hadoop完全分布式02
Posted wyju
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop完全分布式02相关的知识,希望对你有一定的参考价值。
大家按照之前的链接进行安装好之后进入到这里安装高可用
https://blog.csdn.net/weixin_45955039/article/details/118784204?spm=1001.2014.3001.5502
1.进入到hadoop的配置文件中
cd /usr/local/hadoop/etc/hadoop/
2.配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- hdfs 的数据存储位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<!-- hdfs 的访问地址,ns 是 NameNode 集群的名字,在 hdfs-site.xml 文件配置 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 允许 hive 中的用户操作操纵 hdfs -->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!-- 配置 zookeeper 地址,JournalNode 通过 zookeeper 实现功能 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
3.配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 设置 NameNode 集群的名字为 ns -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- 为 ns 集群中的每个 NameNode 起一个名字,分别是 nn1, nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- 分别配置每个 NameNode 的请求端口和监控页面端口 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<!-- 在哪些节点启动 JournalNode 进程,用于在两个 NameNode 之间同步 fsimage 和 edits,通常是单数个 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
</property>
<!-- JournalNode 进程数据的存储位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp/journal</value>
</property>
<!-- NameNode 进程数据的存储位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!-- DataNode 进程数据的存储位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<!-- 启用自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置切换 Active 和 StrandBy 状态的类 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 使用 fence 软件进行切换 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- fence 使用需要指定私钥的地址 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- NameNode 等待 JournalNode 启动的超时时间 -->
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>60000</value>
</property>
</configuration>
4.修改slaves
vim slaves
master
slave1
slave2
5.将修改好的文件发送给另外两台虚拟机
scp -r /usr/local/hadoop/etc/hadoop slave1:`pwd`
scp -r /usr/local/hadoop/etc/hadoop slave2:`pwd`
6.启动zookeeper
zkServer.sh start
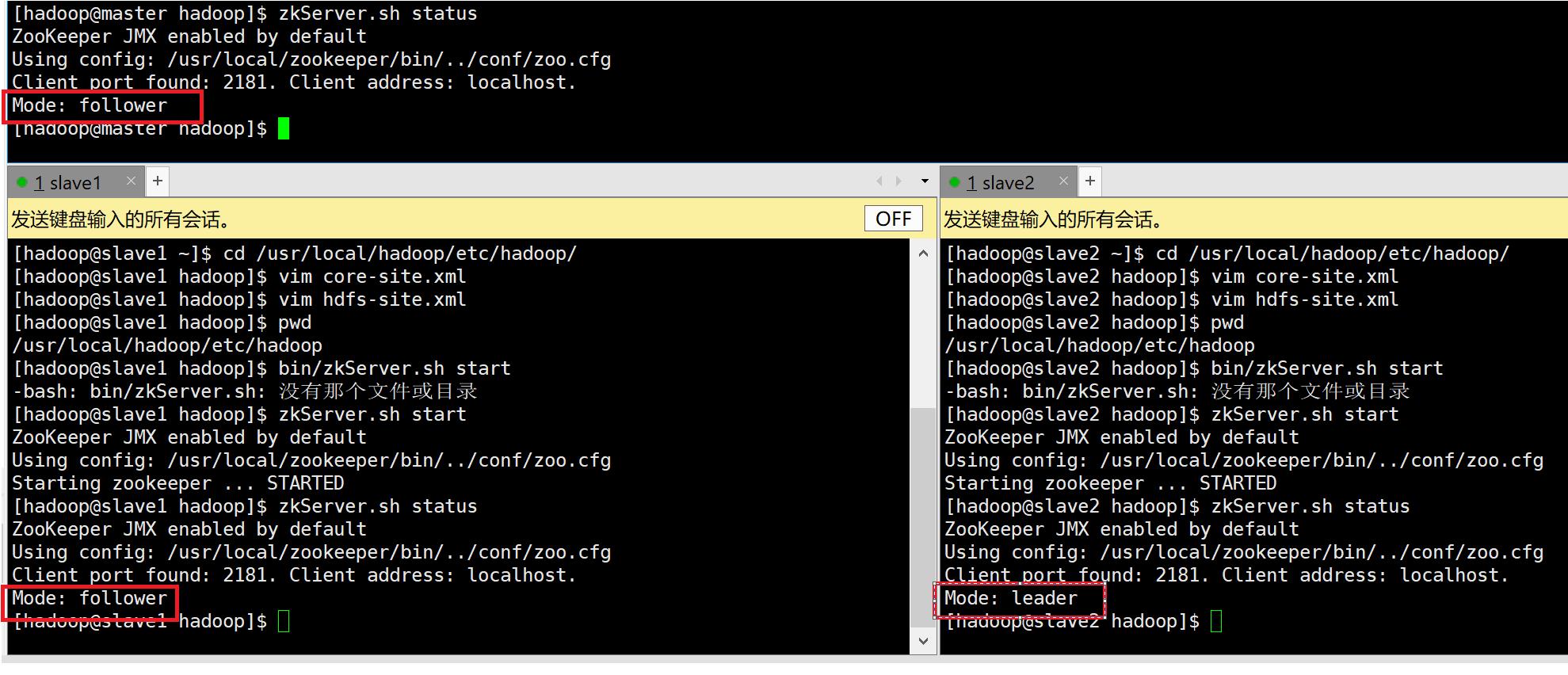
7。查看zookeeper状态
zkServer.sh status
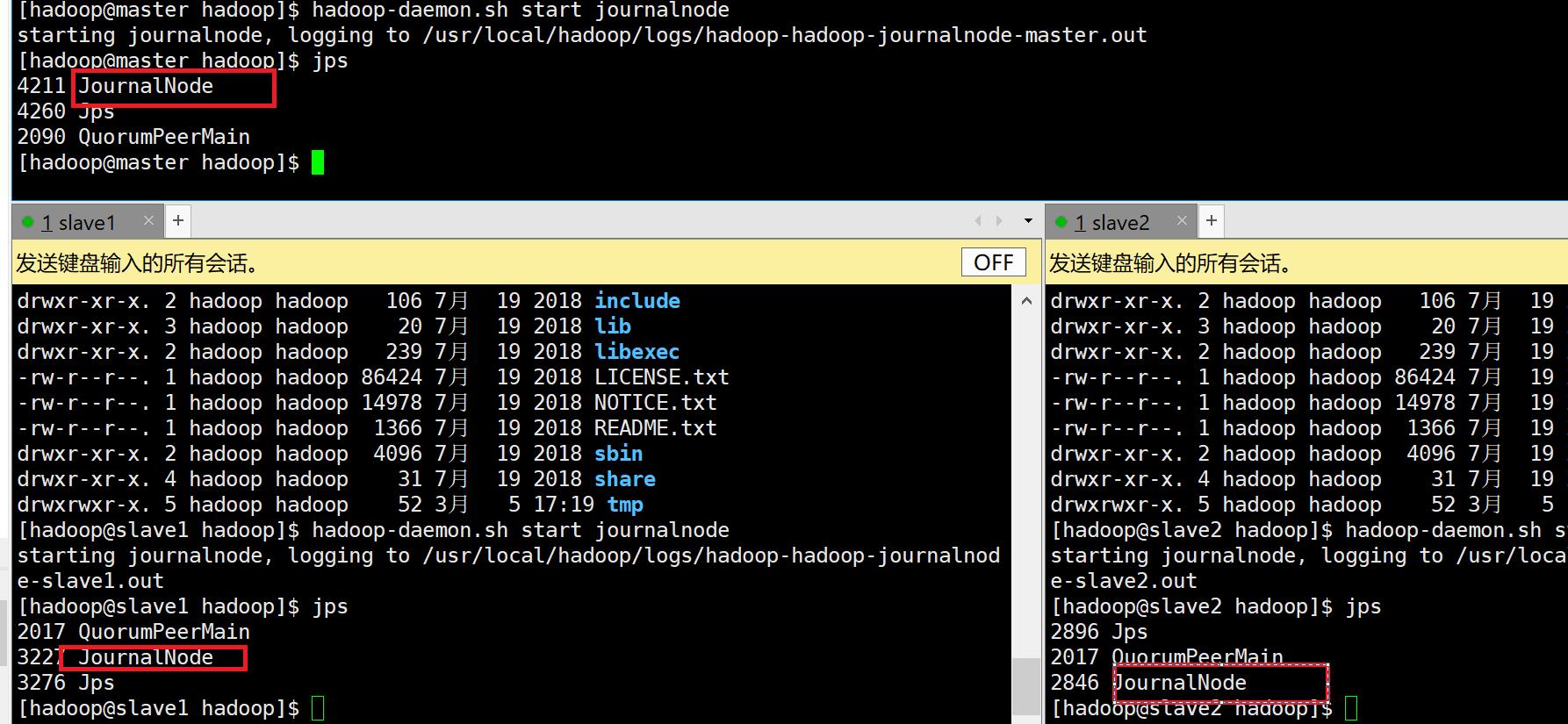
8. 3个节点都使用以下命令启动JournalNode
hadoop-daemon.sh start journalnode
9.在master上格式化NameNode,在master使用以下命令:
hdfs namenode -format

10.启动master上的NameNode,在master使用以下命令:
hadoop-daemon.sh start namenode
11.同步master上NameNode的数据到slave1,在slave1使用以下命令:
hdfs namenode -bootstrapStandby
12.关闭master上的NameNode,在master使用以下命令:
hadoop-daemon.sh stop namenode
13. 在master初始化Zookeeper监控工具,在master使用以下命令:
hdfs zkfc -formatZK
14.在master启动hdfs,yarn
#关闭hdfs,yarn
sbin/stop-dfs.sh
sbin/stop-yarn.sh
#启动hdfs,yarn
sbin/start-dfs.sh
sbin/start-yarn.sh
#启动所有
sbin/start-all.sh
#关闭所有
sbin/stop-all.sh

以上是关于hadoop完全分布式02的主要内容,如果未能解决你的问题,请参考以下文章