Java synchronized实现原理深度剖析
Posted RockyPeng3
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java synchronized实现原理深度剖析相关的知识,希望对你有一定的参考价值。
Sync的实现原理
sync是jvm的内置锁,底层是通过对象监视器(ObjectMonitor)来实现。而对象监视器的底层实现是通过cas+自旋或者操作系统的互斥量来实现的。通过javap -c 命令可以查看到sync方法前后有成对的monitorenter/monitorexit指令。
ObjectMonitor的结构
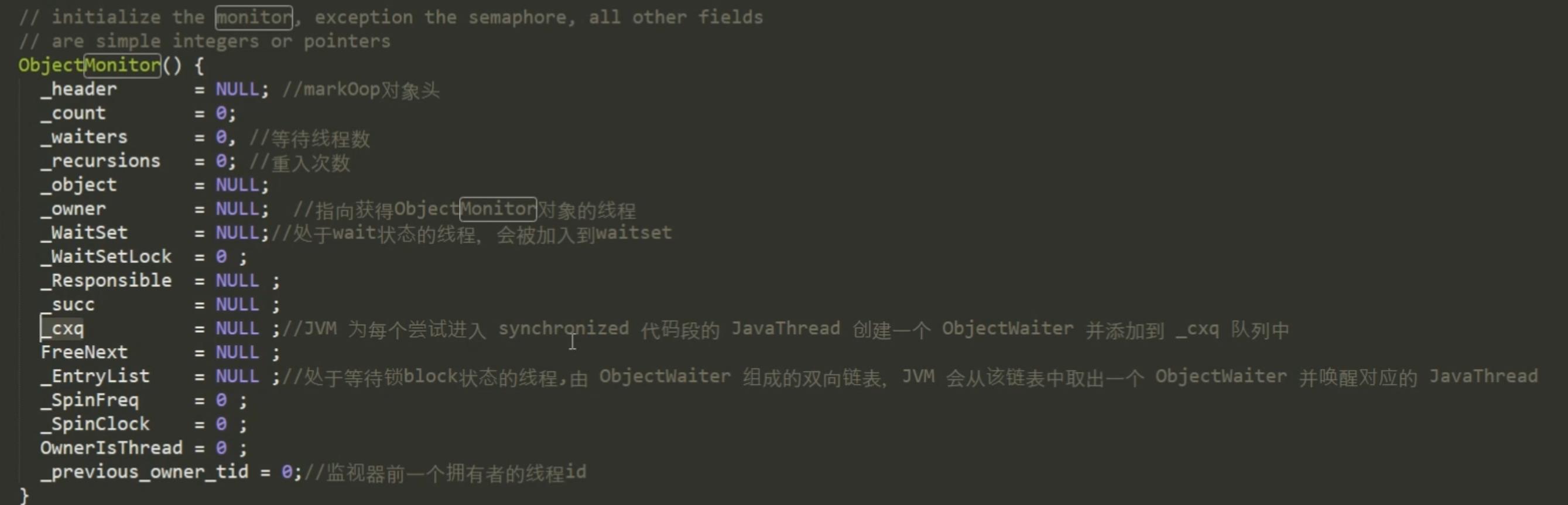
cas: compare and swap ,比对并交换。
这个操作是cpu指令级的功能,可以保证原子性。
这个操作需要三个参数:1.数据存放的地址Addr 2.原来的值A 3.期望改变后的值B。
只有当Addr数据为A的时候才会成功把值更改为B
cas的ABA问题: 描述: 第一个线程取到了变量 x 的值 A,然后巴拉巴拉干别的事,总之就是只拿到了变量 x 的值 A。
这段时间内第二个线程也取到了变量 x 的值 A,然后把变量 x 的值改为 B,然后巴拉巴拉干别的事,
最后又把变量 x 的值变为 A (相当于还原了)。在这之后第一个线程终于进行了变量 x 的操作,但是此时变量 x 的值还是 A,
所以 compareAndSet 操作是成功。 这在某些场景是不允许的
一个不恰当的例子:公司有一笔专款专用的钱100万,在公司真正支出这笔钱之前,公司财务挪用这笔钱借给了自己的某个朋友,
然后这个朋友归还了回来。归还之后公司正常使用了这笔钱,表面上对公司没有任何影响,但挪用公款这个行为是违法不允许的。
如何解决这个问题:增加一个版本号。 Java中的AtomicStampedReference通过版本号解决了这个问题。
在jvm早期中,sync是通过操作系统的互斥量来实现的,这就会涉及到操作系统的用户态和内核态的切换,这是非常消耗系统资源的操作。所以后来引入了轻量级锁,即通过cas+自旋的方式来实现。
那么执行同步代码块的线程是如何进行同步的呢?它们总有一个共同的存储锁信息的地方吧? 是的,那就是对象的mark word(上图ObjectMonitor中的_header字段)。
对象的mark word在什么地方呢?
