MySQL基础语句总结
Posted 小王子jvm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL基础语句总结相关的知识,希望对你有一定的参考价值。
基本介绍
数据库可以持久化数据到本地,结构化查询。
三个基本名词:
- DB:数据库,存储数据的容器
- DBMS:数据库管理系统,又称为数据库软件或数据库产品,用于创建或管理DB
- SQL:结构化查询语言,用于和数据库通信的语言,不是某个数据库软件特有的,而是几乎所有的主流数据库软件通用的语言
数据库存储数据的特点:
-
数据存放到表中,然后表再放到库中
-
一个库中可以有多张表,每张表具有唯一的表名用来标识自己
-
表中有一个或多个列,列又称为“字段”,相当于java中“属性”
-
表中的每一行数据,相当于java中“对象”
SQL语言的分类
DML(Data Manipulation Language):数据操纵语句,用于添加、删除、修改、查询数据库记录,并检查数据完整性。包括如下SQL语句:
- INSERT:添加数据到数据库中。
- UPDATE:修改数据库中的数据。
- DELETE:删除数据库中的数据。
- SELECT:选择(查询)数据。
DDL(Data Definition Language):定义数据库的结构,比如创建、修改或删除数据库对象,包括如下SQL语句:
- CREATE TABLE:创建数据库表
- ALTER TABLE:更改表结构、添加、删除、修改列长度
- DROP TABLE:删除表
- CREATE INDEX:在表上建立索引
- DROP INDEX:删除索引
DCL(Data Control Language):数据控制语句,用于定义用户的访问权限和安全级别。包括如下SQL语句:
-
GRANT:授予访问权限
-
REVOKE:撤销访问权限
-
COMMIT:提交事务处理
-
ROLLBACK:事务处理回退
-
SAVEPOINT:设置保存点
-
LOCK:对数据库的特定部分进行锁定
基本的命令
首先是数据库的下载,Windows平台下下载:http://dev.mysql.com/downloads/mysql
下载安装后,可以——右击计算机—管理—服务—启动或停止MySQL服务。但是座位于i个程序员,这种方式也太low了,所以这几个命令可以看看:
-
启动:
net start mysql服务名 -
停止:
net stop mysql服务名 -
登录
mysql [-h 主机名 -P 端口号] –u用户名 –p密码,[]这个是可选的,用于远程连接。 -
退出
exit
一个基本的操作流程
- 进入 mysql, 在命令行中输入: mysql –uroot –p#### (其中:####表示密码)
- 查看 mysql 中有哪些个数据库: show databases;

-
使用一个数据库: use 数据库名称;
-
新建一个数据库: create database 数据库名
-
查看指定的数据库中有哪些数据表: show tables;
-
建表。
-
查看表的结构:desc 表名
-
删除表: drop table 表名
这是对数据库以及表的一些基本的操作命令,只展示两张基本操作截图,其他操作可以自行测试。
然后就是对表的数据经行基本的操作:
-
查看表中的所有记录: select * from 表名;
-
向表中插入记录:insert into 表名(列名列表) values(列对应的值的列表);
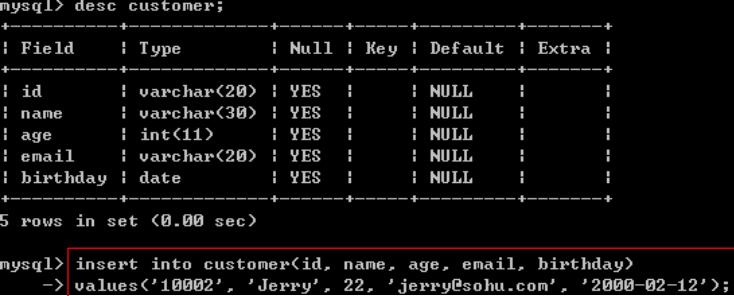
-
注意:插入 varchar 或 date 型的数据要用 单引号 引起来
-
修改记录: update 表名 set 列1 = 列1的值, 列2 = 列2的值 where …
-
删除记录: delete from 表名 where ….
这大概就是一个最基本的操作了,详细的操作将在下面展开。
DML语句
上面也基本说明了DML就是对数据(也就是表)的基本操作。
SELECT 语句
查询应该是使用最为频繁的一种操作了。数据库的优化,也基本上就是对查询的优化。
基础查询
基本的语法
select 查询列表 from 表名;。例如:select * from student;这就是对student查询所有的数据。
- 查询列表可以是字段、常量、表达式、函数,也可以是多个
- 查询结果是一个虚拟表
查询单个字段:select 字段名 from 表名;。例如:select name,age from student;只查询这两个字段。
特别注意:
- SQL 语言大小写不敏感。
- SQL 可以写在一行或者多行
- 关键字不能被缩写也不能分行
- 各子句一般要分行写。
- 使用缩进提高语句的可读性。
查询的时候可以给查询到的列取一个别名,方便数据的展示。
规则:紧跟列名,也可以在列名和别名之间加入关键字 ‘AS’,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。
例如:select name as studentName,age "studentAge" from student;
去重查询,有时候不需要重复的数据就可以使用关键字来对这个数据去重,语法如下:
select distinct 字段名 from 表名;
带条件的查询
使用WHERE 子句,将不满足条件的行过滤掉。WHERE 子句紧随 FROM 子句。语法如下:
select 查询列表 from 表名 where 筛选条件,例如:(只查询部门id为90的员工)

