自我实现tcmalloc的项目简化版本
Posted 捕获一只小肚皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自我实现tcmalloc的项目简化版本相关的知识,希望对你有一定的参考价值。
项目介绍
该项目是基于现代多核多线程的开发环境和谷歌项目原型tcmalloc的自我实现的简化版本,相比于本身就比较优秀的malloc来说,能够略胜一筹,因为其考虑了 性能,多线程环境,锁竞争和内存碎片的问题,主要利用了池化思想来管理内存分配,对于每个线程,都有自己的私有缓存池,内部包含若干个不同大小的内存块。
对于一些小容量的内存申请,可以使用线程的私有缓存,私有缓存不足或大容量内存申请时再从全局缓存中进行申请。在线程内分配时不需要加锁,因此在多线程的情况下可以大大提高分配效率。
该项目主要由以下3个部分构成:
-
thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,之所以不加锁是采用了TLS线程本地存储技术,这也就是这个并发线程池高效的地方。
-
central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对
象。central cache合适的时机回收thread cache中的对象,避免一个线程占用了太多的内存,而
其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存
在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有thread cache的
没有内存对象时才会找central cache,所以这里竞争不会很激烈。 -
page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分
配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小
的小块内存,分配给central cache。当一个span的几个跨度页的对象都回收以后,page cache
会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片
的问题
总体结构
该项目的结构分为三层,由下到上分别是 ThreadCache–>CentralCache–>PageCache,内存的申请和释放顺序同上,数量上呈现为多—>单—>单
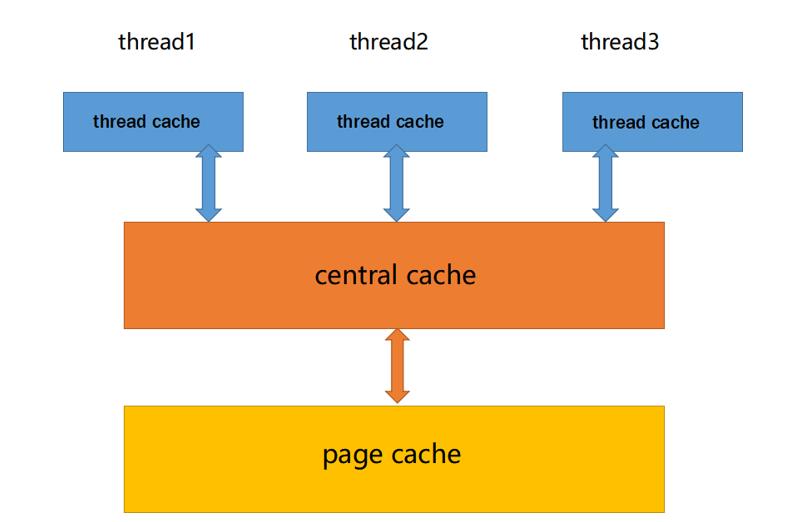
threadcache结构
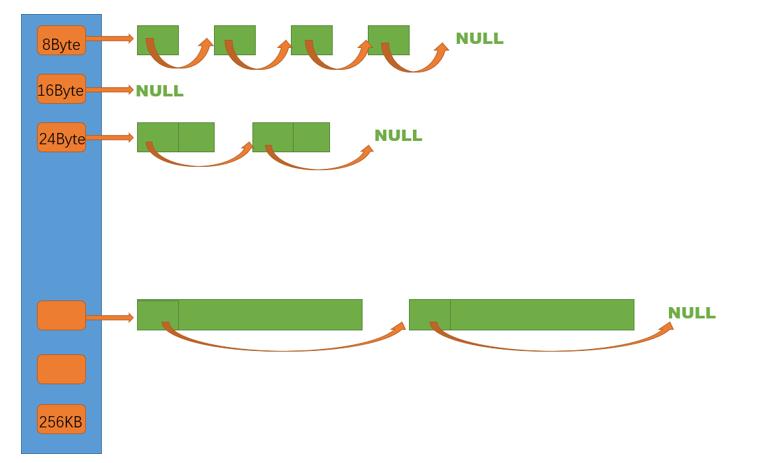
class ThreadCache
public:
//从ThreaCache申请和释放内存对象
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
private:
//从CentralCache申请内存对象
void* FetchFromCentralCache(size_t index, size_t alignSizeBlock);
//批量归还一部分内存给CentralCache
void ListTooLong(FreeList& list, size_t size);
private: //数组形式哈希桶
FreeList _freelist[NFREELIST]; //NFREELIST=208
;
ThreadCache结构是一个208数量的哈希桶,桶中装的是将反馈给某线程固定byte大小的内存块自由链表.
