YouTube-8M 数据集简介
Posted chenxp2311
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YouTube-8M 数据集简介相关的知识,希望对你有一定的参考价值。
Preface
Google 公布了一个大型的视频数据集:YouTube-8M 视频数据集(项目主页地址),这个数据集的 Technical Report 在 arXiv 上也挂出来了:YouTube-8M: A Large-Scale Video Classification Benchmark。
本文是对 Google 对这个数据集介绍的博文:Announcing YouTube-8M: A Large and Diverse Labeled Video Dataset for Video Understanding Research 的一个总结归纳,
Introduction
这个数据集包含 8,000,000 万个 YouTube 视频链接,这些视频集进行了 video-level(视频层级) 的标注,标注为 4800 种 Knowledge Graph entities(知识图谱实体)。
这次公布的 YouTube-8M 数据集相比较于之前公布的数据集:YouTube-1M,又是一次的大提升。之前的 YouTube-1M 是包含 500 种体育项目的 YouTube 视频数据集,包含 1,000,000 个视频链接。
Characteristic
这个的数据集的特点如下:

8 Million video URLs
为了保证数据集的质量,在选取视频时,做了一些限制:
- 每一个视频都是公开的,且每个视频至少有 1000 帧
- 每一个视频的长度在 120s 到 500s 之间
- 每一个视频至少与一个 Knowledge Graph entities(知识图谱实体)相联系
- 成人视频由自动分类器移除
0.5 Million Hours of video
数据集中视频超过了 5000 个小时,一般需要 1PB( 1PB=1024TB ) 的硬盘来存储,同时一般也需要 50 CPU-years 来处理这个视频。
所以为了减小存储开销与计算时间开销,Google 提供了 pre-computed and compressed features,这样的话就可以在单台机子上一天内完成模型的训练。
1.9 Billion Frame Features
同时,已经用在 ImageNet 上训练得到的 Inception-V3 image annotation model 提取了这些视频的 frame-level、video-level 特征。
