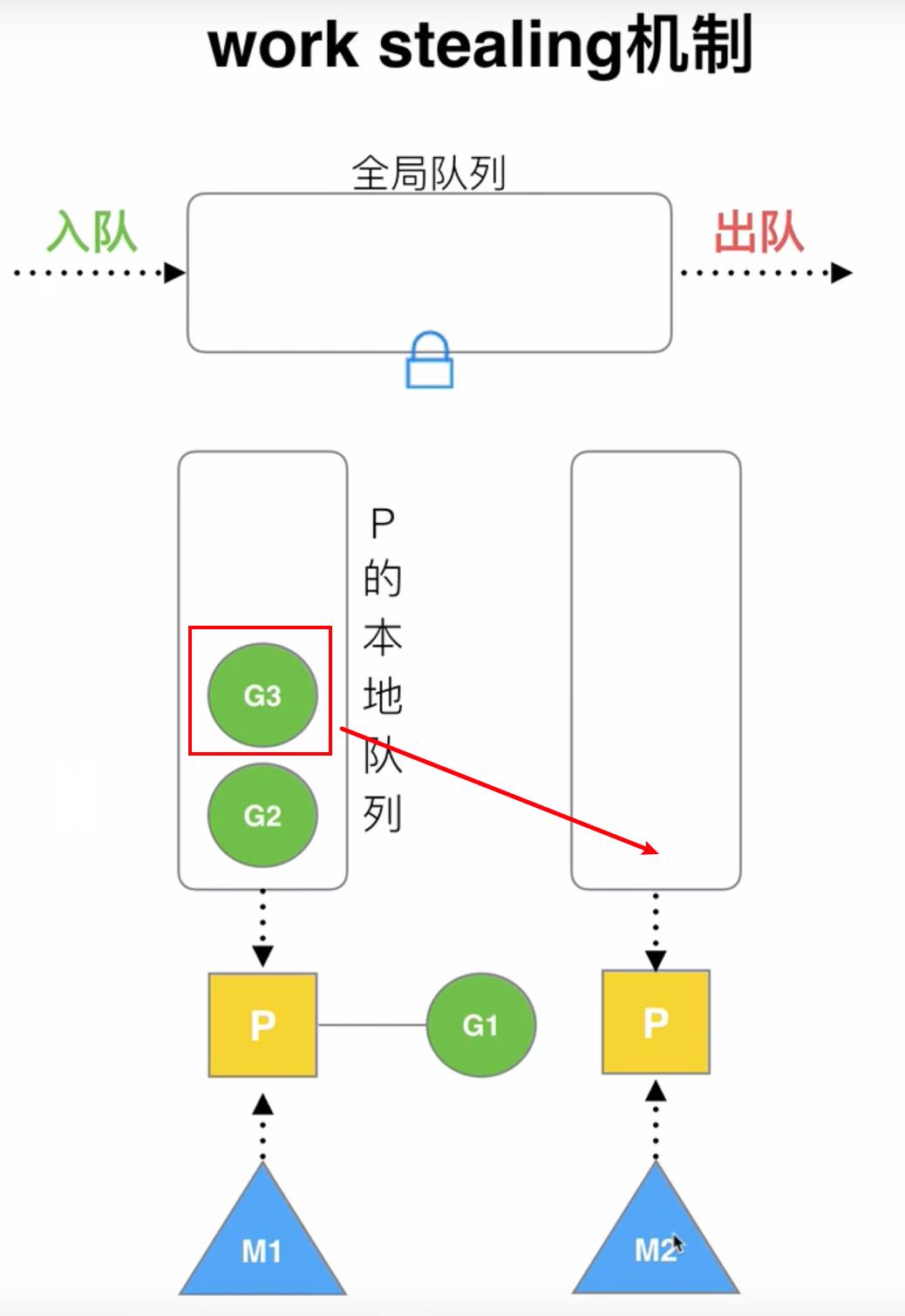
假设M1与P1绑定正在执行G1协程,当前P1的本地队列中还有G2、G3等待被执行,但此时M2对应的P2空闲,work stealing机制就是M2想要执行协程的话就从M1的P1的本地队列中偷取G进行执行
2️⃣ hand off
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xTaE4Wus-1632563686593)(https://gitee.com/zhong_siru/images/raw/master//img/202109251753330.png)]
此时假设M1的P1正在执行G1,M2的P2即将执行G3,但此时G1阻塞,hand off机制就是将M1与其P1分离开,此时cpu会创建一个新的线程,然后将P1迁移到新创建的线程M3中,cpu调度执行M2和M3,相当于M3接管了M1之前绑定P继续执行。此时原来的M1和G1处与阻塞状态,如果G1的阻塞操作执行完毕后,还需要执行的话就会加入到其他队列中,如果不需要执行则直接被销毁。
