阿里云redis集群数据集中在db0未分散到所有节点问题解决
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云redis集群数据集中在db0未分散到所有节点问题解决相关的知识,希望对你有一定的参考价值。
参考技术A 背景介绍:我们系统使用的缓存服务是付费版的阿里云的redis集群服务,配置是4核,16G。redis的集群结构如下:分为四个节点DB0,DB1,DB2,DB3之前的存储方案是存储的商品促销数据,结构是:
KEY FIELD VALUE来存储。其中KEY是一个固定的字符串"zy:prom:wx",FIELD则是商品sku,VALUE是商品促销的具体信息。这种方式导致我们存入缓存服务器的数据一直集中在DB0节点上,在访问量过大时,该节点会在短时间内受到到的访问压力很大,DB0的cpu瞬间达到100%以上,造成服务卡顿甚至不可用。而相比之下DB1,DB2,DB3的节点cpu压力却很小,可以忽略不计。这是为什么?最后询问了阿里的技术,他们说我们的数据存储的方法有误,具体是我们的key设置有误。与阿里的技术对话如下:
所以我们后来改造了方案把key的组成变程了"prom:wx:sku",这样key就会根据sku的不同而不同,增大了key的离散度,这样key通过hash算出来的值,就会不同,使得所有的数据不再存放到同一台节点上,完美解决问题。
修改后的存储分布情况如下图:DB0、DB1、DB2、DB3四个节点数据均匀分布。
对修改前后两天同一时间区间的缓存服务器的cpu压力情况对比:
Redis安装(单机及各类集群,阿里云)
Redis安装(单机及各类集群,阿里云)
前言
上周,我朋友突然悄悄咪咪地指着手机上的一篇博客说,这是你的博客吧。我看了一眼,是之前发布的《Rabbit安装(单机及集群,阿里云》。我朋友很哈皮地告诉我,我的博客被某个Java平台进行了微信推送。看到许多人阅读,并认同了我的博客,心理还是很开心的。
好了,话题收回来。这次就Redis在实际服务器中的各种安装,进行详细描述。
另外由于内容较多,并不一定能涵盖各个方面,万望见谅。如果存在什么问题,或者有什么需要添加的,请私信或@我。
最后,由于打马赛克太麻烦了。并且我之后可能会开放安装视频,所以有的IP什么的,我并不方便打马赛克。但是希望你们不要做坏事儿哈。