也可以加其他的比较运算符:
简单条件运算符:> < = <> != >= <= <=>安全等于

逻辑运算符:&& and || or ! not,如果有多个条件,可以使用逻辑运算符连接起来:

其它比较运算:
| 操作符 | 含义 |
|---|---|
BETWEEN ...AND... | 在两个值之间 (包含边界) |
IN(set) | 等于值列表中的一个 |
LIKE | 模糊查询 |
IS NULL | 空值 |
使用 IS (NOT) NULL 判断空值,例如:select * from student where name is NULL
使用 BETWEEN 运算来显示在一个区间内的值:

使用 IN运算显示列表中的值:

模糊查询
使用 LIKE 运算选择类似的值,选择条件可以包含字符或数字:
- % 代表零个或多个字符(任意个字符)。
- _ 代表一个字符。
如下图,查询名字开头单词为S的,后面是啥都行,只要求开头为S,比如Ssdg也会被查询出来。

如果说上面这个例子%改为 _ ,那就变成了后面只能有一个字符。
‘%’和‘-’可以同时使用:select * from student where name like %进_
排序查询
基本语法:select 查询列表 from 表 where 筛选条件 order by 排序列表 【asc | desc】
- asc :升序,如果不写默认升序。desc:降序
- 排序列表 支持 单个字段、多个字段、函数、表达式、别名
- order by的位置一般放在查询语句的最后(除limit语句之外)

如果最后不加DESC,默认就是ASC升序的方式。
如果我们的字段取了别名,使用这个字段排序就需要使用别名:(salary*12 扩大12倍)

如果使用多个字段排序,按照ORDER BY 列表的顺序排序。(也就是按照写在前面的排序,如果有相等的就在按照后面的字段再次排序)

比如这个,由于department_id后面没有DESC,所以默认按照这个字段升序排列,然后有相等的再按照后面的salary降序排列。
函数
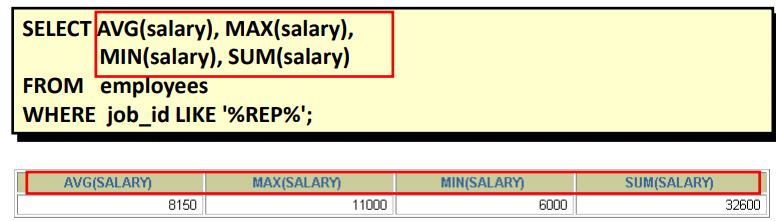
分组函数作用于一组数据,并对一组数据返回一个值。

组函数类型:
- AVG() 求平均值
- COUNT() 求总量
- MAX() 求最大值
- MIN() 最小值
- SUM() 求和
可以对数值型数据使用AVG 和 SUM 函数,可以对==任意数据类型(字符按照字典排序)==的数据使用 MIN 和 MAX 函数。
COUNT(*) 返回表中记录总数,适用于任意数据类型:
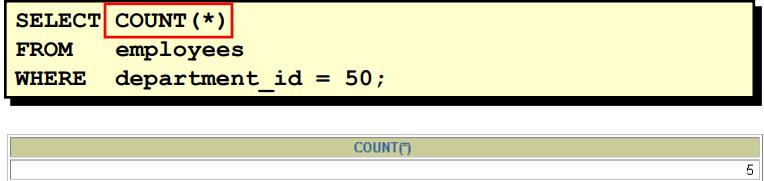
COUNT(expr) 返回expr不为空的记录总数。
分组查询
可以使用GROUP BY子句将表中的数据分成若干组,语法如下:
select 分组函数,分组后的字段
from 表
【where 筛选条件】
group by 分组的字段
【having 分组后的筛选】
【order by 排序列表】
在SELECT 列表中所有未包含在组函数中的列都应该包含 在 GROUP BY 子句中。

