记一次大数据跨区域流量排查及修复
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次大数据跨区域流量排查及修复相关的知识,希望对你有一定的参考价值。
最近公司在降成本,发现了欧州、美国区两个区每天存在
300$的跨区流量费用,经过运维同学定位后发现绝大部分流量在emr机器上。于是排查就开始了。
前言
首先附上我们的任务调度架构
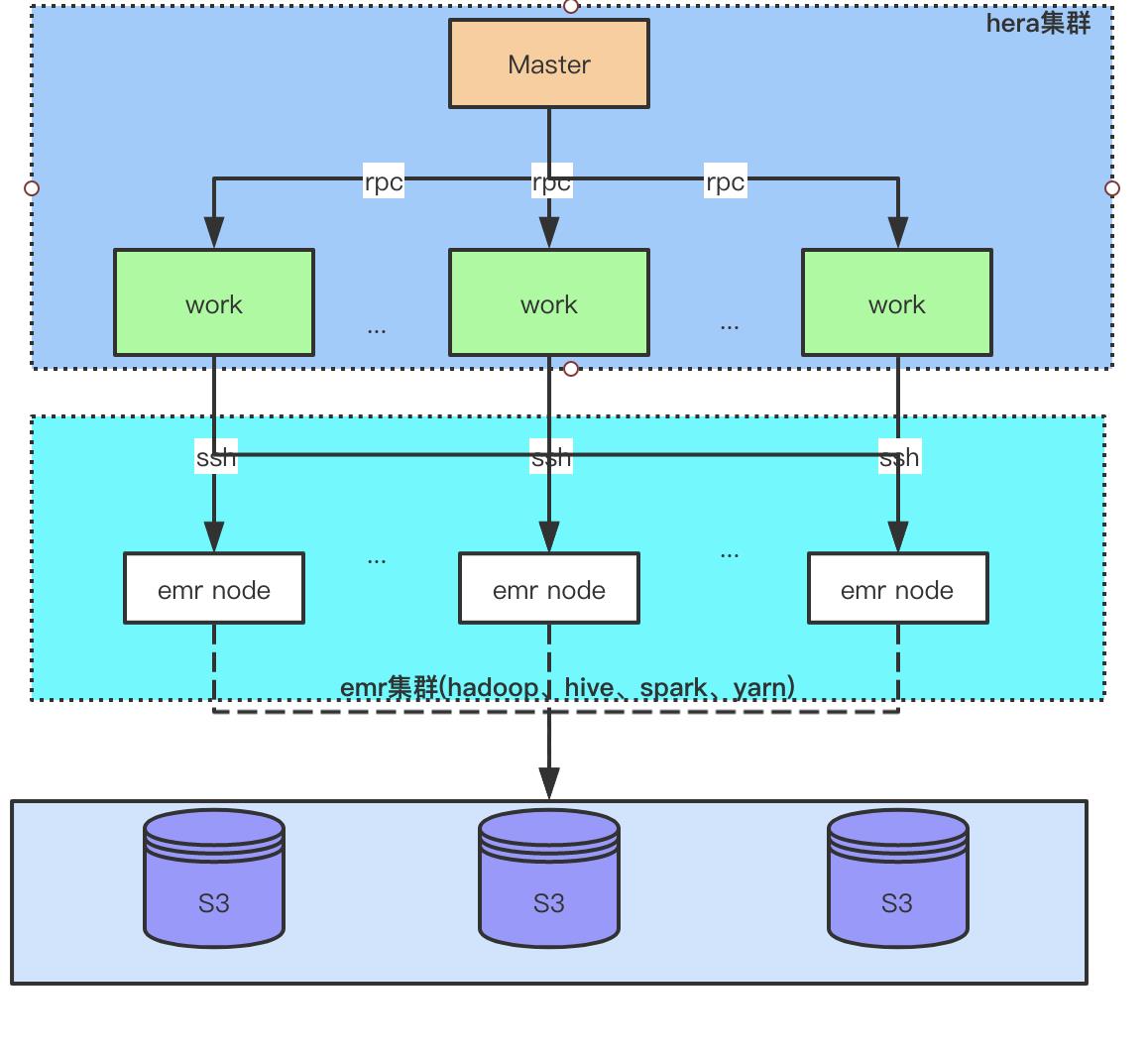
- 我们大数据计算使用的是
AWS的EMR(Elastic MapReduce)集群,由于AWS EMR天然支持读写S3,并且S3相比较硬盘尤其便宜,所以我们的离线数据都是存储在S3。即:计算与存储分离的架构。 - 任务调度与开发平台使用的是赫拉任务调度,关于为什么选择这款开源调度系统是因为:为了节省费用我们的离线EMR集群只是在任务执行时创建使用,任务执行结束后自动销毁,刚好赫拉任务调度支持动态
EMR的创建并且支持弹性伸缩配置,还可以使用SSH和直接在hadoop机器上两种方式提交任务。
下面介绍下,为何我们产生了跨区域的外网流量。通过前言的叙述,大家都知道了我们是计算存储分离的架构,我们美国区、欧洲区都是一样的。本来是美国区的任务提交在美国区的 AWS EMR 集群,存储在美国区的S3 bucket,欧洲区的任务提交在欧洲区的 AWS EMR 集群,存储在欧洲区的S3 bucket。但是由于已离职的某位同事为别人建库时,美国库的 location 建在了欧洲的S3 bucket,也就导致了美国的 EMR 集群计算时读、写使用的数据都来自于欧洲的 S3.跨区域的流量就是这样产生的。最后通过S3提供的数据迁移工具,然后批量修改表的 location 解决掉跨区域的流量,下面附上排查的过程和修复方法。
原因排查
当运维发现我们美国区 EMR 机器跨区域的流量较大时,运维定位了一台机器给我,顺便问了下欧洲 s3 的网关地址。
于是我立刻登录上我们的 EMR 机器一顿乱操作。。
首先使用 netstat 命令加上 -p 参数定位到哪个进程在请求欧洲的网关地址
[root@ip-172-21-31-215 hadoop]# netstat -anop | grep 52.219
tcp 54 0 ::ffff:172.21.11.21:40484 ::ffff:52.219.11.21:443 ESTABLISHED 15428/java off (0.00/0/0)
从结果中可以看出,进程 id 为 15428 的 java 进程在与欧洲网关地址通信。继续使用ps命令查看 15428是什么任务
[root@ip-172-21-31-215 hadoop]# ps aux | grep 15428
yarn 15428 127 3.6 4101284 582660 ? Sl 03:35 2:23 /usr/lib/jvm/java-openjdk/bin/java -server -Xmx2048m -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:MaxHeapFreeRatio=70 -XX:+CMSClassUnloadingEnabled -XX:OnOutOfMemoryError=kill -9 %p -Djava.io.tmpdir=/mnt/yarn/usercache/hadoop/appcache/application_1586846714065_1434/container_1586846714065_1434_01_000002/tmp -Dspark.history.ui.port=18080 -Dspark.port.maxRetries=256 -Dspark.driver.port=37217 -Dspark.yarn.app.container.log.dir=/var/log/hadoop-yarn/containers/application_1586846714065_1434/container_1586846714065_1434_01_000002 org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@ip-172-21-30-200.eu-central-1.compute.internal:37217 --executor-id 1 --hostname ip-172-21-31-215.eu-central-1.compute.internal --cores 2 --app-id application_1586846714065_1434 --user-class-path file:/mnt/yarn/usercache/hadoop/appcache/application_1586846714065_1434/container_1586846714065_1434_01_000002/__app__.jar