Redis安装简述
简介
Redis是一款缓存中间件,其安装分为:
- 单机
- 主从赋值
- 哨兵机制
- 哨兵集群
- 分片集群
应用
redis通过解压包中的src下的各类程序,直接应用。
常用的程序有:
- redis-server
- redis-cli
- redis-sentinel
安装环境
平台:阿里云
ECS实例规格:ecs.t5-lc1m1.small (性能约束实例)
CPU:单核
内存:1G
硬盘:40G
操作系统:CentOS7.6(已经测试CentOS7.3会出现问题)
购买ECS,用于平时测试,学习的话,四点建议:
- 只需要购买共享型,比较适合平时用得不多,测试也负担不大,偶尔压测。
- 如果资金允许,直接购买将长时间,比较划算。日后需要也可以提升配置。
- 阿里云部分地区有优惠(目前有两个地区)
- 如果想要尝试集群等操作,并且打算购买多个服务器,请一定要在同一个内网内,这样才可以利用内网通信。
防火墙
云服务器的防火墙,我依旧将其分为云平台的安全策略与服务器本身的防火墙服务。
而阿里云的官方CentOS7.6镜像,是不开启firewall。可以通过systemctl status firewalld来进行确认。
而云平台的安全策略是需要在安全组内进行设置的。这个部分网上很多资料,就不在此赘述了。
而RabbitMQ需要开放6379端口(默认的redis通信接口,可以在配置文件中修改),26380(本次开放给哨兵的端口)两个端口。
单机安装
下载程序包
在阿里云的Linux上可以通过以下方式,进行下载。
wget http://download.redis.io/releases/redis-5.0.3.tar.gz同样因为XXX缘故,速度可能会比较感人,这里同样提供网盘下载。
redis-5.0.3:提取码:6loe
创建文件夹
mkdir /developer/redis/conf
mkdir /developer/redis/data
mkdir /developer/redis/logs解压文件
(说明一下,我的压缩包是放在/developer目录下的。如果不在此目录,请指定解压目录)
tar -zxvf redis-5.0.3.tar.gz无配置(默认配置)启动