包含在 GROUP BY 子句中的列不必包含在SELECT 列表中,就比如上面这个例子中的department_id在select中就可以不写,但是结果不会包含这个列。
WHERE 子句中不能使用组函数
使用 HAVING 过滤分组:(跟where用法一样,作用域不同)
- 行已经被分组。
- 使用了组函数。
- 满足HAVING 子句中条件的分组将被显示。
多表查询
多个表可以经行联合的数据查询并展示,语法如下:select 字段 from 表1,表2,...;
笛卡尔集会在下面条件下产生:(效率很低)
- 省略连接条件
- 连接条件无效
- 所有表中的所有行互相连接
为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件。
- 在 WHERE 子句中写入连接条件。
- 在表中有相同列时,在列名之前加上表名前缀。
等值连接:
SELECT beauty.id,NAME,boyname FROM beauty ,boys
WHERE beauty.`boyfriend_id`=boys.id;
区分重复的列名
- 使用表名前缀在多个表中区分相同的列。
- 在不同表中具有相同列名的列可以用表的别名加以区分。
- 如果使用了表别名,则在select语句中需要使用表别名代替表名
- 表别名最多支持32个字符长度,但建议越少越好
连接 n个表,至少需要 n-1个连接条件。
内连接
基本的语法格式:(别名可取可不取)
select 查询列表
from 表1 别名
[inner] join 表2 别名 on 连接条件
where 筛选条件
group by 分组列表
having 分组后的筛选
order by 排序列表
limit 子句;
这种链接的特点:
- 表的顺序可以调换
- 内连接的结果=多表的交集
- n表连接至少需要n-1个连接条件
举个例子:
#案例.查询名字中包含e的员工名和工种名(添加筛选)
SELECT last_name,job_title
FROM employees e
INNER JOIN jobs j
ON e.`job_id`= j.`job_id`
WHERE e.`last_name` LIKE '%e%';
外连接
基本的语法格式:
select 查询列表
from 表1 别名
left|right|full [outer] join 表2 别名 on 连接条件
where 筛选条件
group by 分组列表
having 分组后的筛选
order by 排序列表
limit 子句;
这种连接的特点:
- 查询的结果=主表中所有的行,如果从表和它匹配的将显示匹配行,如果从表没有匹配的则显示null
left join左边的就是主表,right join右边的就是主表,full join两边都是主表- 一般用于查询除了交集部分的剩余的不匹配的行
举些例子:
#案例1:查询哪个部门没有员工,左外
SELECT d.*,e.employee_id
FROM departments d
LEFT OUTER JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
#右外
SELECT d.*,e.employee_id
FROM employees e
RIGHT OUTER JOIN departments d
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
#全外
USE girls;
SELECT b.*,bo.*
FROM beauty b
FULL OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.id;
John连接总结
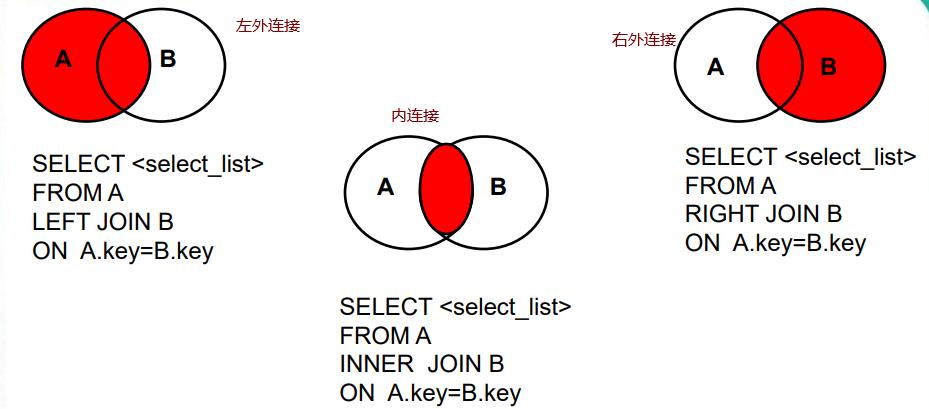
举个例子
- 笛卡尔积
SELECT * FROM t_dept, t_emp;
t_dept共20条记录,t_emp共6条记录。两表共同查询后共120条记录
- 内连接
SELECT * FROM t_emp a INNER JOIN t_dept b ON a.deptId = b.id;
只会把两个表共有的部分查询出来
- 左外连接
SELECT * FROM t_emp a LEFT JOIN t_dept b ON a.deptId = b.id;
取出左表的所有数据,然后有伴的数据满足就查询出来,不满足就填充null,和右外连接一致
- 右外连接
SELECT * FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id;
- 左外连接取左表的独有部分
SELECT * FROM t_emp e LEFT JOIN t_dept d ON d.`id` = e.`deptId` WHERE d.id IS NULL
- 右外连接取右表的独有部分
SELECT * FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id WHERE a.deptId IS NULL;
注意:判断字段是否为NULL时,不能使用’=’
因为 = NULL 的结果不会报错,但是结果永远为false。所以必须使用IS NULL来进行判空
- 全外连接
MySQL不支持全外连接,要查询两个表的全集,需要合并两个查询结果,所以要使用 UNION 关键字
SELECT * FROM t_emp a LEFT JOIN t_dept b ON a.deptId = b.id
UNION
SELECT * FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id;
