Eclipse远程提交MapReduce任务到Hadoop集群
Posted 莫西里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Eclipse远程提交MapReduce任务到Hadoop集群相关的知识,希望对你有一定的参考价值。
一、介绍
以前写完MapReduce任务以后总是打包上传到Hadoop集群,然后通过shell命令去启动任务,然后在各个节点上去查看Log日志文件,后来为了提高开发效率,需要找到通过Ecplise直接将MaprReduce任务直接提交到Hadoop集群中。该章节讲述用户如何从Eclipse的压缩包最终完成Eclipse提价任务给MapReduce集群。
二、详解
1、安装Eclipse,安装hadoop插件
(1)首先下载Eclipse的压缩包,然后可以从这里下载hadoop 2.7.1的ecplise插件和其他一些搭建环境中所需要的文件,然后解压ecplise,并放置到D盘中
(2)将下载的资源中的Hadoop-ecplise-plugin.jar 插件放到ecplise的插件目录中: D:\\ecplise\\plugins\\ 。然后开启ecplise。
(3)将Hadoop-2.7.1解压一份到D盘中,并配置相应的环境变量,并将%HADOOP_HOME%\\bin 文件加添加到Path环境中
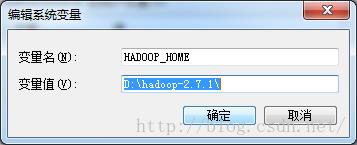
(4)然后选在ecplise中配置hadoop插件:
A、Window---->show view -----> other ,在其中选中MapReduce tool
B: Window---->Perspective------>Open Perspective -----> othrer
C : Window ----> Perferences ----> Hadoop Map/Reduce ,然后将刚刚解压的文件Hadoop文件选中
D、配置HDFS连接:该MapReduce view中创建一个新的MapReduce连接
当做完这些,我们就能在Package Exploer 中看到DFS,然后冲中可以看到HDFS上的文件:
2、进行MapReduce开发
(1)将hadoop-ecplise文件夹中的hadoopbin.zip进行解压,将会得到下列文件,并将这些文件放入到HADOOP_HOME\\bin目录下,然后将hadoop.dll文件放入到C:\\Window\\System32文件夹中
(2)从集群中下载: log4j.properties,core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml 这五个文件。然后写出一个WordCount的例子,然后将这五个文件放入到src文件夹下:

(3)修改mapred-site.xml和yarn-site.xml文件
A、mapred-site.xml上添加一下几个keyvalue键值:
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property><property>
<name>mapreduce.application.classpath</name>
<value>/home/hadoop/hadoop/hadoop-2.7.1/etc/hadoop,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/common/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/common/lib/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/hdfs/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/yarn/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/*</value>
</property><property>
<name>yarn.application.classpath</name>
<value>/home/hadoop/hadoop/hadoop-2.7.1/etc/hadoop,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/common/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/common/lib/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/hdfs/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/hdfs/lib/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/mapreduce/lib/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/yarn/*,
/home/hadoop/hadoop/hadoop-2.7.1/share/hadoop/yarn/lib/*</value>
</property>这里需要解释一下,在Hadoop2.6之前,因为其源代码中适配了Linux操作系统中的环境变脸表示符号$,而当在window下使用这些代码是,因为两个系统之间的变量符是不一样的,所以会导致以下的错误
org.apache.hadoop.util.Shell$ExitCodeException: /bin/bash: line 0: fg: no job control http://www.aboutyun.com/thread-8498-1-1.html
在这里我们通过修改mapreduce.application.classpath 和 yarn.application.classpath这两个参数,将其修改成绝对路径,这样就不会出现上述的错误。
(3)开始WordCount函数:
package wc;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.record.compiler.JBoolean;
public class WCMapReduce
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJobName("word count");
job.setJarByClass(WCMapReduce.class);
job.setJar("E:\\\\Ecplise\\\\WC.jar");
//配置任务map和reduce类
job.setMapperClass(WCMap.class);
job.setReducerClass(WCReduce.class);
//输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//文件格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出输入路径
FileInputFormat.addInputPath(job,new Path("hdfs://192.98.12.234:9000/Test/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.98.12.234:9000/result"));
//启动任务
job.waitForCompletion(true);
public static class WCMap extends Mapper<LongWritable, Text, Text, IntWritable>