为了避免由于目录,造成理解错误,这里采用绝对路径。
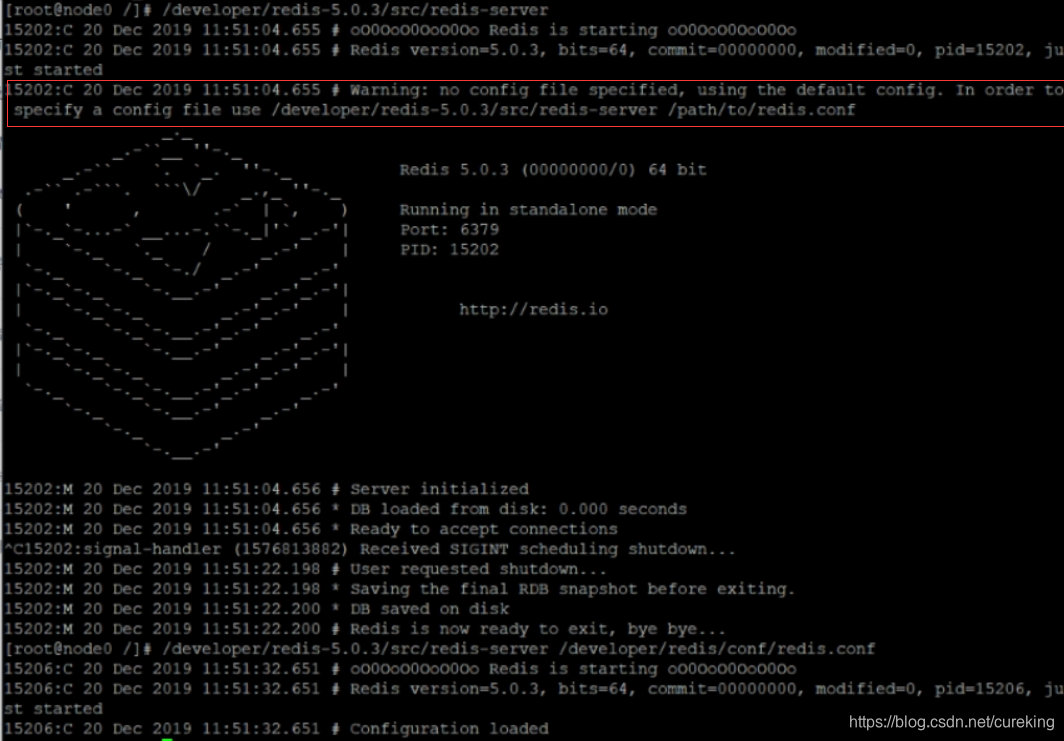
/developer/redis-5.0.3/src/redis-server成功启动后,会看到如下画面:
配置文件
为了避免”裸奔“,这里还是配置一下配置文件。
新建配置文件
touch /developer/redis/conf/redis.conf配置文件
# 配置文件进行了精简,完整配置可自行和官方提供的完整conf文件进行对照。端口号自行对应修改
#后台启动的意思
daemonize yes
#端口号(如果同一台服务器上启动多个redis实例,注意要修改为不同的端口)
port 6379
# IP绑定,redis不建议对公网开放,直接绑定0.0.0.0没毛病。也可以直接注释
#bind 0.0.0.0
# 这个文件会自动生成(如果同一台服务器上启动,注意要修改为不同的端口)。多台服务器,直接默认即可
#pidfile /var/run/redis_6379.pid
# 关闭保护模式(默认是开启的。开启后,只能通过配置bind ip或者设置访问密码,才可以访问)
protected-mode no
配置文件启动
/developer/redis-5.0.3/src/redis-server /developer/redis/conf/redis.conf这样启动后,会出现以下页面:

单机启动的各类问题
单机启动时,会看到下面图片中标出的三个问题:
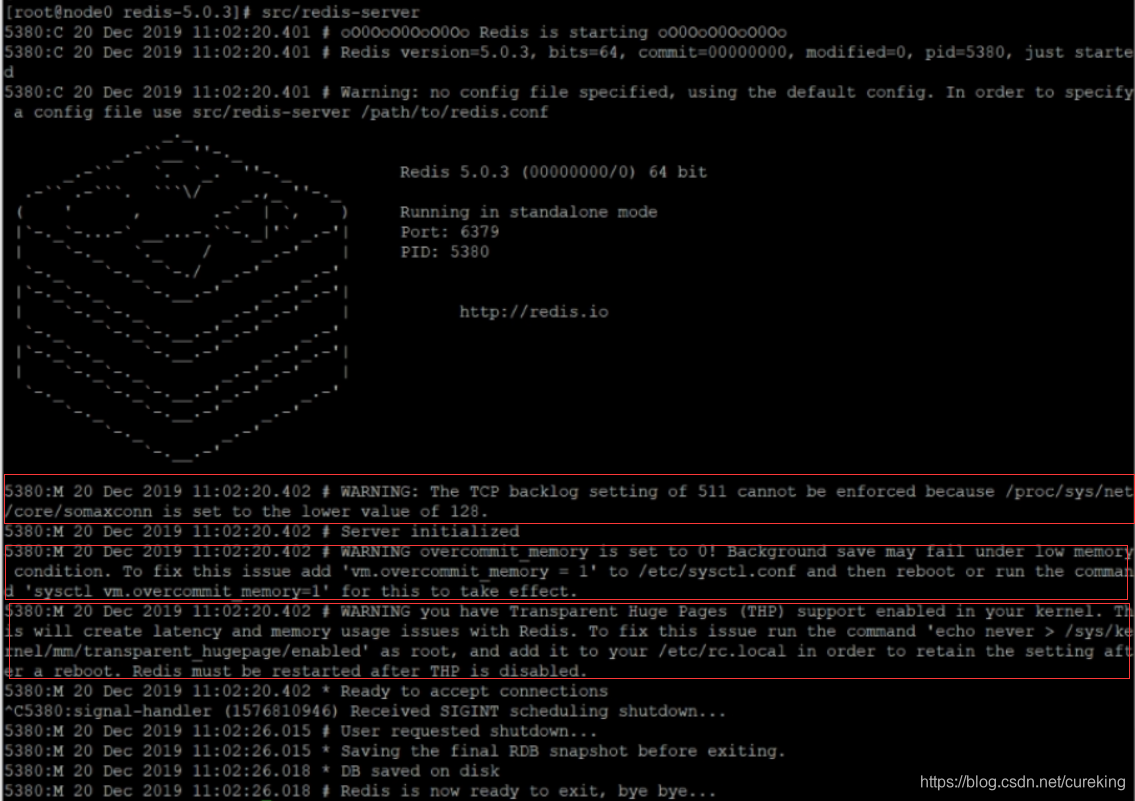
修改Linux内核参数
WARNING The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.解决:
echo 1024 >/proc/sys/net/core/somaxconnovercommit_memory问题
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.解决:
echo "vm.overcommit_memory = 1" >> /etc/sysctl.conf