而这个固定大小是按照一定的字节对齐算出来的,对齐规则如下:
线程申请字节范围: 对齐数: 桶索引范围: 桶挂的内存块大小:
[1,128] 8 bytes align freelist[0,15] 8,16,24,32...(8 ↑)
[128+1,1024] 16 bytes align freelist[16,71] 144,160,176..(16 ↑)
[1024+1,8*1024] 128 bytes align freelist[72,127] 1152,1280....(128 ↑)
[8*1024+1,64*1024] 1024 bytes align freelist[128,183] 9216,10240...(1024 ↑)
[64*1024+1,256*1024] 8*1024 bytes align freelist[184,207] 73728,81920..(8*1024↑)
解释:
线程A通过调用该ThreadCache进行申请一个13字节的内存块,该大小在范围[1,128]中,由于对齐数是8,所以ThreadCache应该反馈一个16字节的内存块给线程A,而16字节对应的桶索引是1;
线程B通过调用该ThreadCache进行申请了一个1026字节的内存块,改大小在范围[1024+1,8*1024]中,由于对齐数是128,所以ThreadCache应该反馈一个1152字节的内存块给线程B,而1152字节对应的桶索引是72;
内存申请逻辑
检测线程申请内存大小,根据对齐数换算出需要反馈的字节大小和桶索引,然后检查该索引下的内存块链表上是否挂载了切割好的内存,如果有直接取出交给线程,如果没有,则向CentralCache申请需求 (该向动作也是一个ThreadCache下的模块);
内存释放逻辑
检测线程释放内存大小,根据对齐数换算出该内存块在哪一个索引之下,然后挂载到该索引下的链表,此时并没有完毕,这个时候再看该链表下挂载的内存数量是否比较多和空闲,如果是,则取出一批内存块返还给CentralCache(判断内存数量是否空闲也是一个模块);
CentralCache结构
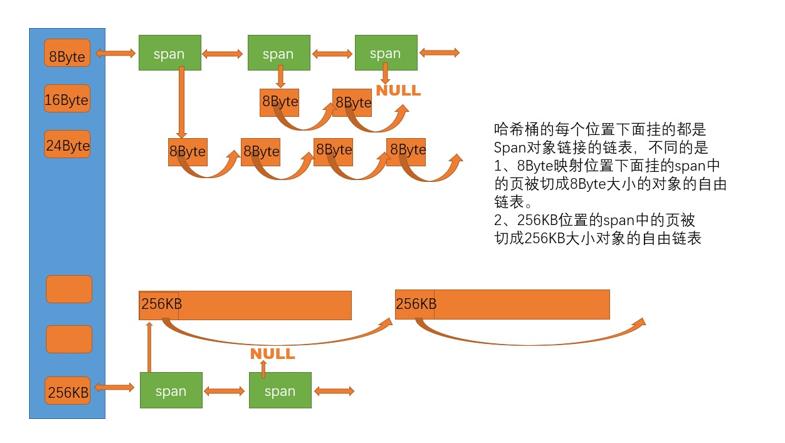
class CentralCache
public:
static CentralCache* GetInstance() //单例模式
return &_ccinstance;
//向pagecache要一个非空span
Span* GetNEmptySpan(SpanList& sl, size_t alignSizeBlock);
//拿出batch数量的alignSizeBlock大小的内存块
size_t FetchRangeObj(void*& head, void*& tail, size_t batch, size_t alignSizeBlock);
//把从ThreadCache还回来的批量内存归位到相应span;
void ReleaseListToSpans(void* start, size_t byte_size);
private:
CentralCache()
CentralCache(const CentralCache& cc) = delete;
CentralCache& operator=(const CentralCache& cc) = delete;
private:
SpanList _spanlist[NFREELIST]; //数组形式哈希桶
static CentralCache _ccinstance;
;
CentralCache也是一个208数量的哈希桶,和ThreadCache的桶结构相对应,但不同的是CentralCache桶中挂载的是一个以页为单位的span的带头双向链表,然后span把页内存切割成了该索引对应大小的内存块自由链表,挂载在该span内部.