这种连接会把两个表有的都获取出来,然后对应的没有的置为null
- 查询两表独有内容
SELECT * FROM t_emp a LEFT JOIN t_dept b ON a.deptId = b.id WHERE b.id IS NULL
UNION
SELECT * FROM t_emp a RIGHT JOIN t_dept b ON a.deptId = b.id WHERE a.deptId IS NULL;
子查询和分页查询
子查询
出现在其他语句内部的select语句,称为子 查询或内查询内部嵌套其他select语句的查询,称为外查询或主查询
例如:
select first_name from employees where department_id in(
select department_id from departments where location_id=1700
)
特别注意:
- 子查询要包含在括号内。
- 将子查询放在比较条件的右侧。
- 子查询 (内查询) 在主查询之前一次执行完成
- 子查询的结果被主查询(外查询)使用 。
举个例子:谁的工资比 Abel 高?
SELECT last_name
FROM employees
WHERE salary > (SELECT salary FROM employees WHERE last_name = 'Abel');
会先执行完子查询,然后结果供主查询使用。
分页查询
当要查询的条目数太多,一页显示不全,这个时候就可以使用分页查询。
基本的语法格式:
select 查询列表
from 表
limit [offset,] size;
# 注意:
offset代表的是起始的条目索引,默认从0开始
size代表的是显示的条目数
一个固定的分页公式:
假如要显示的页数为page,每一页条目数为size:select 查询列表 from 表 limit (page-1)*size,size;
举个例子:
#案例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5;
#案例2:查询第11条——第25条
SELECT * FROM employees LIMIT 10,15;
总结查询以及执行顺序
select 查询列表 7
from 表1 别名 1
连接类型 join 表2 2
on 连接条件 3
where 筛选 4
group by 分组列表 5
having 筛选 6
order by排序列表 8
limit 起始条目索引,条目数; 9
增删改
insert语句
基本语法格式:insert into 表名(字段名,...) values(值,...);
特别注意:
-
要求值的类型和字段的类型要一致或兼容
-
字段的个数和顺序不一定与原始表中的字段个数和顺序一致,但必须保证值和字段一一对应
-
假如表中有可以为null的字段,注意可以通过以下两种方式插入null值
- 字段和值都省略
- 字段写上,值使用null
-
字段和值的个数必须一致
-
字段名可以省略,默认所有列
举个例子:
INSERT INTO departments(department_id, department_name,manager_id, location_id)
VALUES (70, 'Public Relations', 100, 1700);
如果有日期类型:字符和日期型数据应包含在单引号中。
INSERT INTO employees(employee_id,last_name,email,hire_date,job_id)
VALUES (300,’Tom’,’tom@126.com’,to_date(‘2012-3-21’,’yyyy-mm-dd’),’SA_RAP’);
一次插入多条语句的语法:insert into 表名【(字段名,..)】 values(值,..),(值,...)
举个例子:
INSERT INTO departments(department_id, department_name,manager_id, location_id)
VALUES
(70, 'Public Relations', 100, 1700),
(71, 'Public sdf', 23, 65745),
(72, 'Public asdg', 54, 3454);
update语句
基本的语法格式:update 表名 set 字段=值,字段=值 【where 筛选条件】;
可以一次更新多条数据。如果需要回滚数据,需要保证在DML前,进行 设置:SET AUTOCOMMIT = FALSE;
使用 WHERE 子句指定需要更新的数据:
UPDATE employees SET department_id = 70 WHERE employee_id = 113;
如果省略 WHERE 子句,则表中的所有数据都将被更新:
UPDATE copy_emp SET department_id = 110;
delete语句
基本的语法格式:delete from 表名 【where 筛选条件】【limit 条目数】
使用 WHERE 子句删除指定的记录:delete from departments where department_name = 'Finance';
如果省略 WHERE 子句,则表中的全部数据将被删除:DELETE FROM copy_emp;
DDL语句
这个部分相对上面内容就少了很多了。
数据库的管理
创建数据库:create database [if not exists] 库名 [character set 字符集名];