sysctl vm.overcommit_memory=1THP问题
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled解决:
echo never > /sys/kernel/mm/transparent_hugepage/enabled校验
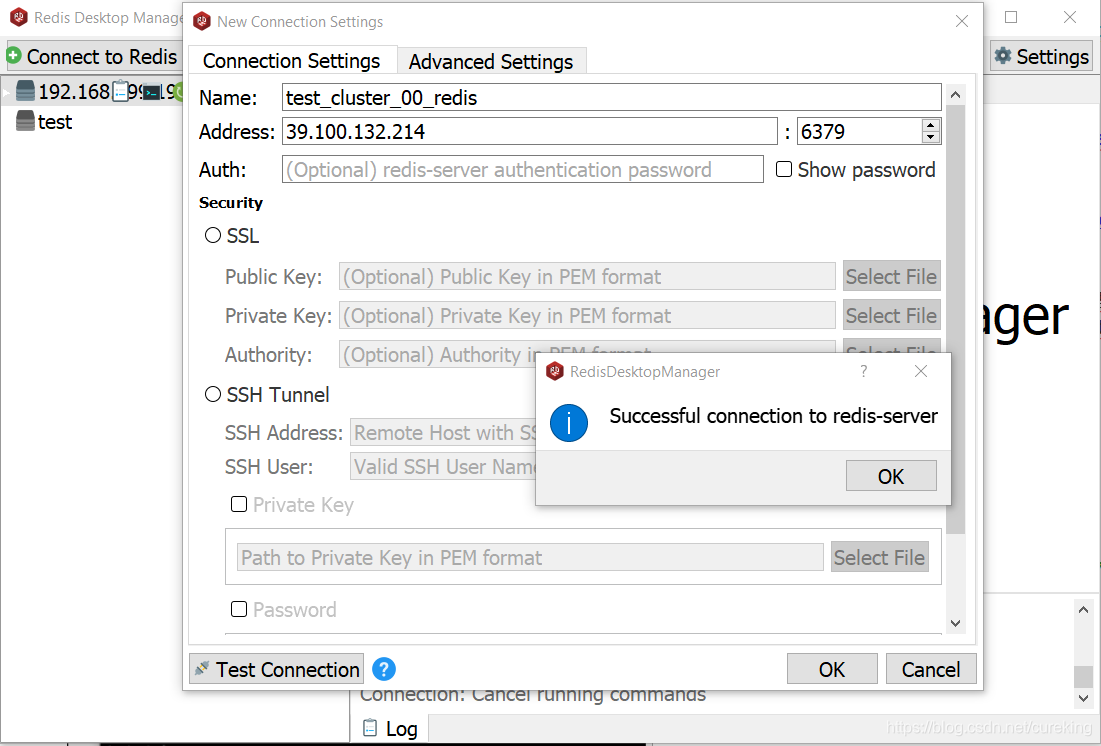
为了更好的校验,这里给大家提供一个工具-Redis-desktop-manager
redis-desktop-manager:提取码:jdc2
作为正版软件,会有14天的试用期。当然,如果几乎不用,也可以使用盗版。但是还是推荐正版的说(正版功能强大),貌似还有github提交,就可以免费的说法(起码以前是存在的,现在就不清楚了)。
如果看到以下画面,就表示OK了:
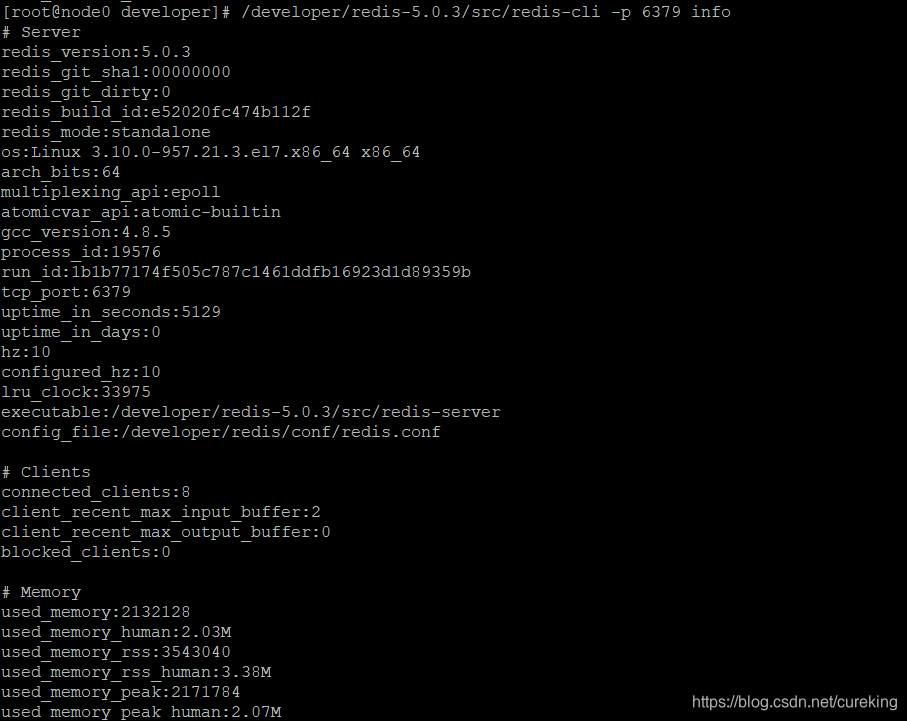
另外,可以通过以下命令校验:
/developer/redis-5.0.3/src/redis-cli -p 6379 info一般看到如下画面即可:
Redis主从复制
Redis的主从复制还是较为简单的。
主要分为两个方面,一方面是多个独立的Redis实例,另一方面是Redis的slaveof配置(共有三种方式)。
Redis文件发送
通过以下命令,进行Redis的文件发送:
scp -r /developer/ root@172.26.40.224:/上述命令,是将当前服务器的/developer目录整个(-r 表示递归)发送给172.26.40.224服务器。
slaveof配置
这里的Redis主服务器的地址为172.26.40.225,其端口为6379
配置文件设置
在配置文件中添加以下语句:
slaveof 172.26.40.225 6379正常启动,控制台并不会有专门的提示,正常如下:

redis-server启动时配置参数
这种情况下,无法使用配置文件。
起码没法直接使用,可能我的使用存在问题(平时不用这个)。囧
正常使用,可以看到如下画面:
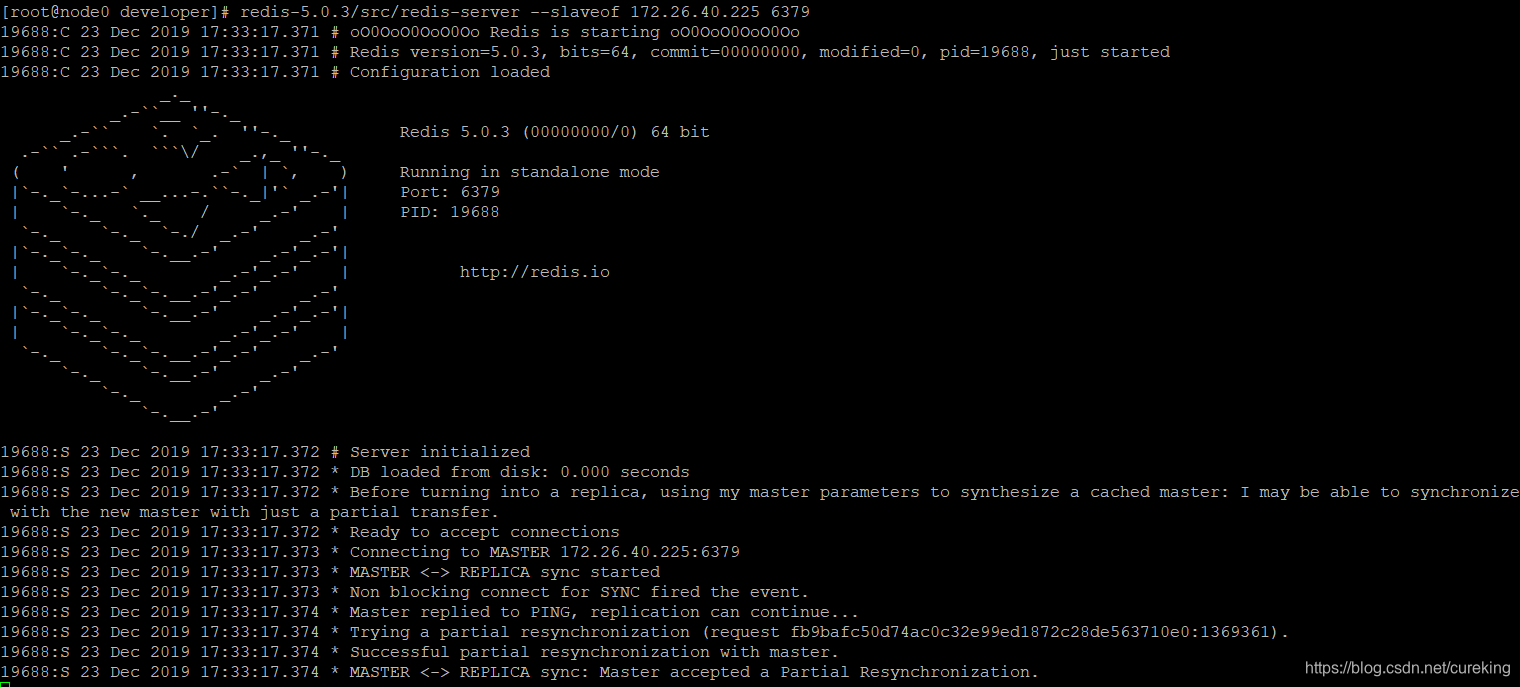
redis-cli运行时设置
而通过redis-cli程序,在程序运行时,进行集群调整。