第二层采用带头循环双向链表原因是,可以只在O(1)复杂度情况下,取出和插入span.而第一层仅仅用单链表是因为线程只需要一个可以使用的内存,对于内存块之间的顺序和定位后修改无要求,那么仅仅通过头删头插就可以满足;
span的结构
// Span管理一个具有跨度,以页为单位且连续多个页的结构
struct Span
PAGE_ID _pageId = 0; // 大块内存起始页的页号ID
size_t _n = 0; // 页的数量
Span* _next = nullptr; // 双向链表的结构
Span* _prev = nullptr;
size_t _objSize = 0; // 切好的小对象的大小
size_t _useCount = 0; // 切好小块内存后,被分配给thread_cache的计数
void* _freeList = nullptr; // 切好的小块内存所挂载的自由链表
bool _isUse = false; // 是否正在被使用
;
内存申请逻辑
当收到ThreadCache的批量内存块请求后,检测这些内存块大小,根据该大小算出索引,然后在该索引下查找挂载了内存块的span,再取出批量内存块反馈给ThreadCache,倘若该索引下没有非空span,就向PageCache索要;
内存释放逻辑
当收到ThreadCache的批量内存块请求后,检测这些内存块大小,根据该大小算出索引,然后在该索引下根据pageid和span的映射关系,找出这些内存块原本所归属的span,再把这些内存放进该span,然后检测span下的_useCount的值是否为0,倘若为0,则把该span提交给PageCache,让PageCache进行页合并
PageCache结构
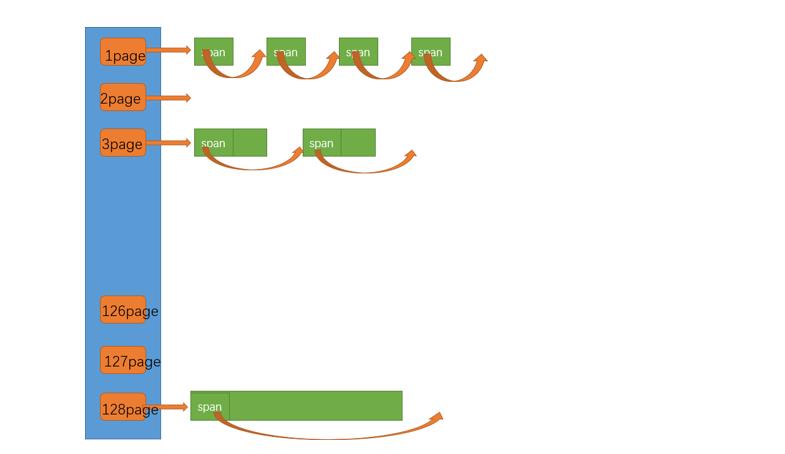
class PageCache
public:
static PageCache* GetInstance() //单例模式
return &_pcinstance;
//查找pageid 和 span的映射关系;
Span* MapObjectToSpan(void* obj);
// 对从central归还回来的span,进行前后合并
void ReleaseSpanToPageCache(Span* span);
Span* NewSpan(size_t n_page); //获得一个page页的page
void LOCK();
void UNLOCK();
private:
PageCache() ;
PageCache(const PageCache& pc) = delete;
PageCache& operator=(const PageCache& pc) = delete;
private:
SpanList _spanlist[NPAGE]; //数组形式哈希桶
std::mutex _mutex; //整体锁
static PageCache _pcinstance;
std::unordered_map<PAGE_ID, Span*> _idSpanMap; //用来存储页id和span的映射关系;
;
PageCache是一个128数量的哈希桶,并且每个索引代表的内存大小不再是按照对齐数对齐的字节大小,而是以页为单位的page,索引下挂载的仍然是带头双向循环链表和span,但span里面只有索引数量单位的page,这里不进行对页的切割;
内存申请逻辑
接收CentralCache申请的n个page请求,然后查找索引n下是否有span,如果有,则反馈给CentralCache,如果该索引下没有,则依次向后查找,直到找到为止;若所有桶都没找到span,则向系统申请以页为单位的128页的span;有了span后就对该span进行页切割,切割成n页和span->num -n页的span,然后把前者提交给CentralCache,后者插入索引为span->num-n的桶内;
内存释放逻辑
接收CentralCache返还的span,然后根据该span的id,以及前后id和映射关系,查护被切割出去的页span,如果它们未被使用,则合并为更大的span,重新归位PageCache;
两个链表结构
单链表
针对ThreadCache的单链表结构,需要满足针对单一内存块的增删和针对批量内存块的增删
class FreeList
public:
//针对单一内存块
void Push(void* obj);
void* Pop();
//针对批量内存块
void PushRange(void* head, void* tail,size_t size); //放size个内存块,head和tail首尾接收
void PopRange(void*& head, void*& tail, size_t size);
bool Empty();