private static Text outKey=new Text();
private static IntWritable outValue=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException
// TODO Auto-generated method stub
String words=value.toString();
StringTokenizer tokenizer=new StringTokenizer(words,"\\\\s");
while(tokenizer.hasMoreTokens())
String word=tokenizer.nextToken();
outKey.set(word);
context.write(outKey, outValue);
public static class WCReduce extends Reducer<Text, IntWritable, Text, IntWritable>
private static IntWritable outValue=new IntWritable();
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException
// TODO Auto-generated method stub
int sum=0;
for(IntWritable i:arg1)
sum+=i.get();
outValue.set(sum);
arg2.write(arg0,outValue);
需要注意的是,因为这里实现的是远程提交方法,所以在远程提交时需要将任务的jar包发送到集群中,但是ecplise中并没有自带这种框架,因此需要先将jar打好在相应的文件中,然后在程序中,通过下行代码指定jar的位置。
job.setJar("E:\\\\Ecplise\\\\WC.jar");(4)配置提交任务的用户环境变量:
如果windows上的用户名称和linux上启动集群的用户名称不相同时,则需要添加一个环境变量来实现任务的提交:

(5)运行结果
16/03/30 21:09:14 INFO client.RMProxy: Connecting to ResourceManager at hadoop1/192.98.12.234:8032
16/03/30 21:09:14 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/03/30 21:09:14 INFO input.FileInputFormat: Total input paths to process : 1
16/03/30 21:09:14 INFO mapreduce.JobSubmitter: number of splits:1
16/03/30 21:09:15 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1459331173846_0031
16/03/30 21:09:15 INFO impl.YarnClientImpl: Submitted application application_1459331173846_0031
16/03/30 21:09:15 INFO mapreduce.Job: The url to track the job: http://hadoop1:8088/proxy/application_1459331173846_0031/
16/03/30 21:09:15 INFO mapreduce.Job: Running job: job_1459331173846_0031
16/03/30 21:09:19 INFO mapreduce.Job: Job job_1459331173846_0031 running in uber mode : false
16/03/30 21:09:19 INFO mapreduce.Job: map 0% reduce 0%
16/03/30 21:09:24 INFO mapreduce.Job: map 100% reduce 0%
16/03/30 21:09:28 INFO mapreduce.Job: map 100% reduce 100%
16/03/30 21:09:29 INFO mapreduce.Job: Job job_1459331173846_0031 completed successfully
16/03/30 21:09:29 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=19942
FILE: Number of bytes written=274843
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=15533
HDFS: Number of bytes written=15671
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=9860
Total time spent by all reduces in occupied slots (ms)=2053
Total time spent by all map tasks (ms)=2465
Total time spent by all reduce tasks (ms)=2053
Total vcore-seconds taken by all map tasks=2465
Total vcore-seconds taken by all reduce tasks=2053
Total megabyte-seconds taken by all map tasks=10096640
Total megabyte-seconds taken by all reduce tasks=2102272
Map-Reduce Framework
Map input records=289
Map output records=766
Map output bytes=18404
Map output materialized bytes=19942
Input split bytes=104
Combine input records=0
Combine output records=0
Reduce input groups=645
Reduce shuffle bytes=19942
Reduce input records=766
Reduce output records=645
Spilled Records=1532
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=33
CPU time spent (ms)=1070
Physical memory (bytes) snapshot=457682944
Virtual memory (bytes) snapshot=8013651968
Total committed heap usage (bytes)=368050176
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=15429
File Output Format Counters
Bytes Written=15671因为MapReduce任务在src文件下配置那5个文件时,会在本地种启动任务。当任务在本地执行的,任务的名称中就会出现local,而上述的任务名称中并没有出现local,因此成功将任务提交到了Linux 集群中
以上是关于Eclipse远程提交MapReduce任务到Hadoop集群的主要内容,如果未能解决你的问题,请参考以下文章