脱离集群
扩展一下,有的时候,我们需要将实例,移出当前集群。
既然是运行时,那当然是通过redis-cli程序。

校验
可以通过以下命令:
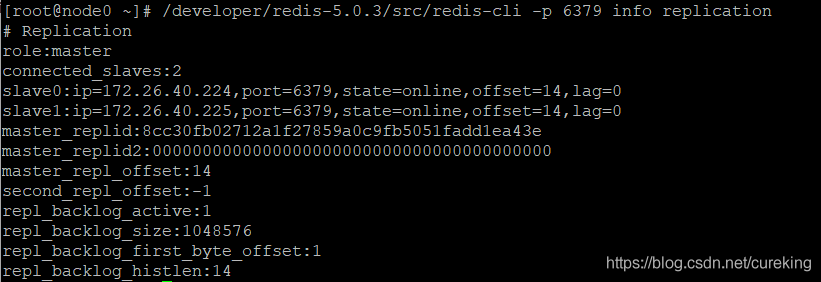
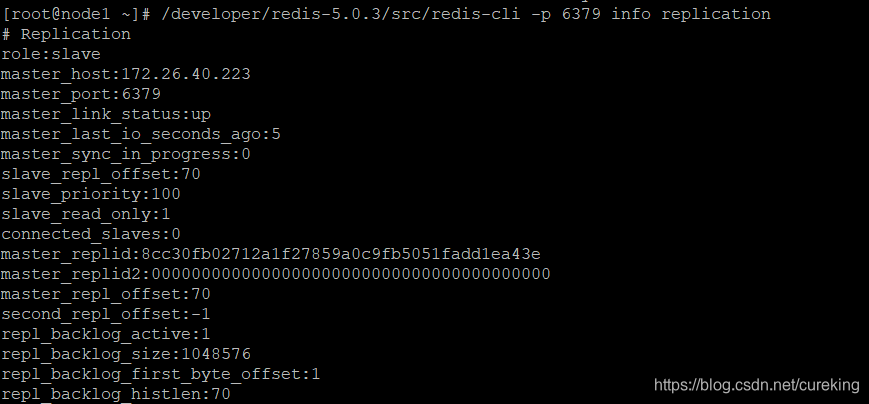
/developer/redis-5.0.3/src/redis-cli -p 6379 info replication分别查看Redis实例信息。
如果看到以下页面,表示Redis主从集群正常启动:
Redis主实例:
Redis从实例:
读写分离应用
这里简单谈一下,程序如何使用读写分离,如Jedis如何实现读写分离。
目前看到的主要有两种:
- 建立多个Jedis对象,并通过Jedsi.slaveof来设定主从
- 在配置文件中建立多个redis数据源,并通过动态转换类,实现在不同需求时,注入不同的redis连接
当然上述编码并不友好,一方面这些硬编码在应用程序中(这个可以通过配置来解决),另一方面存在一致性与扩展性问题(程序中的设置,与Redis的集群本身耦合较高。至于这属于哪种级别的耦合,我忘了。囧)。
当然,我们也可以只获取Redis主实例的连接信息,再通过拼接”info replication“命令等,来获取Redis从实例的连接信息。
这样就提高了系统扩展性,因为不再受限于Redis从实例设置。但如果Redis主实例挂了,就比较尴尬了。不过,我们也可以继续深入去进行Redis主实例监听,从而便于进行主从切换等。
而这儿,就引出了哨兵机制。
(不是只谈安装嘛。但是一时忍不住,就简单谈一下自己的思路哈)
哨兵机制
正如其名,哨兵机制类似于一个Redis主从集群的代理,对应用程序透明,从而避免应用程序与Redis集群机制的高度耦合。
说个人话,哨兵会根据Redis集群情况,自行进行主从切换,从而确保为应用程序提供有效的Redis缓存服务。
接下来就开始Redis哨兵机制的部署吧。
启动Redis主从集群
Redis哨兵机制是基于Redis主从集群的。所以首先,需要根据前面的操作步骤,安装并启动Redis主从集群。
前面有详谈,这里不再赘述。
哨兵机制的配置
话不多说,直接上配置:
# 配置文件:sentinel.conf,在sentinel运行期间是会被动态修改的
# sentinel如果重启时,根据这个配置来恢复其之前所监控的redis集群的状态
# 绑定IP
#bind 0.0.0.0
# 后台运行
daemonize yes
# 默认yes,没指定密码或者指定IP的情况下,外网无法访问
protected-mode no
# 哨兵的端口,客户端通过这个端口来发现redis
port 26380
# 哨兵自己的IP,手动设定也可自动发现,用于与其他哨兵通信
# sentinel announce-ip
# 临时文件夹
dir "/developer/redis/tmp"
# 日志
logfile "/developer/redis/logs/sentinel-26380.log"
# sentinel监控的master的名字叫做mymaster,(redis的master服务器,哨兵需要通过这个master获取集群信息)初始地址为 172.26.40.223 6379,2代表两个及以上哨兵认定为死亡,才认为是真的死亡,即客观下线。由于目前是单个哨兵,所以设置为1,即主观下线等同客观下线。
#sentinel monitor mymaster 172.26.40.223 6379 2
sentinel monitor mymaster 172.26.40.223 6379 1
# 发送心跳PING来确认master是否存活
# 如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了
sentinel down-after-milliseconds mymaster 1000
# 如果在该时间(ms)内未能完成failover操作,则认为该failover失败
sentinel failover-timeout mymaster 3000
# 指定了在执行故障转移时,最多可以有多少个从Redis实例在同步新的主实例,在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长(因为越多的从实例同步新主实例,新主实例的负载压力越大,对外提供的服务能力就越弱)
sentinel parallel-syncs mymaster 1
启动哨兵