修改库:alter database 库名 character set 字符集名;
删除库:drop database [if exists] 库名;
相关其他命令,这个一般用于命令行中:
- show databases;查看当前所有数据库
- use employees;“使用”一个数据库,使其作为当前数据库
表的管理语句
创建表:
create table 【if not exists】 表名(
字段名 字段类型 【约束】,
字段名 字段类型 【约束】,
。。。
字段名 字段类型 【约束】
)
# 举个例子:
CREATE TABLE dept(
deptno INT(2),
dname VARCHAR(14),
loc VARCHAR(13)
);
常用的数据类型:
| INT | 使用4个字节保存整数数据 |
|---|---|
| CHAR(size) | 定长字符数据。若未指定,默认为1个字符,最大长度255 |
| VARCHAR(size) | 可变长字符数据,根据字符串实际长度保存,必须指定长度 |
| FLOAT(M,D) | 单精度,M=整数位+小数位,D=小数位。 D<=M<=255,0<=D<=30, 默认M+D<=6 |
| DOUBLE(M,D) | 双精度。D<=M<=255,0<=D<=30,默认M+D<=15 |
| DATE | 日期型数据,格式’YYYY-MM-DD’ |
| BLOB | 二进制形式的长文本数据,最大可达4G |
| TEXT | 长文本数据,最大可达4G |
修改表的语句:
-
添加列:
alter table 表名 add column 列名 类型 [first|after 字段名]; -
修改列的类型或约束:
alter table 表名 modify column 列名 新类型 [新约束]; -
修改列名:
alter table 表名 change column 旧列名 新列名 类型; -
删除列:
alter table 表名 drop column 列名; -
修改表名:
alter table 表名 rename [to] 新表名; -
删除表:
drop table [if exists] 表名;
建表的时候常见的约束
NOT NULL:非空,该字段的值必填UNIQUE:唯一,该字段的值不可重复DEFAULT:默认,该字段的值不用手动插入有默认值CHECK:检查,mysql不支持PRIMARY KEY:主键,该字段的值不可重复并且非空 unique+not nullFOREIGN KEY:外键,该字段的值引用了另外的表的字段
主键:一个表至多有一个主键,主键本生就包含了唯一和非空两个约束
外键的作用和注意点:
- 用于限制两个表的关系,从表的字段值引用了主表的某字段值
- 外键列和主表的被引用列要求类型一致,意义一样,名称无要求
- 主表的被引用列要求是一个key(一般就是主键)
- 插入数据,先插入主表
- 删除数据,先删除从表
create table 表名(
字段名 字段类型 not null,#非空
字段名 字段类型 primary key,#主键
字段名 字段类型 unique,#唯一
字段名 字段类型 default 值,#默认
constraint 约束名 foreign key(字段名) references 主表(被引用列)
)
在一张数据表建好之后,这些约束也可以通过SQL语句经行修改或者删除:
- 添加非空:
alter table 表名 modify column 字段名 字段类型 not null; - 删除非空:
alter table 表名 modify column 字段名 字段类型 ; - 添加默认:
alter table 表名 modify column 字段名 字段类型 default 值; - 删除默认:
alter table 表名 modify column 字段名 字段类型 ; - 添加主键:
alter table 表名 add [constraint 约束名] primary key(字段名); - 删除主键:
alter table 表名 drop primary key;
更多的写法就自行搜索吧。
的字段值引用了主表的某字段值
- 外键列和主表的被引用列要求类型一致,意义一样,名称无要求
- 主表的被引用列要求是一个key(一般就是主键)
- 插入数据,先插入主表
- 删除数据,先删除从表
create table 表名(
字段名 字段类型 not null,#非空
字段名 字段类型 primary key,#主键
字段名 字段类型 unique,#唯一
字段名 字段类型 default 值,#默认
constraint 约束名 foreign key(字段名) references 主表(被引用列)
)
在一张数据表建好之后,这些约束也可以通过SQL语句经行修改或者删除:
- 添加非空:
alter table 表名 modify column 字段名 字段类型 not null; - 删除非空:
alter table 表名 modify column 字段名 字段类型 ; - 添加默认:
alter table 表名 modify column 字段名 字段类型 default 值; - 删除默认:
alter table 表名 modify column 字段名 字段类型 ; - 添加主键:
alter table 表名 add [constraint 约束名] primary key(字段名); - 删除主键:
alter table 表名 drop primary key;
更多的写法就自行搜索吧。
以上是关于MySQL基础语句总结的主要内容,如果未能解决你的问题,请参考以下文章