补充知识生成模型(generative model)和判别模型(discriminative model)贝叶斯学派和概率学派
Posted ViviranZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了补充知识生成模型(generative model)和判别模型(discriminative model)贝叶斯学派和概率学派相关的知识,希望对你有一定的参考价值。
看到过好几次“生成模型”这个词了,一直不太懂,这次买了李航老师的《统计学习方法》看一下。
统计学习分类:
基本分类:
监督学习(supervised learning):从标注数据中学习预测模型的机器学习问题
概念:输入空间、输出空间、特征空间(有时候不区分于输入空间),联合概率分布(P(X,Y)),假设空间(X→Y的映射集合)
无监督学习(unsupervised learning):从(大量)无标注数据中学习预测模型的机器学习问题
强化学习(reinforcement learning):智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。
半监督学习(semi-supervised learning):利用标注数据和未标注数据学习预测模型的机器学习问题。旨在利用未标注数据的信息辅助标注数据进行监督学习,以较低成本达到较好效果。
主动学习(active learning):机器不断主动给出实例让教师进行标注;“被动学习”日常给出的标记数据往往是随机得到。
半监督和主动学习更接近监督学习。
模型分类:
1.
概率模型(probabilistic model):目标函数是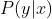
【实例】决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在迪利克雷分配、高斯混合模型
确定性模型(deterministic model):目标函数是
【实例】感知机、支持向量机、K近邻、AdaBoost、k均值、潜在语义分析、神经网络
相互转换: 条件概率分布最大化后可得到函数,函数归一化后得到条件概率分布。因此,区别不在于映射关系而在于内在结构,概率模型一定可以表示为联合概率分布的形式(变量可为输入、输出、隐变量甚至参数),而确定性模型不一定表示为联合概率分布。
2.
参数化模型(parametric model):假设模型参数维数固定,模型可以由有限维参数完全刻画
【实例】感知机、朴素贝叶斯、逻辑斯蒂回归、k均值、高斯混合模型
非参数化模型(non-parametric model):假设模型参数维数不固定或者无穷大,随着训练增加不断增大。
【实例】决策树、SVM、AdaBoost、k近邻、潜在语义分析、概率潜在语义分析、潜在迪利克雷分配
参数化模型适合问题简单,非参数化应用广
按算法分类
在线学习(online learning)/批量学习(batch learning)
有些应用必须在线,比如数据依次达到无法存储,需要及时处理,数据规模大不能一次处理,数据模式随时间动态变化、需快速适应(不满足OOD)。
按技巧分类
贝叶斯方法(Bayesian method)【朴素贝叶斯、潜在迪利克雷分配】/核方法(kernel method)【SVM、核PCA、核k均值】
统计学习方法三要素
模型+策略+算法
模型
在监督学习里,模型就是要学习的条件概率分布或者决策函数。
假设空间(hypothesis space)包含所有可能的条件概率分布或者决策函数。
假设空间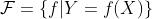 ,这时候
,这时候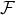 通常是由一个参数向量决定的函数族
通常是由一个参数向量决定的函数族

假设空间 ,这时候通常是由一个参数向量决定的条件概率分布族
,这时候通常是由一个参数向量决定的条件概率分布族

策略
损失函数和风险函数(略)
算法
具体计算方法,归结为优化问题。
模型评估与模型选择
训练误差与测试误差
略
过拟合与模型选择
略
正则化与交叉验证
正则化
regularization,限制模型的复杂度,符合奥卡姆刺刀原理
交叉验证
cross validation,训练集-验证集-测试集重复使用反复切分。
泛化能力
虽然我们现在做的OOD泛化,但是这个实在苍白,留一下定理吧。

生成模型和判别模型
监督学习方法的一种分类
生成方法(generative approach )
由数据学习联合概率分布 ,然后求出条件概率分布
,然后求出条件概率分布 作为预测的模型,即生成模型
作为预测的模型,即生成模型

之所以称为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系。【朴素贝叶斯法和隐马尔可夫模型】
判别方法(discriminative approach)
由数据直接学习决策函数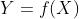 或者条件概率分布。判别方法关心的是对于给定的输入X,应该预测什么样的Y(简单粗暴,不考虑具体分布了)。【k近邻法、感知机、决策树、逻辑斯蒂回归模型、最大熵模型、支持向量机、提升方法、条件随机场等、
或者条件概率分布。判别方法关心的是对于给定的输入X,应该预测什么样的Y(简单粗暴,不考虑具体分布了)。【k近邻法、感知机、决策树、逻辑斯蒂回归模型、最大熵模型、支持向量机、提升方法、条件随机场等、
特点:
生成方法:可以还原出联合概率分布(判别方法不行),收敛速度更快(当样本容量增加,学到模型可以更快收敛于真实模型),存在隐变量的时候仍然可用。
判别方法:直接面对预测准确率更高,直接学习时候可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
【补充】贝叶斯学派和概率学派
主要看的这篇博文
统计学里频率学派(Frequentist)与贝叶斯(Bayesian)学派的区别和在机器学习中的应用 - 知乎
频率学派与贝叶斯学派的最主要区别:是否允许先验概率分布的使用
- 概率学派不假设任何的先验知识,不参照过去的经验,只按照当前已有的数据进行概率推断
- 贝叶斯学派会假设先验知识的存在,然后再用采样逐渐修改先验知识并逼近真实知识
因此贝叶斯推论中前一次得到的后验概率分布可以作为后一次的先验概率。但实际上,在数据量趋近无穷时,频率学派和贝叶斯学派得到的结果是一样的,也就是说频率方法是贝叶斯方法的极限。【关系】
考虑的试验次数非常少的时候,贝叶斯方法的解释非常有用。此外,贝叶斯理论将我们对于随机过程的先验知识纳入考虑,当我们获得的数据越来越多的时候,这个先验的概率分布就会被更新到后验分布中。
频率论和贝叶斯方法各有其优劣
频率派的优点则是没有假设一个先验分布,因此更加客观,也更加无偏,在一些保守的领域比如制药业、法律比贝叶斯方法更受到信任。并且频率论方法比贝叶斯方法更容易实施,然而却更难解释。【概率更值得信任,但是难解释】
贝叶斯派因为所有的参数都是随机变量,都有分布,因此可以使用一些基于采样的方法如MCMC方法(Markov Chain Monte Carlo))使得我们更容易构建复杂模型。【更容易使用(面对复杂情况)】
以上是关于补充知识生成模型(generative model)和判别模型(discriminative model)贝叶斯学派和概率学派的主要内容,如果未能解决你的问题,请参考以下文章