root 18696 0.0 0.0 110520 2196 pts/0 S+ 03:37 0:00 grep --color=auto 15428
原来是 spark 任务的一个container,定位到他的 app id为application_1586846714065_1434。然后使用 yarn application -list 命令查看application_1586846714065_1434 的 name
[root@ip-172-21-31-215 hadoop]# yarn application -list | grep application_1586846714065_1434
20/04/22 03:37:31 INFO client.RMProxy: Connecting to ResourceManager at ip-172-21-30-200.eu-central-1.compute.internal/172.21.30.200:8032
application_1586846714065_1434 hera_job_id_1082 SPARK hadoop default RUNNING UNDEFINED 10% http://ip-172-21-30-200.eu-central-1.compute.internal:4041
赫拉任务调度提交的 spark sql 任务都会为其重命名为任务的 id 便于定位问题。通过上面的结果,我们可以清楚的看到是赫拉为 1082 的任务在请求跨区域流量。通过在赫拉任务调度平台上直接搜索1082就定位到是哪个脚本在执行任务了。最后我发现是算法库的整个库的 location 建在了欧洲区的 s3。
hive> show create database sucx_algorithm;
OK
CREATE DATABASE `sucx_algorithm`
LOCATION
's3://sucx-big-data-eu/bi/sucx_algorithm'
Time taken: 0.539 seconds, Fetched: 3 row(s)
hive>
找到了原因,剩下就是如何迁移。
迁移数据
迁移涉及到 s3 数据的迁移和 hive 元数据的迁移。
首先我要知道默认情况下 AWS EMR 的元数据是存储在 GLUE 的,由于GLUE 没调研到如何查元数据信息,原本是打算直接使用 jdbc 连接hiveserver2 进行 show create table 来获取表的 location 的。刚刚好我们今天要迁移 hive 元数据 glue 到 mysql(迁移的方式是:获取所有的建库语句,建表语句,在新的 mysql 元数据集群上执行建库、建表脚本,然后再msck repair table 修复表即可),所以直接查询元数据库获取所有要迁移表的 location 即可。
准备工作
首先获取要迁移的库的表所有 location
第一步:
首先从 DBS 中获取库的 DB_ID
mysql> select * from DBS where NAME='sucx_algorithm';
+-------+------+-----------------------------------------+----------------+------------+------------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE |
+-------+------+-----------------------------------------+----------------+------------+------------+
| 31 | NULL | s3://sucx-big-data-eu/bi/sucx_algorithm | sucx_algorithm | hadoop | USER |
+-------+------+-----------------------------------------+----------------+------------+------------+
1 row in set (0.00 sec)
第二步:
执行以下 sql 查询 sucx_algorithm 库的所有表名和表对应的LOCATION,并把其结果存到一个文档(可以通过mysql -hurl -uuser -Dmetastore -ppass -e "$sql" >location.txt来存储)
SELECT
TB.TBL_NAME,
SDS.LOCATION
FROM
(
SELECT
TBL_NAME,
SD_ID
FROM
TBLS
WHERE
DB_ID = 31
) TB
LEFT JOIN SDS ON TB.SD_ID = SDS.SD_ID
第二步产生的文档格式应该是如下:
| TBL_NAME | LOCATION |