在对象的对象头里。这里扩展下对象在jvm中的内存结构:

我们重点关注下对象头中的mark word,那么mark word的结构又是怎样的呢?32位jvm中如下:
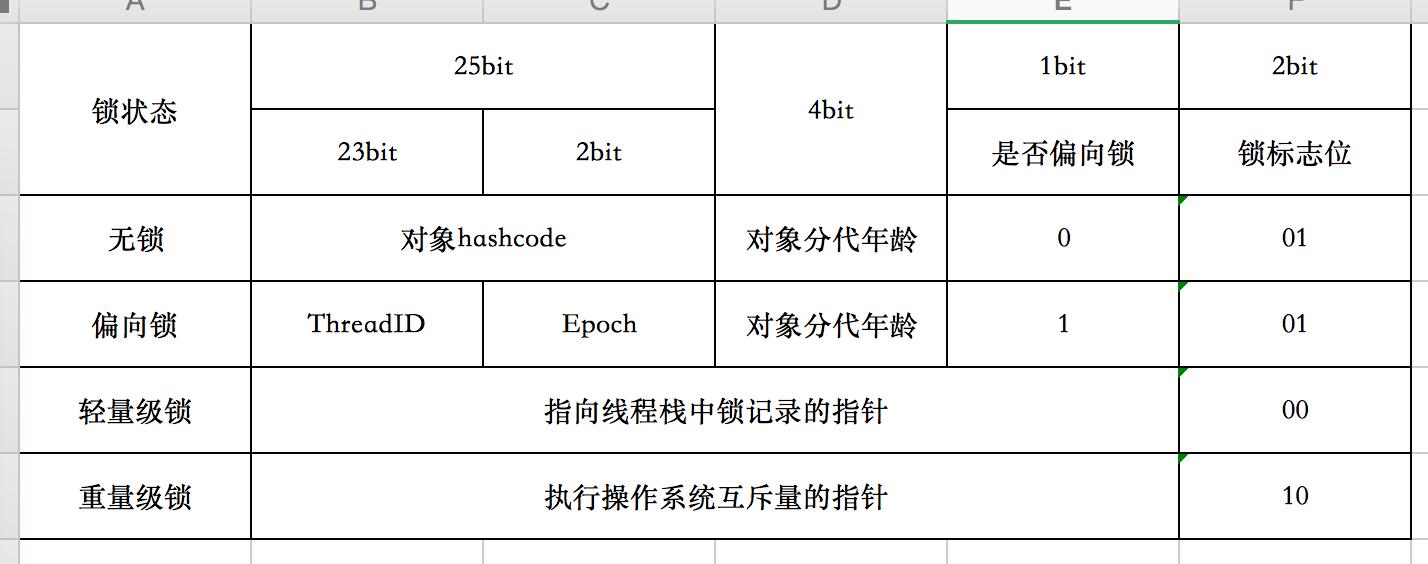
线程就是通过对象的mark word来进行同步的。
在上图可以看到mark word中记录了对象锁的状态,分为无锁、偏向锁、轻量级锁、重量级锁。这几种状态的转变规则为无锁->偏向锁->轻量级锁->重量级锁,这个规则称之为锁的升级。注意:锁只能升级不能降级。但偏向锁可以降级为无锁,其他的不行。
锁的升级过程
见图:
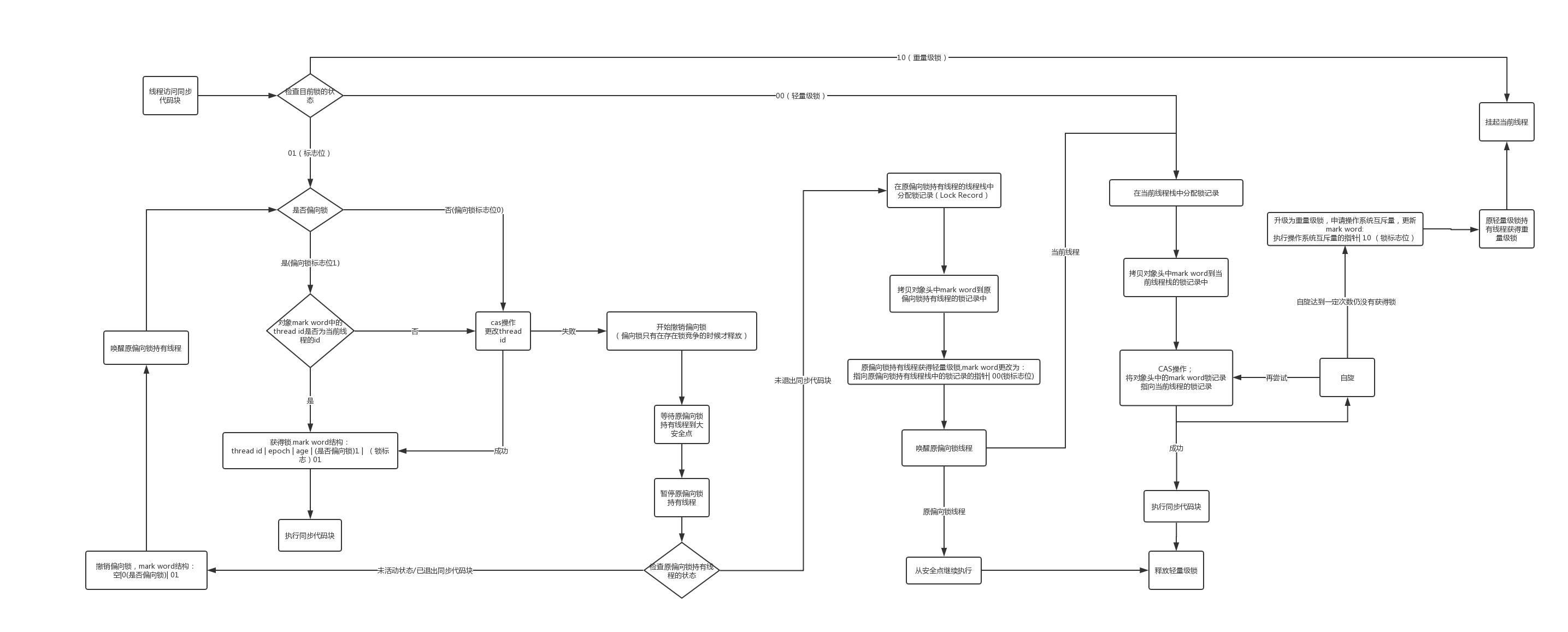
这张图用文字描述清楚感觉太费劲,文字还多,说不定吃力不讨好,所以这个图要慢慢品,细细品,多次品。品的时候建议假设有多个线程在竞争锁。
品的时候有个难点可能是偏向锁的撤销那,偏向锁的撤销是在有锁竞争的情况下才会撤销。为什么呢 ?我们优先要明白偏向锁的设计目的是什么? 因为可能存在这种情况:这个同步代码块只有一个线程在访问。如果没有偏向锁,那么根据上图这个线程会多次进行cas操作,这个显然是没有必要的,于是为了优化就设计了偏向锁。使得在只有一个线程访问同步代码块的时候,只需要比对之前偏向的线程是不是自己,如果是,则获得锁。
扩展
矛盾1
A: 重量级锁中的阻塞(挂起线程/恢复线程): 需要转入内核态中完成,有很大的性能影响。
B: 锁大多数情况都是在很短的时间执行完成。
解决方案: 引入轻量锁(通过自旋来完成锁竞争)。
矛盾2
A: 轻量级锁中的自旋: 占用CPU时间,增加CPU的消耗(因此在多核处理器上优势更明显)。
B: 如果某锁始终是被长期占用,导致自旋如果没有把握好,白白浪费CPU资源。
解决方案: JDK5中引入默认自旋次数为10(用户可以通过-XX:PreBlockSpin进行修改), JDK6中更是引入了自适应自旋(简单来说如果自旋成功概率高,就会允许等待更长的时间(如100次自旋),如果失败率很高,那很有可能就不做自旋,直接升级为重量级锁,实际场景中,HotSpot认为最佳时间应该是一个线程上下文切换的时间,而是否自旋以及自旋次数更是与对CPUs的负载、CPUs是否处于节电模式等息息相关的)。
