大数据必经之路-认识Spark
Posted jeff-y
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据必经之路-认识Spark相关的知识,希望对你有一定的参考价值。
大数据之——认识spark
什么是spark?
-
wiki:Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介资料存放到磁盘中,Spark使用了存储器内运算技术,能在资料尚未写入硬盘时即在存储器内分析运算。Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。[1]Spark允许用户将资料加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法。[2]
-
通过官方文档的介绍我们了解到了Spark就是一个开源的大数据集群运算框架,对于我们已知的大数据运算运算框架MapReduce来讲是类似的计算框架,只不过两者在设计上有区别,也从而导致了性能上的差距。接下来分为两个部分认识一下Spark。
2. spark 编程模型
- 从hadoop的MapReduce的对比我们来进行学习spark,首先spark相对于mapReduce来讲,spark在性能和使用方面是优于mapReduce的,其中原因之一那这里不得不提到Spark的核心,也就是spark的编程模型RDD 弹性数据集(Resilient Distributed Datasets)
- RDD 既是 Spark 面向开发者的编程模型,又是 Spark 自身架构的核心元素。
- 大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段,一个 Reduce 阶段,可以理解成是面向过程的大数据计算。
- 我们在用 MapReduce 编程的时候,思考的是,如何将计算逻辑用 Map 和 Reduce 两个阶段实现。而 Spark 则直接针对数据进行编程,将大规模数据集合抽象成一个 RDD 对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。所以 Spark 可以理解成是面向对象的大数据计算。在这里其实也可以联想一下在java中的stream流,我们将一个数据集装换成我们所谓的stream流然后进行一系列的函数操作,其中有一部分函数是在操作完成后还是stream流,这种函数在spark中叫做transformation函数,另一种函数则是直接得到最终的结果。在spark中也就是得到做种的数据文件这在spark中叫action函数。
- 所以我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都在 RDD 上。RDD就是我们的编程对象,让后通过RDD的内置函数,进行数据的操作。我们可以看一下Spark的RDD是如何实现大数据编程的hello word (word count)下图是scala语言写的,是我喜欢的style
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
- 刚也说了RDD有两种函数,一种transformation 一种是Action 。还有具体RDD 是怎么一种形式和方式存在,在后续我们继续了解
在进行了解spark 和 mapReduce的区别时,看到一个大佬所讲:人们在 Spark 出现之后,才开始对 MapReduce 不满。原来大数据计算速度可以快这么多,编程也可以更简单。而且 Spark 支持 Yarn 和 HDFS,公司迁移到 Spark 上的成本很小,于是很快,越来越多的公司用 Spark 代替 MapReduce。也就是说,因为有了 Spark,才对 MapReduce 不满;而不是对 MapReduce 不满,所以诞生了 Spark。真实的因果关系是相反的。这里有一条关于问题的定律分享给你:我们常常意识不到问题的存在,直到有人解决了这些问题。
3. spark 的架构原理
-
我们先看看Spark的架构图是怎么样的
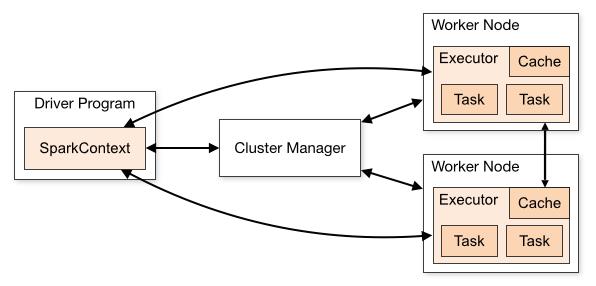
-
应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor;
- 驱动(Driver): 运行Application的main()函数并且创建SparkContext;
- 执行单元(Executor): 是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors;
- 集群管理程序(Cluster Manager): 在集群上获取资源的外部服务(例如:Local、Standalone、Mesos或Yarn等集群管理系统);
- 操作(Operation): 作用于RDD的各种操作分为Transformation和Action. -
整个 Spark 集群中,分为 Master 节点与 worker 节点,其中 Master 节点上常驻 Master 守护进程和 Driver 进程, Master 负责将串行任务变成可并行执行的任务集Tasks, 同时还负责出错问题处理等,而 Worker 节点上常驻 Worker 守护进程, Master 节点与 Worker 节点分工不同, Master 负载管理全部的 Worker 节点,而 Worker 节点负责执行任务.
-
Driver 的功能是创建 SparkContext, 负责执行用户写的 Application 的 main 函数进程,Application 就是用户写的程序.
Spark 支持不同的运行模式,包括Local, Standalone,Mesoses,Yarn 模式.不同的模式可能会将 Driver 调度到不同的节点上执行.集群管理模式里, local 一般用于本地调试. -
每个 Worker 上存在一个或多个 Executor 进程,该对象拥有一个线程池,每个线程负责一个 Task 任务的执行.根据 Executor 上 CPU-core 的数量,其每个时间可以并行多个 跟 core 一样数量的 Task.Task 任务即为具体执行的 Spark 程序的任务.*
总结
- 认识到spark是一个开源的大数据分布式计算框架,比hadoop的MapReduce晚出来,且优秀
- Spark的编程模型RDD,包括RDD的两种函数 Transformation 和 Action
- Spark的架构模型原理,以及大概Run的过程
- 令人影像很深刻的一句话:我们常常意识不到问题的存在,直到有人解决了这些问题
参考
- https://time.geekbang.org/column/article/69978(极客时间)
- https://zhuanlan.zhihu.com/p/34436165
以上是关于大数据必经之路-认识Spark的主要内容,如果未能解决你的问题,请参考以下文章