|---|---|
| table1 | s3://sucx-big-data-eu/bi/sucx_algorithm/ table1 |
| table2 | s3://sucx-big-data-eu/bi/sucx_algorithm/ table2 |
| table3 | s3://sucx-big-data-eu/bi/sucx_algorithm/ table3 |
s3数据迁移与对比
s3 的数据要从欧洲区域的 bucket 迁移到美国区域的 bucket,直接使用s3提供的工具即可,由于我这里没有 s3 的操作权限,就不再演示。
关于迁移数据的对比,我是使用的hadoop fs -du -s 命令来检测的,检测大小的路径为准备工作中的 location 和其切换到美国后的 location。
元数据的修改
元数据修改语句为alter table tableName set location 's3://sucx-big-data-us/bi/sucx_algorithm/tableName'
库location的修改
sucx_algorithm 的库的 location 无法通过 alter 语句修改,所以我是直接更新的 DBS 元数据表。
总结
上面的 s3 数据迁移与对比与元数据的修改我使用了一个脚本来生成
//元数据库生成的表名和location的数据
File file = new File("/Users/scx/Desktop/location.txt");
try (BufferedReader br = new BufferedReader(new FileReader(file)))
String line;
StringBuilder shells = new StringBuilder("#!/bin/bash\\n");
int start = 0;
int end = 10000;
int index = 0;
//是生成alter table的sql文件还是生成对比eu/us的文件大小的脚本
boolean alterSql = false;
while ((line = br.readLine()) != null)
if (index >= end)
break;
if (start > index++)
continue;
String[] pair = line.split("\\\\s");
String tableName = pair[0];
String euLocation = pair[1];
//美国区的location
String usLocation = euLocation.replace("s3://sucx-big-data-eu/bi/", "s3://sucx-big-data-us/bi/");
if(alterSql)
shells.append("alter table sucx_algorithm.").append(tableName).append(" set location '").append(usLocation).append("';\\n");
else
shells.append("euSize=$(hadoop fs -du -s ").append(euLocation).append(" | awk 'print $1')\\n");
shells.append("usSize=$(hadoop fs -du -s ").append(usLocation).append(" | awk 'print $1')\\n");
shells.append("echo euSize is $euSize,usSize is $usSize,the index is ").append(index).append("\\n");
shells.append("if [ $euSize -ne $usSize ]; then").append("\\n");
shells.append(" echo ").append(euLocation).append(" not eq ").append(usLocation).append("\\n");
shells.append(" exit 1").append("\\n");
shells.append("fi").append("\\n");
System.out.println(shells.toString());
catch (IOException e)
e.printStackTrace();
对于生成的alter sql,我会全部 copy 到一个 alter.sql 文件中,然后使用hive -f 命令来修改所有表的location。
对于生成的大小对比脚本,由于执行较慢,我会使用定义的 start 和 end 变量来进行切分,来提高对比的速度。
以上是关于记一次大数据跨区域流量排查及修复的主要内容,如果未能解决你的问题,请参考以下文章