size_t& MAXSIZE(); //慢反馈算法需要用到的一个比较值
size_t Size(); //返回链表所挂载结点数量
private:
void* _freelist = nullptr;
size_t _max_size = 1;
size_t _size = 0; //记录链表上挂载的记录结点;
;
双链表
针对CentralCache和PageCache的带头双向循环链表,由于这两层结构都是面向全局的,将会形成线程竞争问题,那么该链表除了正常的增删改查之外还需要就需要上锁和解锁;
class SpanList
public:
SpanList();
Span* Begin();
Span* End();
void PushFront(Span* NewSpan);
Span* PopFront() ;
void Insert(Span* pos, Span* NewSpan);
void Erase(Span* pos);
void LOCK();
void UNLOCK();
bool Empty();
private:
Span* _head;
std::mutex _mutex;
;
- 注意事项:
这个是链表锁,也就是桶锁,是CentralCache中的每个索引都会拥有并使用的,PageCache虽然也是该链表结构,但是并不会使用桶锁,而是在PageCache里面封装一个整体锁;
- 原因:
对于CentralCache来说,不同线程访问的桶大概率是不同位置的,而且只单一访问某一个桶不会影响其他桶,对于这种情况来说使用桶锁是比较合适的,如果使用整体锁把CentralCache锁住,将会造成过多线程等待,以至于效率大大降低
对于PageCache来说,情况就不一样了,每个线程可能进行范围索引访问,并且多个线程访问的桶就可能大概率重复,如果给PageCache使用桶锁,就会频繁的加锁解锁,造成效率降低,相反,如果使用整体锁,每个线程就只需要加解一次锁;
重要模块实现
清楚了总体结构以后,就需要针对性的根据功能进行实现,这里根据申请和释放逻辑画了一个结构图:
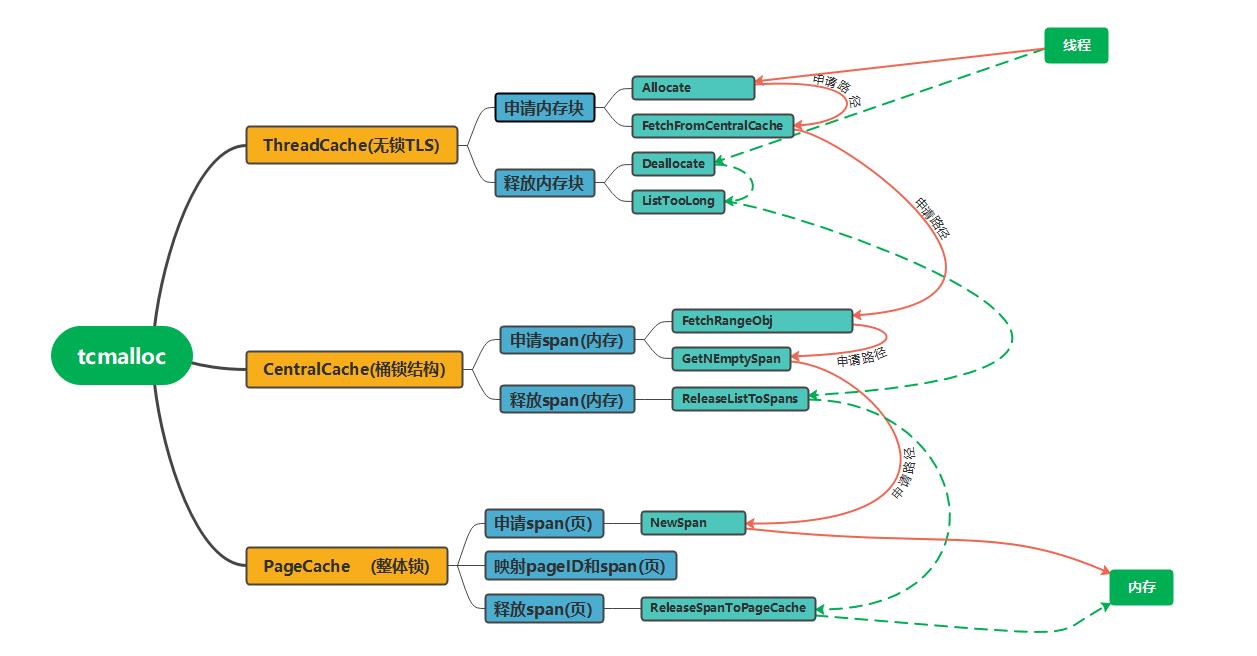
内存申请路径
ThreadCache下的allocate
这是一个对外线程的接口,接收其申请的字节,然后计算相关索引和对齐的内存块大小,根据索引查找是否有内存块
void* ThreadCache::Allocate(size_t bytes)
assert(bytes <= MAX_BYTES);
size_t alignSizeBlock = SizeClass::RoundUp(bytes);
size_t index = SizeClass::Index(bytes);
//如果桶空,则从centralcache中获取,否则拿出一个
if (!_freelist[index].Empty())
return _freelist[index].Pop();
else
return FetchFromCentralCache(index, alignSizeBlock);
假设我们在该索引下没找到内存块,那么就需要向CentralCache进行申请了,而在申请之前,ThreadCache有一些细节处理,比如我们每次向CentralCache申请时,都只申请一块吗,如果申请多块应该怎么控制呢?
答: 每次申请并不是只申请一块,因为这样子明显就失去了池化技术的精髓,因此每次申请的都是多块,如果申请的是大内存,则给少一点,如果申请的是小内存,则给多一点思路,然后在外面根据一个值,进行慢增长;
大内存多给数量,小内存少给数量
static size_t NumMoveSizeCentral(size_t bytes)
assert(bytes);
size_t batch = MAX_BYTES / bytes;
if (batch < 2)
batch = 2;
else if (batch > 512)
batch = 512;
return batch;
ThreadCache下的FetchFromCentralCache
上面提到了大给少,小给多,那么当多个线程都申请到小内存时候,按照这个多来看,ThreadCache总计申请到的内存将是会非常庞大的,并且后续也可能使用不完,这个多和少都应该有个阈值(maxsize),这就是慢反馈调解算法(下面的7-11行)
void* ThreadCache::FetchFromCentralCache(size_t index, size_t alignSizeBlock)
//慢开始反馈调解算法
/*
最开始不会一次性向central要太多,可能使用不完,numMoveSize是MAXSIZE的一个界限
MAXSIZE会逐渐向NumMoveSize趋近
*/
