Lucene初探之总体架构
Posted Derrick_gu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene初探之总体架构相关的知识,希望对你有一定的参考价值。
从总体上来说,Lucene的可以被概括为三点:
- 高效、可扩展的全文检索库;
- 基于Java实现;
- 支持对纯文本文件进行索引可搜索;
Lucene的工作流程和架构如下所示:
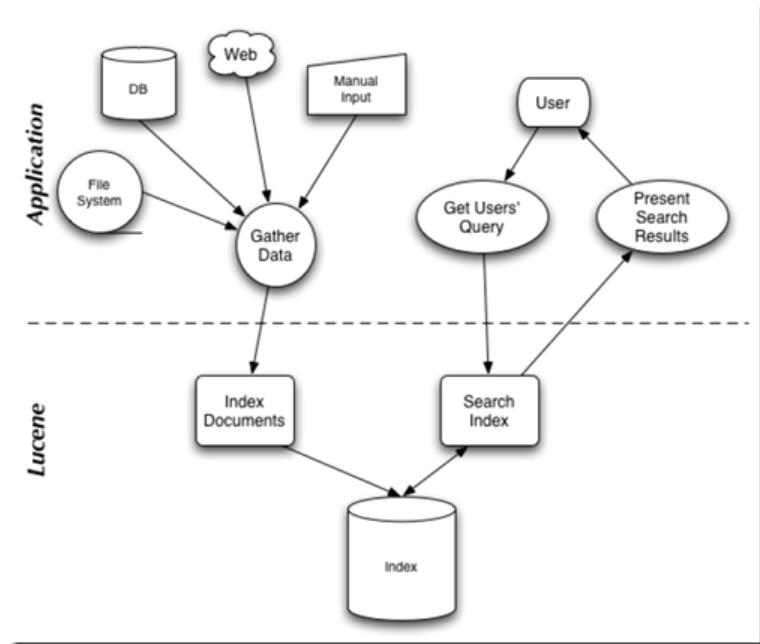
通过该图片,我们可以看出,Lucene的工作流程可以被分为两个部分:索引、搜索。
我们可以将这些过程进行抽象组件化:
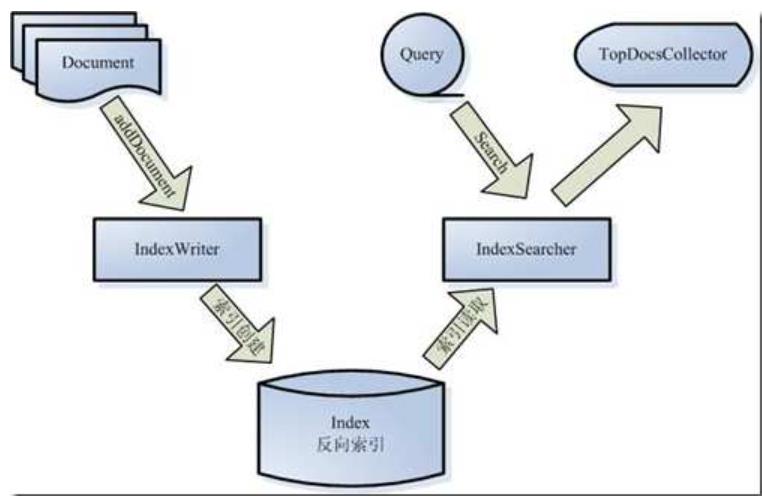
通过上下两个图片的对比,基本上可以直观地了解各个组件的工作:
- Document代表被索引的各个分散的文档;
- IndexWirter将Document写入索引中,这个过程也就是创建索引的过程;
- 当用户有查询请求时,其查询条件为Query,Query被传递给IndexSearch;
- IndexSearch对Index索引进行查询,并得到符合Query条件的文档集合;
- 文档集合在IndexSearch中进一步进行权重和打分计算;
- 按照分值排序后的查询结果被展示给用户;
那么这些不同的组件是如何被使用的呢?
我们来举一个例子,通过这个例子来看一下如何通过对Lucene API的调用来实现索引创建和搜索查询。

通过这个图片,我们可以清晰地看到通过代码去实现索引和搜索的过程主要有以下几个步骤:
索引过程:
- 声明一个Document对象,将要索引的文件内容和文件路径通过add方法添加进入对象中;
- 创建一个IndexWriter,初始化好索引的路径,分词器等信息;
- IndexWriter调用addDocument方法将申明好的Document对象写入到索引中;
- 关闭IndexWriter;
搜索过程:
- 创建一个IndexReader对象,打开索引并读入内存中;
- 创建一个IndexSearcher对象;
- 创建一个Analyzer分词器;
- 创建一个QueryParser对象,对查询域进行词法分析和语法分析并处理;
- 使用相同的QueryParser对查询语句进行分析,行程查询语法数;
- 创建一个TopScoreDocCollector打分器;
- IndexSearcher对象调用search,对索引进行query条件查询并通过打分器打分;
- 将得到的结果返回给用户;
上图是对Lucene的简单demo应用,但是Lucene的真正的实现远不止看起来这么简单,如果我们深入Lucene源码的话,我们会发现Lucene的内部实现包之间的关系非常复杂。
下面是的一些内部模块关系图:


注:上图来自http://www.slideshare.net/Manishkumar1192/search-engine-capabilities-apache-solrlucene
简单地了解了Lucene的整体架构之后,我们就可以正式开始进入Lucene的内部世界去探秘啦!
以上是关于Lucene初探之总体架构的主要内容,如果未能解决你的问题,请参考以下文章