这些特征是从 1.9 Billion 视频帧中,以每秒 1 帧的时间分辨率进行提取的。之后进行了 PCA 降维处理,是最后的特征能够存储在一张硬盘中(小于 1.5T)。
4800 Classes
这些视频被标注的 annotation vocabulary 包含 4800 个 Knowledge Graph entities(知识图谱实体)。
每一个 entity 至少有 120 个训练视频,平均每个 entity 有 2229 个训练视频。annotation 的定义方式参照 YouTube Data API。
其中最多的一个 entity 是 Vehicle,超过了 500K 个训练视频;拥有最少视频的 entity 是 Somersault,只有 120 个视频。
4800 个 entity 被分为 24 种 frequent,最高 frequent 的是 Arts & Entertainment,超过 2,800,000 个训练视频。最少 frequent 是 Finance,小于 14,000 个训练视频。
这里,所谓的 24 top-level verticals,详情可以参考 Youtube-8M 主页中的这个 Explore 页面:dataset browser,如下图:
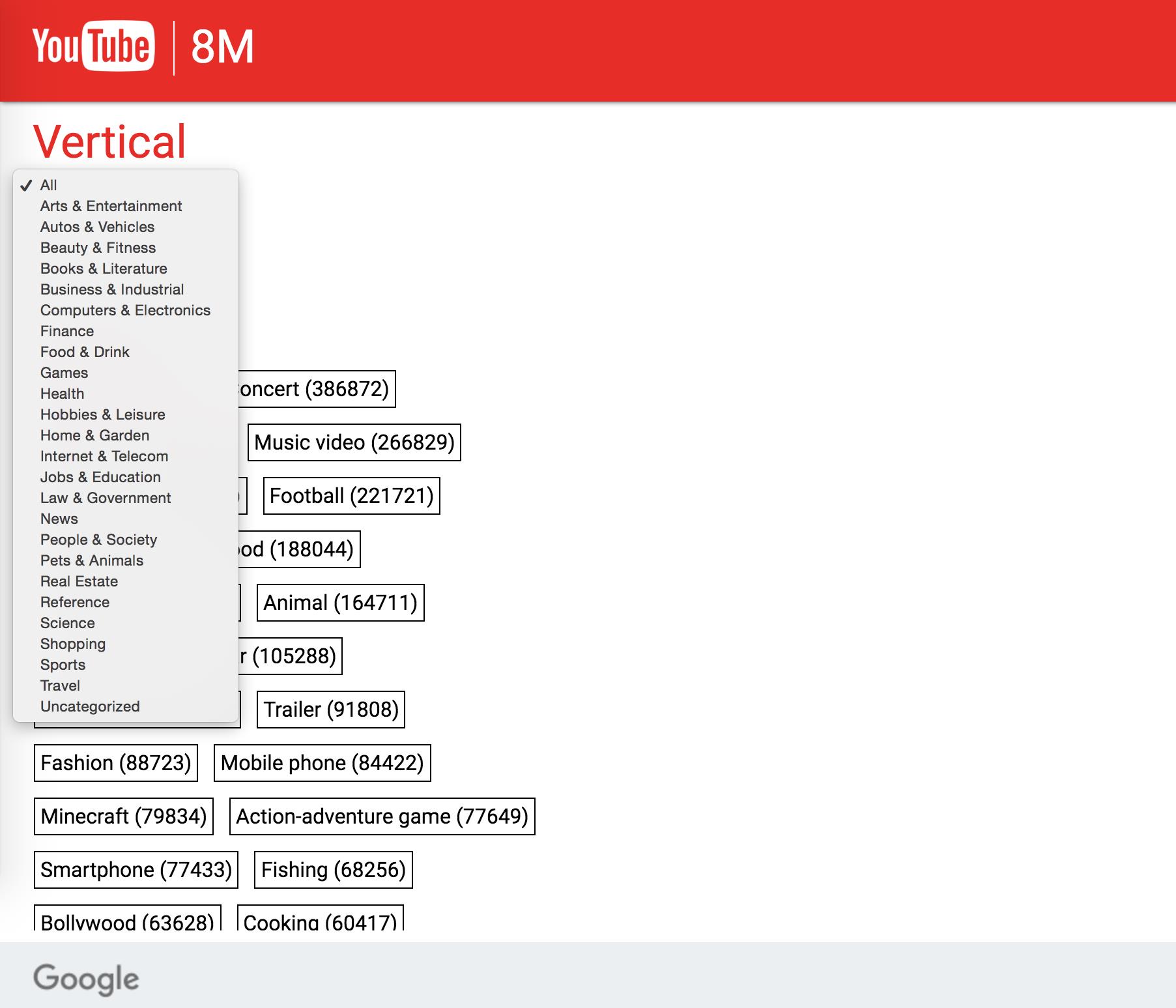
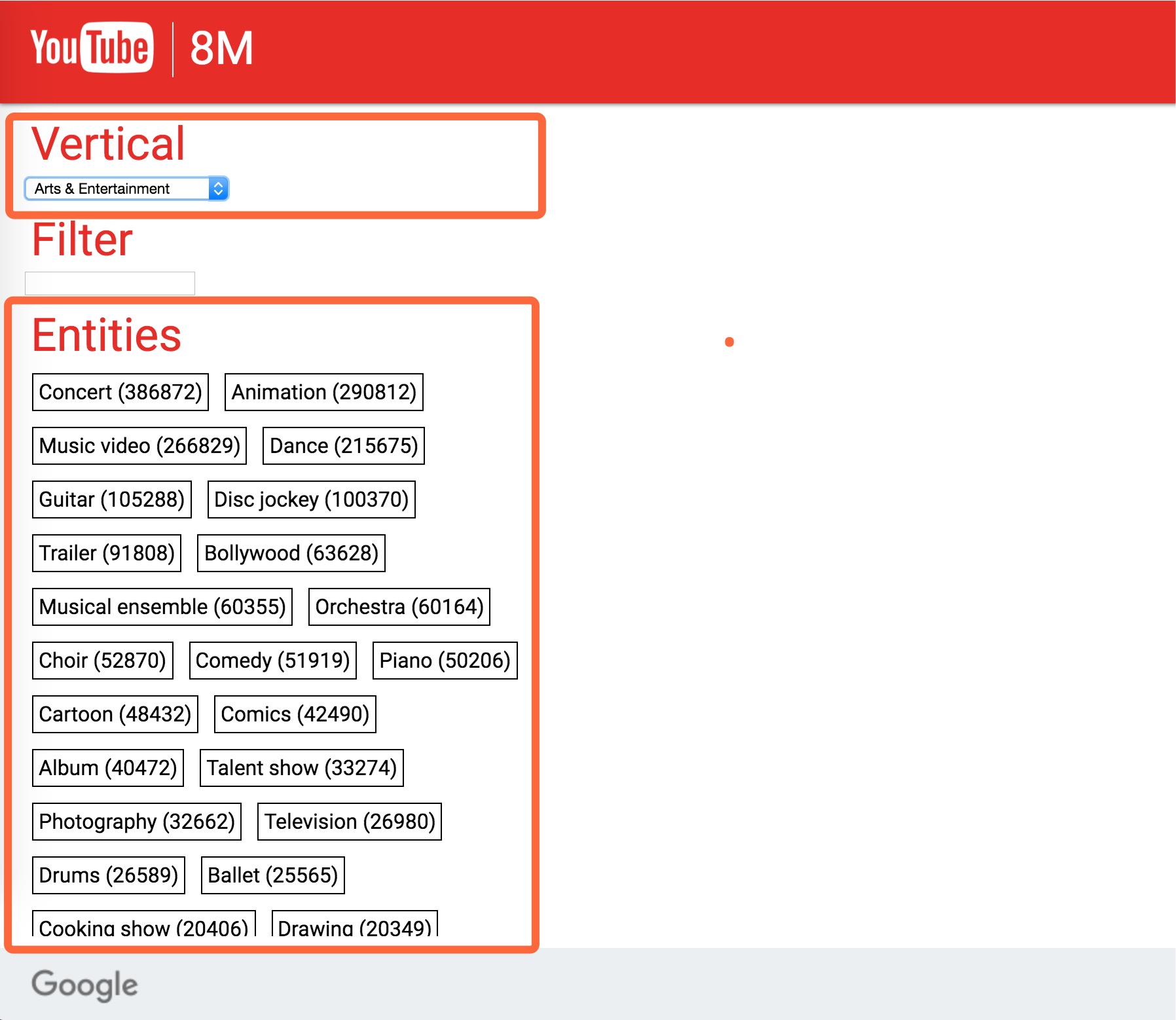