size_t batch = min(_freelist[index].MAXSIZE(), SizeClass::NumMoveSizeCentral(alignSizeBlock));
//慢增长
if (batch == _freelist[index].MAXSIZE())
_freelist[index].MAXSIZE() += 1;
void* head = nullptr;void* tail = nullptr;
size_t ActualNum = CentralCache::GetInstance()->FetchRangeObj(head, tail, batch, alignSizeBlock);
assert(ActualNum > 0); //检验实际获取多少个内存块
if (ActualNum == 1) //如果只有一个,链表首尾应该相等
assert(head == tail);
return head;
//有多个内存块时候,把除了head外,其余内存块放进freelist
_freelist[index].PushRange(NextObj(head), tail,ActualNum-1);
return head;
CentralCache下的FetchRangeObj
该函数的作用是在目标索引下,提取一个非空span,通过输出型参数,把span的自由链表上挂载的内存块输出给ThreadCache一部分,并返回所真实反馈给ThreadCache的内存块数量;由于是在第二层结构中操纵某索引下的span以及其下的内存块,所以需要上锁;
执行逻辑:
取非空span,然后取该span自由链表下挂载的批量内存块,取出多少,span中的_use_count就进行记录多少(
++)
//申请batch数量的大小为alignSizeBlock的内存块,这些内存块的头为head,尾为tail
size_t CentralCache::FetchRangeObj(void*& head, void*& tail, size_t batch, size_t alignSizeBlock)
size_t index = SizeClass::Index(alignSizeBlock);
_spanlist[index].LOCK(); //给桶上锁
Span* span = GetNEmptySpan(_spanlist[index], alignSizeBlock);
assert(span);
assert(span->_freelist);
//初始化head 和 tail
head = tail = span->_freelist;
//从span中获取目标数量内存块,如果不够有多少拿取多少
//第二个判断条件是防止请求数量越界
size_t actualNum = 1;
for (size_t i = 0; (i < (batch - 1)) && NextObj(tail); i++)
tail = NextObj(tail);
actualNum++;
span->_freelist = NextObj(tail);
span->_use_count += actualNum; //内存块拿出去,usecount就++,还回来就--
NextObj(tail) = nullptr; //截取range(head,tail)
_spanlist[index].UNLOCK();
return actualNum;
CentralCache下的GetNEmptySpan
该函数的作用是返回某桶中的一个非空span,倘若找不到,就向PageCache申请一个span;
执行逻辑:
首先查找CentralCache下该桶是否拥有非空span,如果没有就向PageCache申请一个,由于申请的span是整页的大内存,所以我们需要对页进行切割成对齐数所对齐的大小内存块,挂载在span的自由链表上,然后返回span.
Span* CentralCache::GetNEmptySpan(SpanList& sl, size_t alignSizeBlock)
//查找非空位span
Span* it = sl.Begin();
while (it != sl.End())
if (it->_freelist != nullptr)
return it;
it = it->_next;
//这里可以先把桶锁释放了,为其他thread归还内存让位置;
sl.UNLOCK();
PageCache::GetInstance()->LOCK();
//如果找不到,就去Page找更大的span,然后插入central桶
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(alignSizeBlock));
span->_isUse = true;
