SIMD加速计算矩阵(组成原理实验5)
Posted horizon08
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SIMD加速计算矩阵(组成原理实验5)相关的知识,希望对你有一定的参考价值。
介绍
实验5的文档内容:https://shimo.im/docs/4iV7Rw1nxLgeMsBe/
以下仅实现了第一部分的SIMD的功能。
- a) 介绍
并行化是计算机硬件的大趋势。然而,程序员不做任何修改,只依赖于计算机体系结构专家、编译器设计者和芯片工程师的工作就能让程序跑得更快,这样的日子已经一去不复返了。因此,如果想要让程序跑得更快,软件设计人员应该掌握并行编程的基本思想。
在这部分实验中,你需要利用SIMD内蕴函数编写并行代码解决问题。 - b) 熟悉实验代码
你将拿到两个源文件 randomized.cpp 和 common.h, 你可以在你熟悉的开发平台上编译randomized.cpp,并观察运行效果。你需要优化的函数sum()放在common.h头文件中,这段代码完成的核心功能是对一个整型数组进行有条件求和,并对程序运行时间进行计时。由于核心函数的SIMD版本还未实现,你应该能够看到两个版本之间的运行结果是不一致的。 - c) 使用SIMD内蕴函数对求和函数进行优化
在common.h头文件中找到函数sum_simd(), 你需要根据以下代码进行相应的优化:
(注意:你仅仅需要对内层的循环体进行优化。)
在优化的过程中,你可能会用到以下内蕴函数:
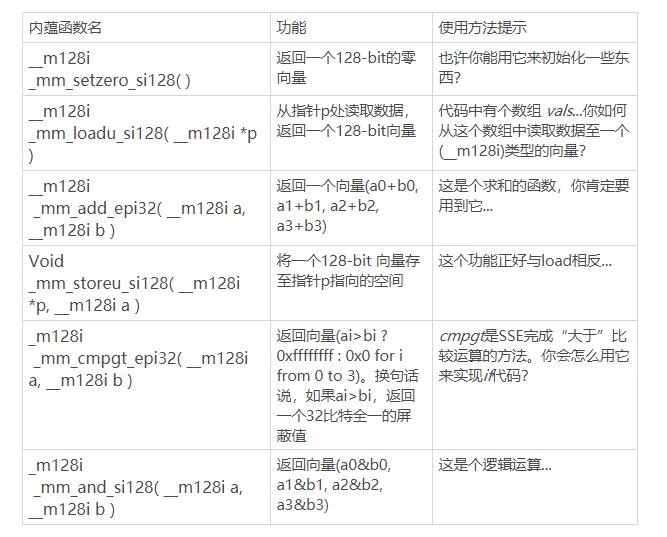
-
d) 一些有益的提示
- i. __m128i是Intel用于声明128-bit向量的数据类型,我们会用一个__m128i类型的变量存放四个32-bit的整形数;
- ii. 代码中提供了一个叫做_127的变量,它当中包含了数字127的四份拷贝,你可以把它用在比较上;
- iii. 在你完成内层循环体的计算之前,不要使用保存函数(_mm_storeu_si128)。这个函数的计算代价很高,如果你在每一次循环结束时都使用它,你会发现你的代码的性能不够好;
- iv. 在访问__m128i类型的向量时,不推荐你直接地访问它当中的每一个元素,更好的方法是把__m128i类型的向量用storeu的方法存放到一个普通的数组当中,然后单独访问这个数组当中的元素;
- e) 实验结果与实验报告
当你完成代码之后,你应该能够观察到以下效果:
-
i. SIMD版本的代码与未优化的代码的计算结果保持一致;
-
ii. SIMD版本的代码应该要比未优化的代码快(快多少,记录下性能加速比,并且分析为什么你认为它是正确的结果)
在你的实验报告中提供你的代码、运行结果和你的思考过程,并上传一个简短的带解说的演示视频(只给出代码截图和实验结果,但却不提供分析过程的不给分。)
-
实验给出的源代码
common.h:
#ifndef COMMON_H
#define COMMON_H
#include <x86intrin.h>
#define NUM_ELEMS ((1 << 15) + 10)
#define OUTER_ITERATIONS (1 << 15)
/* 不要修改这个函数 */
long long int sum(unsigned int vals[NUM_ELEMS])
clock_t start = clock();
long long int sum = 0;
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++)
for(unsigned int i = 0; i < NUM_ELEMS; i++)
if(vals[i] >= 128)
sum += vals[i];
clock_t end = clock();
printf("Time taken: %f s\\n", (double)(end - start) / CLOCKS_PER_SEC);
return sum;
/* 不要修改这个函数 */
long long int sum_unrolled(unsigned int vals[NUM_ELEMS])
clock_t start = clock();
long long int sum = 0;
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++)
for(unsigned int i = 0; i < NUM_ELEMS / 4 * 4; i += 4)
if(vals[i] >= 128) sum += vals[i];
if(vals[i + 1] >= 128) sum += vals[i + 1];
if(vals[i + 2] >= 128) sum += vals[i + 2];
if(vals[i + 3] >= 128) sum += vals[i + 3];
//This is what we call the TAIL CASE
//For when NUM_ELEMS isn't a multiple of 4
//NONTRIVIAL FACT: NUM_ELEMS / 4 * 4 is the largest multiple of 4 less than NUM_ELEMS
for(unsigned int i = NUM_ELEMS / 4 * 4; i < NUM_ELEMS; i++)
if (vals[i] >= 128)
sum += vals[i];
clock_t end = clock();
printf("Time taken: %f s\\n", (double)(end - start) / CLOCKS_PER_SEC);
return sum;
long long int sum_simd(unsigned int vals[NUM_ELEMS])
clock_t start = clock();
//这句代码会为你生成一个含有若干个127的向量
//思考题:为什么你需要它?