具体的,如 Arts & Entertainment 这类,其 Entity 如下:
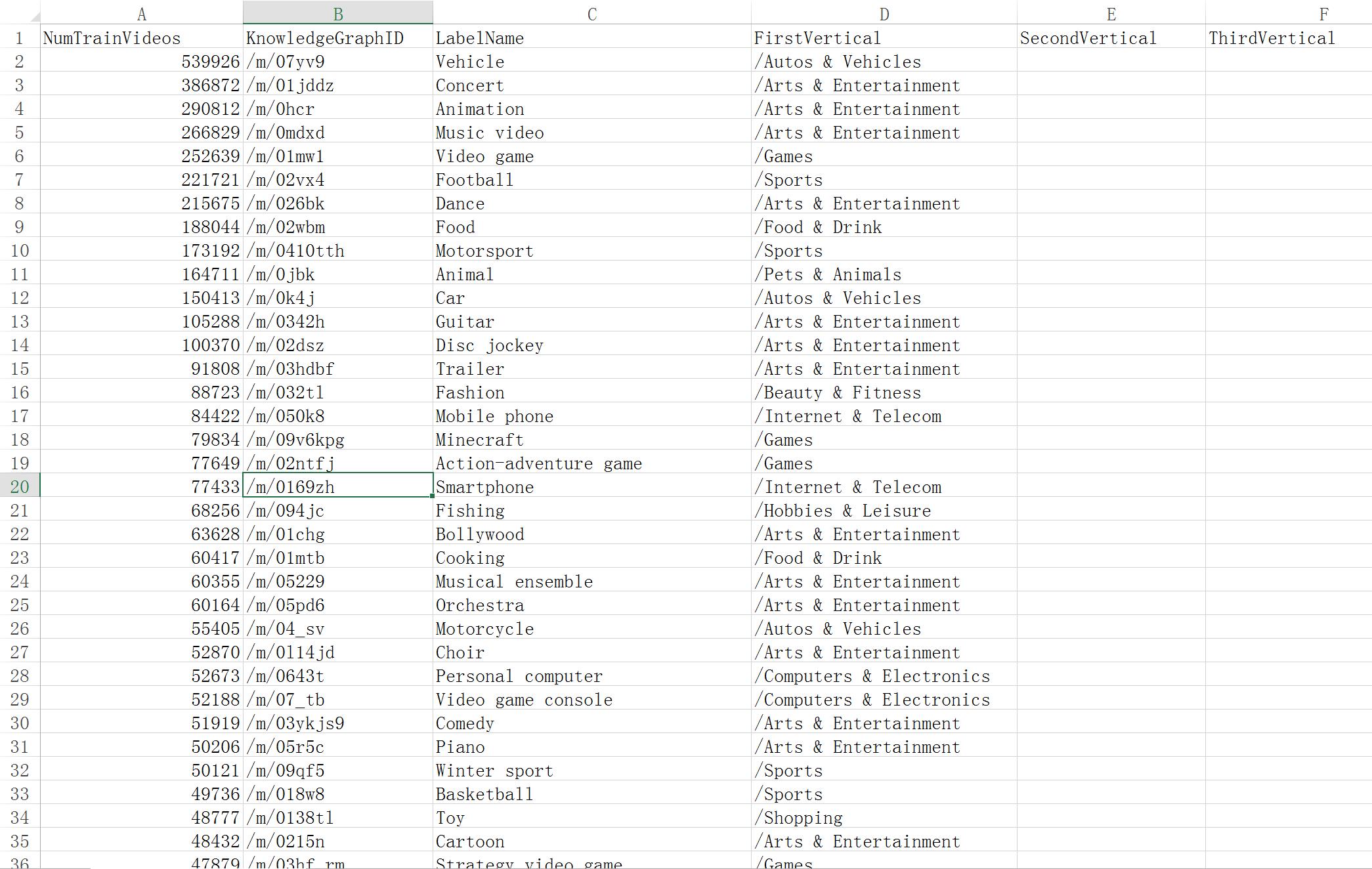
另外,关于数据集的具体的 labels,其归属的 Vertical,对应的 KnowledgeGraphID,可以参加这个 CSV 文件:train-labels-histogram:
1.8 Avg.Labels/Video
每个视频平均有 1.8 个 labels,这些 ground truth labels 来自于 Youtube data API,根据视频的 content、metadata、contextual、user signals 对每个视频进行 annotation。
每个视频的 label 个数从 1 到 39,平均每个视频有 1.8 个 labels。大约有 60% 到 80% 的视频,其 labels 个数在 2~3 个。
Postscripts
上面只是我对这个数据集的一点翻译式的记录描述,使用时具体的详情,请参见 Google 对这份 YouTube-8M 的 Technical Report: YouTube-8M: A Large-Scale Video Classification Benchmark

以上是关于YouTube-8M 数据集简介的主要内容,如果未能解决你的问题,请参考以下文章