PageCache::GetInstance()->UNLOCK();
//获取到了span后不着急给桶锁上锁,因为后面是在切分span,并不会和其他线程竞争
//把page span中的页连续块切分成自由链表,并且计算页内存的始末地址和叶内存大小
char* begin = (char*)(span->_page_id << PAGE_SHIFT); //所有页内存的始地址
size_t size = span->_page_num << PAGE_SHIFT; //总体页的大小
char* end = begin + size; //所有页内存的始地址
//先切下一块做头,方便尾插
void* tail = span->_freelist = begin;
begin += alignSizeBlock;
//切分
while (begin < end)
NextObj(tail) = begin;
tail = begin;
begin += alignSizeBlock;
//这里就需要重新上桶锁了,因为插入新span会造成竞争
sl.LOCK();
sl.PushFront(span);
return span;
对页内存进行切割原理:
因为span具有page_id 和 page_num,以及每页的大小,所以:
page_id * 页大小就是span的所有页的起始地址;
page_num * 页大小就是span所拥有的所有页大小的总和;
起始地址 + 总和就是span的所有也的末尾地址的下一个地址;
有了内存的起始地址,那么用一个循环对地址进行对齐数大小的整数加减,就可以切割内存了;
例如,假设一页的大小为1KB,那么page_id和地址与数量之间的关系就如下图:
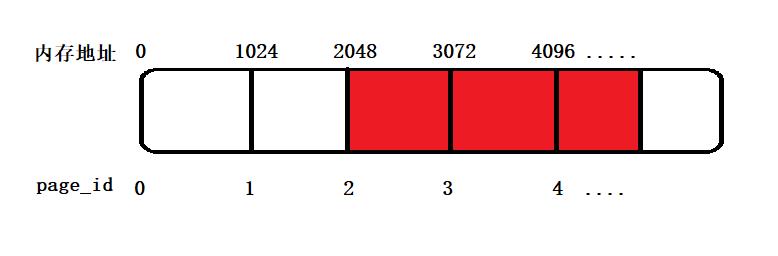
假设我的span只有中间阴影部分的叶内存,那么我的span结构中重要数据应该如下:
struct Span
PAGE_ID _pageId = 2; // 大块内存起始页的页号ID
size_t _n = 3; // 页的数量
;
很明显,page_num * 1024(页大小) = 3072,也就是span所拥有的内存大小;page_num*1024 = 2048,也就是span拥有的页的起始地址;同理也可以计算出末尾地址的下一位
PageCache下的Newspan
该函数利用了递归原理,因此像普通情况一样进行加解锁,就会造成死锁.解决这种情况的办法有两种:
第一种是在调用该函数的函数里面对该函数进行加解锁,类似下面结构:
void func1()
lock();
func2(); //func2是递归函数
unlokc();
第二种是利用C++里面的递归锁recursive_mutex,它会自我解决死锁问题;
本函数采用了第一种用法,也就是在CentralCache中的GetNEmptySpan函数里面对本函数进行上锁;
该函数的作用就是提交给CentralCache一个n_page页的span,如果n_page页的span没有,就向后查找更大的,如果找到了,就把大page页进行分割成n_page页的span和剩余page的span,如果后面都没有,就直接向系统申请一个128page的span,然后再切割成n_page页的span和剩余page的span,最后提交n_page的span给CentralCache,把剩余page的span挂入PageCache;
而在这个函数里面还有一个工作就是对n_page的span中的所有page_id和该span进行映射,以及对剩余page的span中的首尾page_id和span进行映射;此映射在归还内存时会起到提高效率的作用
//从span中切割页给CentralCache
Span* PageCache::NewSpan(size_t n_page)
assert(n_page > 0 && n_page < NPAGE);
//检查第n_page个桶是否为空,不为空则拿出来
if (!_spanlist[n_page].Empty())
Span* span = _spanlist[n_page].PopFront();
for (int i = 0; i < span->_page_num; i++)
_idSpanMap[span->_page_id + i] = span;
return span;
//为空,则检查后面的桶是否有span,并进行切分
for (int i = n_page; i < NPAGE; i++)
if (!_spanlist[i].Empty())
Span* n_p_span = _spanlist[i].PopFront();
Span* s_p_span = new Span; //存储切割后的目的大小page
//切割成目的大小page给s_p_span;