矛盾3
A: 项目中代码块中可能绝大情况下都是多线程访问。
B: 每次都是先偏向锁然后过渡到轻量锁,而偏向锁能用到的又很少。
解决方案: 可以使用-XX:-UseBiasedLocking=false禁用偏向锁。
矛盾4
A: 代码中JDK原生或其他的工具方法中带有大量的加锁。
B: 实际过程中,很有可能很多加锁是无效的(如局部变量作为锁,由于每次都是新对象新锁,所以没有意义)。
解决方法: 引入锁削除(虚拟机即时编译器(JIT)运行时,依据逃逸分析的数据检测到不可能存在竞争的锁,就自动将该锁消除)。
矛盾5
A: 为了让锁颗粒度更小,或者原生方法中带有锁,很有可能在一个频繁执行(如循环)中对同一对象加锁。
B: 由于在频繁的执行中,反复的加锁和解锁,这种频繁的锁竞争带来很大的性能损耗。
解决方法: 引入锁扩大/锁膨胀(会自动将锁的范围拓展到操作序列(如循环)外, 可以理解为将一些反复的锁合为一个锁放在它们外部)。
扩展
本人自己建了一个jdk8和jdk7的源码阅读仓库,会在阅读源码的过程中添加一些注释。
感兴趣的朋友可以一起来添加对代码的理解。仓库地址:
jdk8:
github: https://github.com/rocky-peng/jdk8-sourcecode-read
gitlab: https://gitlab.com/rocky_peng/jdk8
jdk7:
github: https://github.com/rocky-peng/jdk7-sourcecode-read
gitlab: https://gitlab.com/rocky_peng/jdk7
github和gitlab是完全自动同步的。
jdk8和jdk7的源码来源于jdk8和jdk7的src.zip文件。
如果有不对不足或需要帮助的地方,欢迎添加个人微信:WilsonPeng3
以上是关于Java synchronized实现原理深度剖析的主要内容,如果未能解决你的问题,请参考以下文章