__m128i _127 = _mm_set1_epi32(127);
long long int result = 0;// 将最终计算的结果保存在这里
//不要修改此行之上的任何代码!!!
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++)
/* 你的代码从这里开始 */
/* 你的代码在这里结束 */
clock_t end = clock();
printf("Time taken: %f s\\n", (double)(end - start) / CLOCKS_PER_SEC);
return result;
/* 不要修改这个函数 */
int int_comparator(const void* a, const void* b)
if(*(unsigned int*)a == *(unsigned int*)b) return 0;
else if(*(unsigned int*)a < *(unsigned int*)b) return -1;
else return 1;
#endif
- 源代码
randomized.cpp
#include <time.h>
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
/* ***不要修改这个文件!只能修改common.h的内容!*** */
int main(int argc, char* argv[])
printf("Let's generate a randomized array.\\n");
unsigned int vals[NUM_ELEMS];
long long int reference;
long long int simd;
long long int simdu;
for(unsigned int i = 0; i < NUM_ELEMS; i++) vals[i] = rand() % 256;
printf("Starting randomized sum.\\n");
printf("Sum: %lld\\n", reference = sum(vals));
printf("Starting randomized unrolled sum.\\n");
printf("Sum: %lld\\n", sum_unrolled(vals));
printf("Starting randomized SIMD sum.\\n");
printf("Sum: %lld\\n", simd = sum_simd(vals));
if (simd != reference)
printf("OH NO! SIMD sum %lld doesn't match reference sum %lld!\\n", simd, reference);
题目要求只修改common.h
我实现的代码,如下:
#ifndef COMMON_H
#define COMMON_H
#include <x86intrin.h>
#include <stdint.h>
#define NUM_ELEMS ((1 << 15) + 10)
#define OUTER_ITERATIONS (1 << 15)
/* 不要修改这个函数 */
long long int sum(unsigned int vals[NUM_ELEMS])
clock_t start = clock();
long long int sum = 0;
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++)
for(unsigned int i = 0; i < NUM_ELEMS; i++)
if(vals[i] >= 128)
sum += vals[i];
clock_t end = clock();
printf("Time taken: %f s\\n", (double)(end - start) / CLOCKS_PER_SEC);
return sum;
/* 不要修改这个函数 */
long long int sum_unrolled(unsigned int vals[NUM_ELEMS])
clock_t start = clock();
long long int sum = 0;
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++)
for(unsigned int i = 0; i < NUM_ELEMS / 4 * 4; i += 4)
if(vals[i] >= 128) sum += vals[i];
if(vals[i + 1] >= 128) sum += vals[i + 1];
if(vals[i + 2] >= 128) sum += vals[i + 2];
if(vals[i + 3] >= 128) sum += vals[i + 3];
//This is what we call the TAIL CASE
//For when NUM_ELEMS isn't a multiple of 4
//NONTRIVIAL FACT: NUM_ELEMS / 4 * 4 is the
// largest multiple of 4 less than NUM_ELEMS
for(unsigned int i = NUM_ELEMS / 4 * 4; i < NUM_ELEMS; i++)
if (vals[i] >= 128)
sum += vals[i];
clock_t end = clock();
printf("Time taken: %f s\\n", (double)(end - start) / CLOCKS_PER_SEC);
return sum;
long long int sum_simd(unsigned int vals[NUM_ELEMS])
clock_t start = clock();
//这句代码会为你生成一个含有若干个127的向量
//思考题:为什么你需要它?