s_p_span->_page_id = n_p_span->_page_id;
s_p_span->_page_num = n_page;
//调整好剩余page
n_p_span->_page_id = s_p_span->_page_id + s_p_span->_page_num;
n_p_span->_page_num -= s_p_span->_page_num;
//把剩余的page挂入桶
_spanlist[n_p_span->_page_num].PushFront(n_p_span);
//对于切割出去给CentralCache的页,需要保留每个pageID,
//因为都可能用到(CentralCache层面)
for (int i = 0; i < s_p_span->_page_num; i++)
_idSpanMap[s_p_span->_page_id + i] = s_p_span;
//而对于切割剩下的span,只需要保留首尾pageid,
//因为在PageCache层面,只可能用到首尾
//(span合并,只需要看两边的pageid,这两个id只可能存在于span首尾)
_idSpanMap[n_p_span->_page_id] = n_p_span;
_idSpanMap[n_p_span->_page_num-1] = n_p_span;
//注意需要剪去一个1,才是最后一个id
return s_p_span;
//如果往后面都没找到,就向系统申请一个128页的span;
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGE-1);
bigSpan->_page_id = ((PAGE_ID)ptr) >> PAGE_SHIFT; //转换为大叶内存的ID
bigSpan->_page_num = NPAGE - 1;
_spanlist[bigSpan->_page_num].PushFront(bigSpan);
//申请到的内存,挂入桶里面,然后再次切分页内存(递归调用一次)
return NewSpan(n_page);
内存归还路径
ThreadCache下的Deallocate
接收线程发给的内存块,然后重新插入ThreadCache里面,插入后检查当前挂载数量是否大于等于满反馈那个阈值,如果是则返回阈值数量的内存块给CentralCache;
void ThreadCache::Deallocate(void* ptr, size_t bytes)
assert(ptr);
assert(bytes <= MAX_BYTES);
//计算出对应的桶位置,然后还原("释放")
size_t index = SizeClass::Index(bytes);
_freelist[index].Push(ptr);
//当太多内存需要还时(即目前挂载的数量大于等于申请的批数量),
//就还一部分给centralcache
if (_freelist[index].Size() >= _freelist[index].MAXSIZE())
ListTooLong(_freelist[index],bytes);
ThreadCache下的ListTooLong
用来取出阈值数量的内存块,然后提交给CentralCache;
void ThreadCache::ListTooLong(FreeList& list, size_t size)
void* start = nullptr;
void* end = nullptr;
//当挂载数量大于申请批量时候,就归还申请批量数量结点
list.PopRange(start,end,list.MAXSIZE());
//归还给CentralCache;
CentralCache::GetInstance()->ReleaseListToSpans(start,size);
CentralCache下的ReleaseListToSpans
接收ThreadCache的批量内存,然后把每个内存块归位到对应的span
//之所以名字叫spans,而不是span,因为还回来的内存卡不一定来自同一个span
void CentralCache::ReleaseListToSpans(void* start, size_t byte_size)
size_t index = SizeClass::Index(byte_size);
_spanlist[index].LOCK();
while (start)
void* next = NextObj(start);
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
NextObj(start) = span->_freelist;