然后就是通过以下命令,启动哨兵:
/developer/redis-5.0.3/src/redis-sentinel /developer/redis/conf/sentinel.conf启动后,光从控制台的回馈是看不到任何东西的。
校验
需要通过以下命令进行校验:
/developer/redis-5.0.3/src/redis-cli -p 26380 info sentinel如果看到以下页面,表示哨兵正常启动:

其实,还有一个验证方式,那就是查看哨兵配置(因为哨兵正常启动后,会将持久化信息,保存在配置中)。
详见下图:
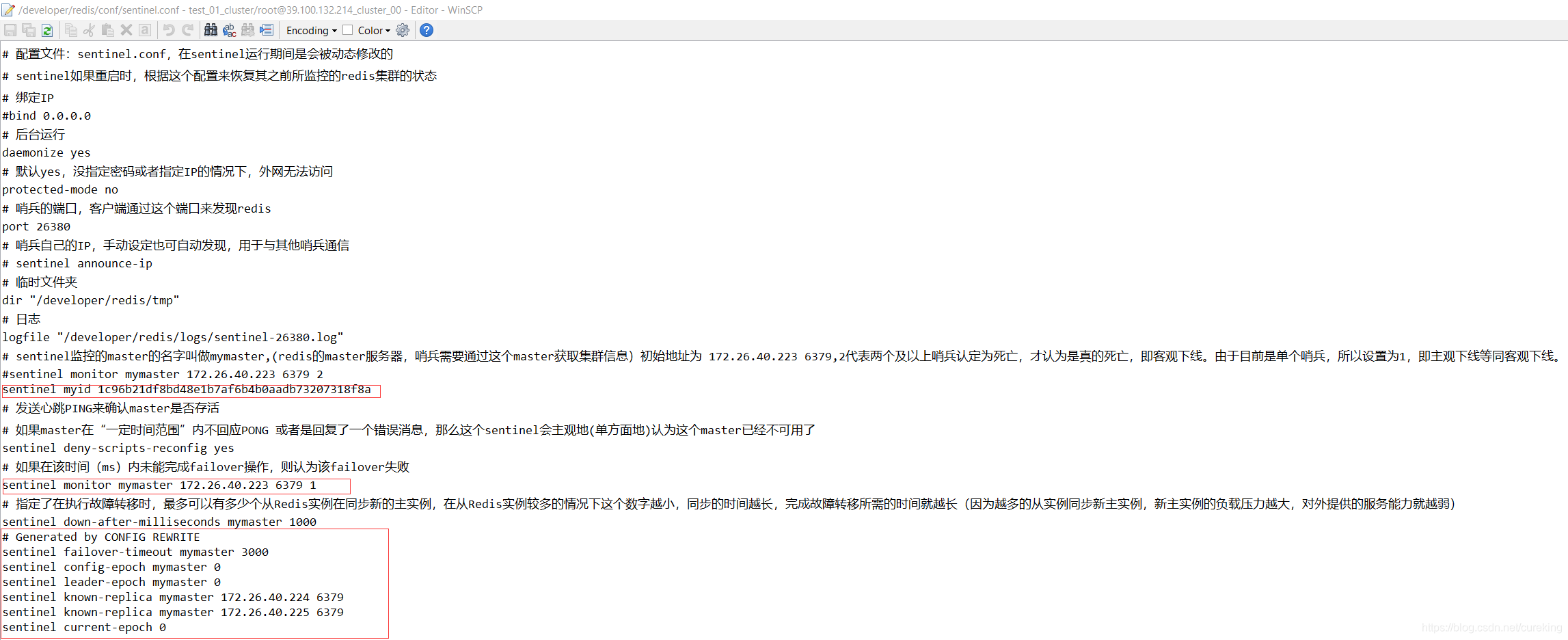
从图中可以看到,不仅新增了两个从服务器的信息(哨兵通过info命令,与master交互获得),还改动了原来的几处配置(生成myid,替代ip:port等)。
哨兵机制的自动主从切换
正如前面提到的,哨兵机制可以自动进行主从切换。
接下来会阐述一下哨兵机制进行主从切换的内在,不感兴趣的朋友可以直接跳过。
就拿上面的服务器状态,进行尝试,直接关闭Redis主实例。
原Redis主实例
其中最引人瞩目的,自然是原Redis主实例的变化,详见下图:
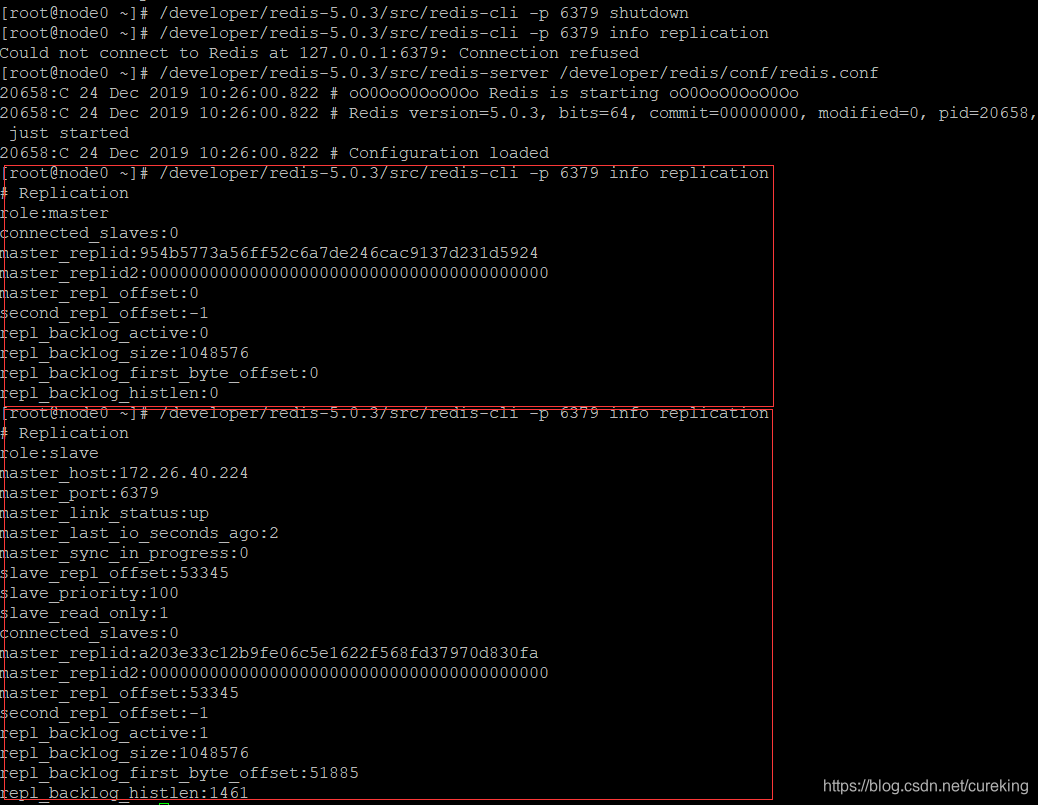
可以看出,在原Redis主实例刚启动时,它还是独立的Redis单机实例。
但是在稍等一会儿(如十秒)后,原Redis主实例就会加入原来的集群中,成为原来集群的一个slave。
新Redis主实例
再就是新Redis主实例的变化:
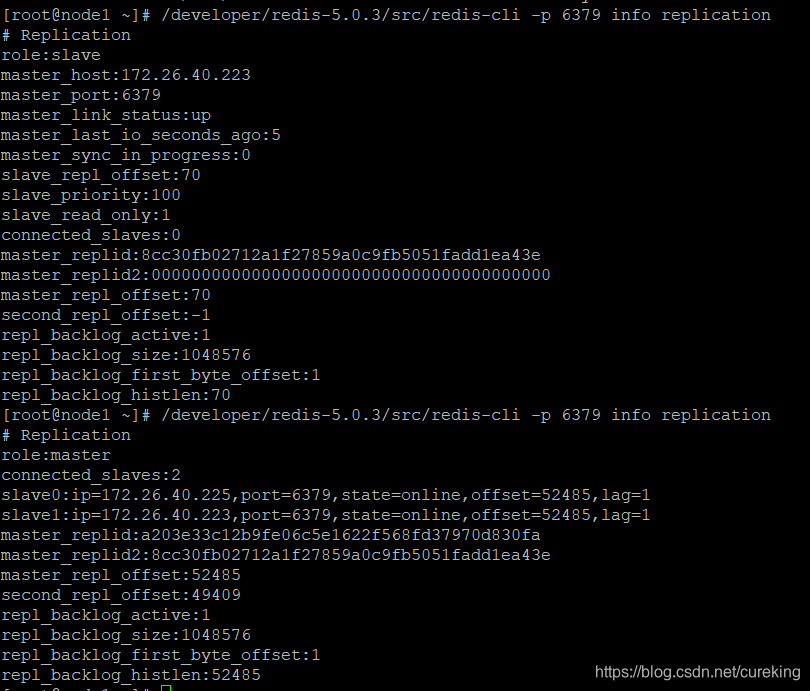
新Redis主实例,会从原来的slave,晋级为master。这个晋级实例的选择并不是随机的,而是有着一定规则的,以后有机会再介绍。
其它Redis从实例
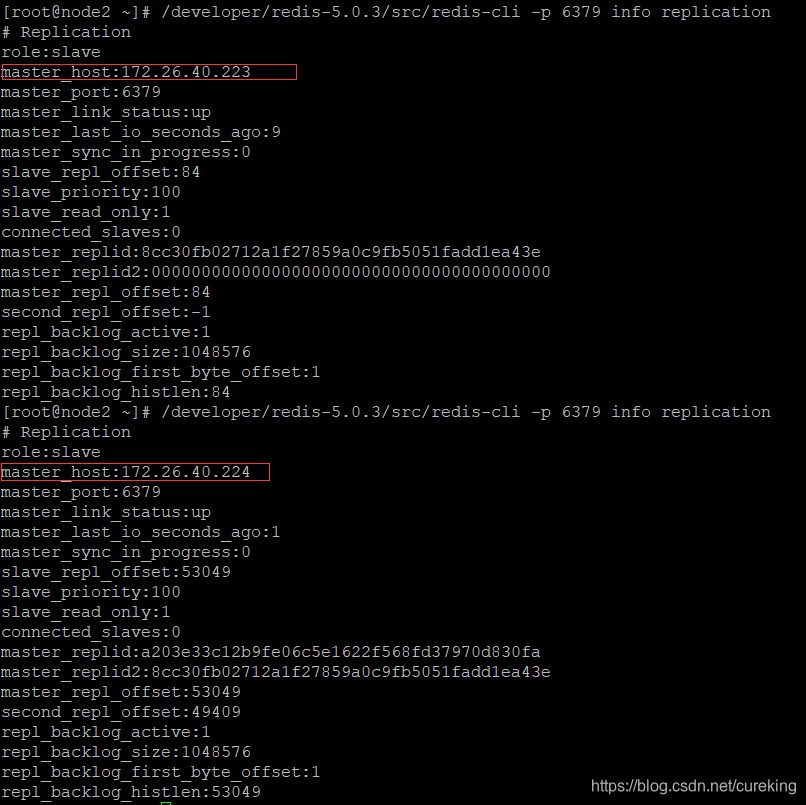
其它Redis从实例,将会改变集群中的master。
配置变化
其实,更为直接的观察,可以查看配置。
其实,我刚开始了解哨兵时,我非常好奇一个现象。那就是原Redis主实例,在重新上线后,再次加入集群的流程是怎样的?其中的持久化信息(如IP等)是保存在哪里的?