//用来实现比较对应的128, (>127) == (>=128)
__m128i _127 = _mm_set1_epi32(127);
//用来比较数字是否>=128
long long int result = 0;// 将最终计算的结果保存在这里
//不要修改此行之上的任何代码!!!
__m128i p = _mm_setzero_si128( );//用来保存从数组中读取的数据
for(unsigned int w = 0; w < OUTER_ITERATIONS; w++)
/* 你的代码从这里开始 */
__m128i sum = _mm_setzero_si128( );//需要sum的值
for(unsigned int i = 0; i < NUM_ELEMS / 4 * 4; i += 4)
__m128i* h = (__m128i*)(vals+i);//地址强制类型转换
p = _mm_loadu_si128( h );//从指针中获取值,获取128位,即4Byte,恰好是vals[0-3]
__m128i flag = _mm_setzero_si128( );
flag = _mm_cmpgt_epi32( p , _127 ); //大于127时应该是oxfffff,
//一下子比较四个向量, 4Byte的每一bits都是应该是十进制的-1,而但小于时则会出现ox0000,
//所以就是0, 在flag中的四个部分中分别比较后的结果会变成四个部分保存,
//所以只存在-1和0的结果.如果都大于,(-1,-1,-1,-1).
//这样子的话,-1时是每一bis都是1, 那么我们取大于的时候,
//直接用flag和我们的p来做and与计算, 那么如果大于,直接保留不变,
//小于的话是0,与完后变成0,相当于跳过计算,不影响我们的计算结果.
__m128i hi = _mm_setzero_si128( );
hi = _mm_and_si128( p, flag );
sum = _mm_add_epi32(sum, hi);
//int 一般为32位, 4*32 = 128
int32_t *k = (int *)∑//将_m128i转换为4个int型的数组 (
result = result + k[0] + k[1] + k[2] + k[3];//将其全部加入result
for(unsigned int i = NUM_ELEMS / 4 * 4; i < NUM_ELEMS; i++)
if (vals[i] >= 128)
result += vals[i];
//result *= OUTER_ITERATIONS;
/* 你的代码在这里结束 */
clock_t end = clock();
printf("Time taken: %f s\\n", (double)(end - start) / CLOCKS_PER_SEC);
return result;
/* 不要修改这个函数 */
int int_comparator(const void* a, const void* b)
if(*(unsigned int*)a == *(unsigned int*)b) return 0;
else if(*(unsigned int*)a < *(unsigned int*)b) return -1;
else return 1;
#endif
运行结果
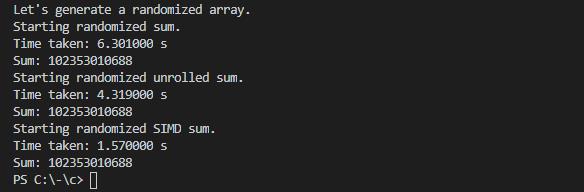
Nice

以上是关于SIMD加速计算矩阵(组成原理实验5)的主要内容,如果未能解决你的问题,请参考以下文章