span->_freelist = start; //把内存小块归还给span
span->_use_count--;
if (span->_use_count == 0) //说明span的所有分割出去内存都收回
//说明该span可以归还给pagecache;
_spanlist[index].Erase(span);
//把span从CentralCache取出,然后把span的除了id和num之外的数据置空
span->_freelist = nullptr;
span->_next = span->_prev = nullptr;
//然后交给PageCache看是否可以合并页
//在把span提交给pagecache时候,可以把自己桶锁解开,让出自己的资源;
_spanlist[index].UNLOCK();
//再调用PageCache时候,记得上整体锁;
PageCache::GetInstance()->LOCK();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->UNLOCK();
_spanlist[index].LOCK();
start = next;
_spanlist[index].UNLOCK();
PageCache下的ReleaseSpanToPageCache
接收CentralCache下的span,然后检测span前后的page_id的span,再进行页合并
void PageCache::ReleaseSpanToPageCache(Span* span)
//对span前后的页,尝试进行合并,然后缓解内碎片
while (true)
PAGE_ID prev_id = span->_page_id - 1;
auto ret = _idSpanMap.find(prev_id);
//再向前合并时候,如果查找不到id对于span,则停止合并
if (ret == _idSpanMap.end()) break;
//或者前面span正在使用,则停止合并
Span* prevspan = ret->second;
if (prevspan->_isUse == true) break;
//或者如果向前合并后page_num大于128,则停止合并
//合并大于128的可能情况:两个128page的span刚好是连续的,
//但是合并的起点并不是一个span的首尾ID)
if(prevspan->_page_num + span->_page_num >= NPAGE) break;
//合并
span->_page_id = prevspan->_page_id;
span->_page_num += prevspan->_page_num;
//把前面的span从PageCache取出并释放;
_spanlist[span->_page_num].Erase(prevspan);
delete prevspan;
while (true)
PAGE_ID next_id = span->_page_id + span->_page_num;
auto ret = _idSpanMap.find(next_id);
if (ret == _idSpanMap.end()) break;
Span* nextspan = ret->second;
if (nextspan->_isUse == true) break;
if (nextspan->_page_num + span->_page_num >= NPAGE) break;
//合并
span->_page_id = nextspan->_page_id;
span->_page_num += nextspan->_page_num;
//把前面的span从PageCache取出并释放;
_spanlist[span->_page_num].Erase(nextspan);
delete nextspan;
_spanlist[span->_page_num].PushFront(span);
//调整span使用状态为FALSE
span->_isUse = false;
//映射首尾ID
_idSpanMap[span->_page_id] = span;
_idSpanMap[span->_page_id + span->_page_num - 1] = span;
项目总结
博主这里仅仅只是取出该项目的重要结构进行了讲解,对于一些细节优化,这里并没有阐述,例如: 线程申请的内存大小大于256KB时候,便直接向PageCache申请; 利用基数树优化哈希表结构减少锁竞争的开销;利用定长内存池代替new和delete;
想比较细致的观看该项目,可以点击项目源码
以上是关于自我实现tcmalloc的项目简化版本的主要内容,如果未能解决你的问题,请参考以下文章