2. 利用并行
该策略就是利用GOMAXPROCS来限定P的个数,例如设置为 CPU核数/2,这样该程序跑起来最多用到一半的cpu,其他的cpu给其他程序使用
3. 抢占
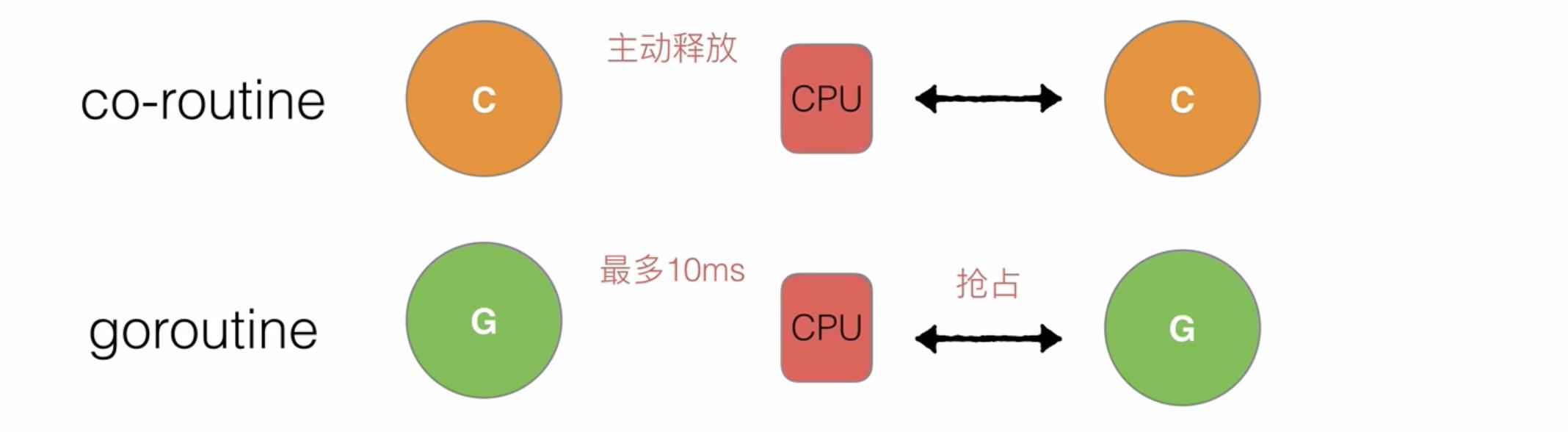
以前的co-routine绑定一个cpu的时候,如果此时来了其他的co-routine,只有当前co-routine结束主动释放时该cpu才会给其他co-routine进行绑定
而现在goroutine绑定一个cpu的时候,如果有其他的goroutine等待运行,则当前g最多执行10ms,10ms一到不管当前g是否主动释放,当前在等待的g一定会抢占cpu,这样保证了每个g都是平等的,防止饥饿现象
4. 全局g队列
如果一个P的本地队列里已经没有G待执行的话,会优先从其他P的本地队列里面偷,如果都没有的话才会从全局队列里面取,取出与放回的过程涉及全局队列的加锁与锁释放
以上是关于Go中的特殊协程g0的主要内容,如果未能解决你的问题,请参考以下文章