机器学习总结四:逻辑回归与反欺诈检测案例
Posted 想考个研
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习总结四:逻辑回归与反欺诈检测案例相关的知识,希望对你有一定的参考价值。
机器学习算法总结
一、Bagging之决策树、随机森林原理与案例
二、boosting之GBDT、XGBT原理推导与案例
三、SVM原理推导与案例
四、逻辑回归与反欺诈检测案例
五、聚类之K-means
四、逻辑回归
1、概述
-
由线性回归变化而来的,应用于分类问题中的广义回归算法。
-
组成:
- 回归函数
z = w 1 x 1 + w 2 x 2 + . . . + w n x n + b = [ w 1 w 2 w n b ] ∗ [ x 1 x 2 ⋮ x n 1 ] = w T X z= w_1x_1+w_2x_2+...+w_nx_n+b=\\beginbmatrix w_1\\quad w_2 \\quad w_n \\quad b \\endbmatrix*\\beginbmatrix x_1\\\\x_2\\\\\\vdots\\\\x_n\\\\1 \\endbmatrix=w^TX z=w1x1+w2x2+...+wnxn+b=[w1w2wnb]∗⎣⎢⎢⎢⎢⎢⎡x1x2⋮xn1⎦⎥⎥⎥⎥⎥⎤=wTX
- 回归函数
- 激活函数/sigmoid函数
g ( z ) = 1 1 + e − z g(z)=\\frac11+e^-z\\\\ g(z)=1+e−z1
δ ′ g ( z ) δ z = − ( 1 + e − z ) − 2 ∗ e − z ∗ − 1 = e − z ( 1 + e − z ) 2 = 1 1 + e − z ∗ 1 + e − z − 1 1 + e − z = s i g m o i d ∗ ( 1 − s i g m o i d ) \\beginarrayl \\frac\\delta'g(z)\\delta z&=-(1+e^-z)^-2*e^-z*-1=\\frace^-z(1+e^-z)^2=\\frac11+e^-z*\\frac1+e^-z-11+e^-z\\\\ &=sigmoid*(1-sigmoid) \\endarray δzδ′g(z)=−(1+e−z)−2∗e−z∗−1=(1+e−z)2e−z=1+e−z1∗1+e−z1+e−z−1=sigmoid∗(1−sigmoid)
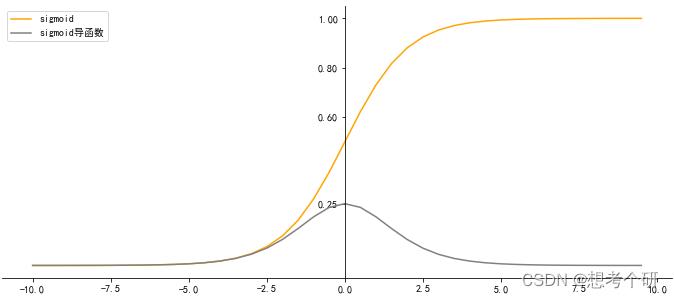
-
机率/统计学几率:事件发生的概率与该事件不发生的概率的比值
-
对数几率:分类为1的概率/分类不为1的概率的比值再取对数
l n ( g ( z ) 1 − g ( z ) ) = l n ( 1 1 + e − z 1 − 1 1 + e − z ) = l n ( e z ) = z ln(\\fracg(z)1-g(z))=ln(\\frac\\frac11+e^-z1-\\frac11+e^-z)=ln(e^z)=z ln(1−g(z)g(z))=ln(1−1+e−z11+e−z1)=ln(ez)=z
可以看出:逻辑回归中线性回归部分预测结果是在求预测为1的几率(取对数)
2、原理
2.1、损失函数
衡量参数w优劣的评估指标,用来求解最优参数的工具。
注:没有“求解参数”需求的模型没有损失函数,比如决策树、knn、随机森林
J
(
w
)
=
−
∑
i
=
1
n
[
y
i
l
o
g
2
g
(
x
i
)
+
(
1
−
y
i
)
l
o
g
2
(
1
−
g
(
x
i
)
)
]
n
:
样
本
数
量
;
x
i
,
y
i
:
样
本
特
征
和
真
实
标
签
J(w)=-\\sum_i=1^n[y_ilog_2g(x_i)+(1-y_i)log_2(1-g(x_i))] \\\\ n:样本数量;x_i,y_i:样本特征和真实标签
J(w)=−i=1∑n[yilog2g(xi)+(1−yi)log2(1−g(xi))]n:样本数量;xi,yi:样本特征和真实标签
2.2、损失函数推导方式1
对
于
二
分
类
为
例
:
设
p
=
g
(
y
i
^
=
1
∣
x
i
,
以上是关于机器学习总结四:逻辑回归与反欺诈检测案例的主要内容,如果未能解决你的问题,请参考以下文章