经过一番思考后,我查看了Redis配置与哨兵配置,才发现这一切都在配置中有所体现:
Redis配置
哨兵机制下,Redis配置的变化,有两个时间。一个是哨兵启动时,另一个是主从切换时。
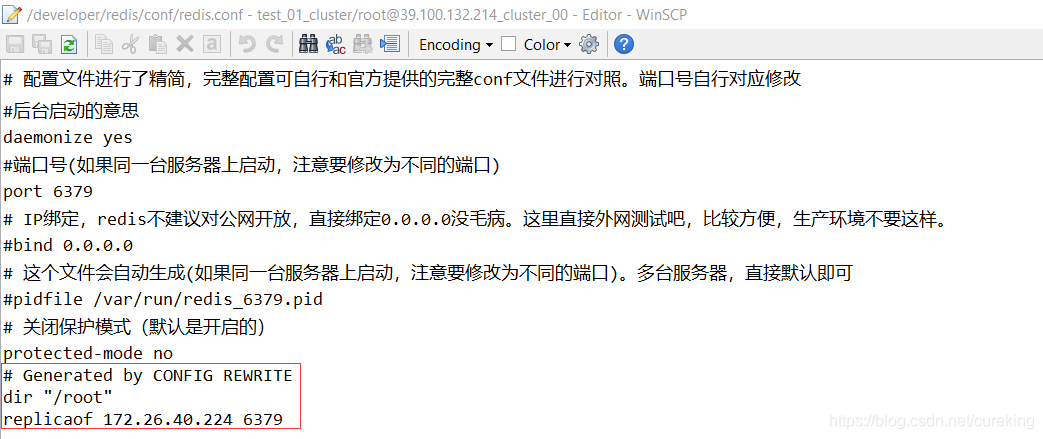
红框标记的部分,表示该Redis实例,从172.26.40.224(master)处,进行复制。
如果是Redis主实例,那么其配置的红框部分则为:
# Generated by CONFIG REWRITE
dir "/root"哨兵配置
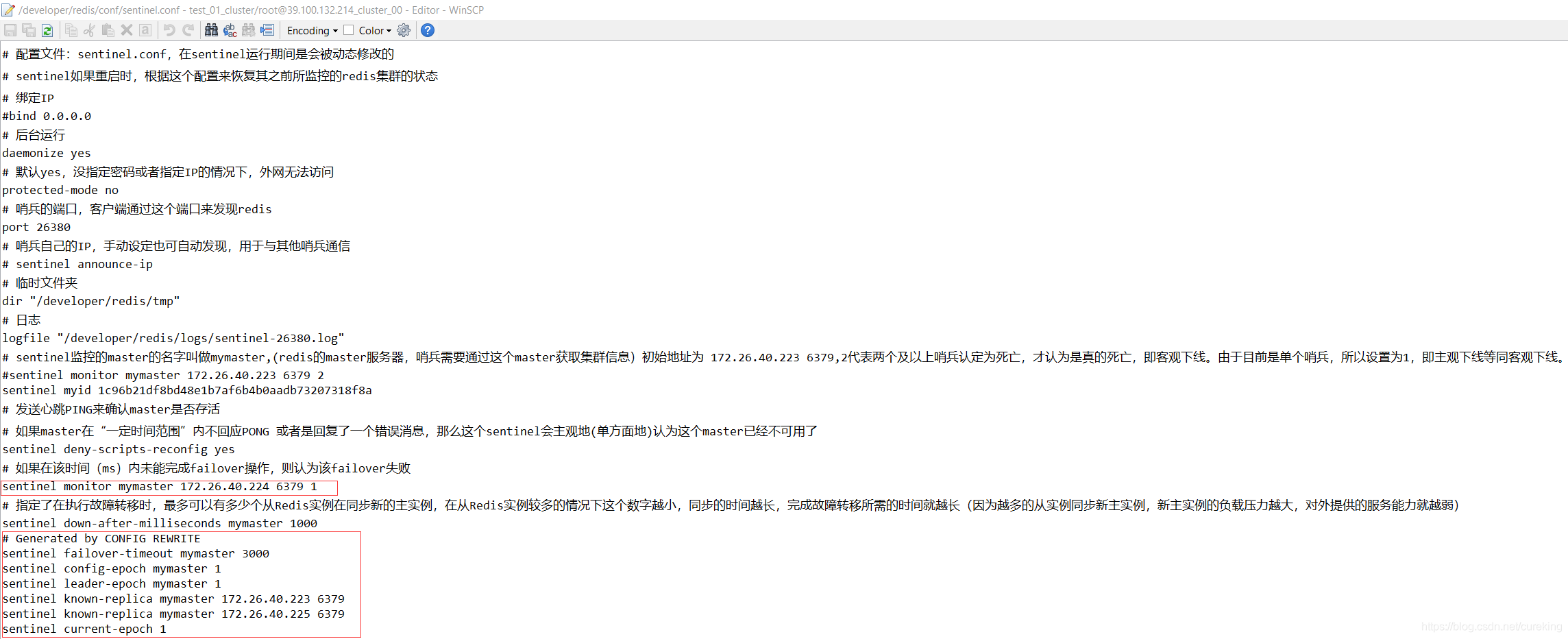
由于哨兵保留了整个集群的信息,所以它可以自由控制集群中各个实例节点的状态。
这也解释了原Redis实例在离开集群,重启后,为什么可以迅速回归集群。因为其在哨兵配置中已经留有“案底“了。
哨兵机制的应用
简单说,使用哨兵机制后,客户端可以直连哨兵,而不再是Redis服务实例了。
这里的哨兵将类似于一个代理。
哨兵集群
当然之前的哨兵存在单点故障问题,所以需要将哨兵构造成集群。
但是哨兵的集群搭建,其实和之前并没有区别,只不过这次启动了多个哨兵而已。
当然哨兵的配置可以稍作修改,来提高哨兵集群的价值。
哨兵配置
# 配置文件:sentinel.conf,在sentinel运行期间是会被动态修改的
# sentinel如果重启时,根据这个配置来恢复其之前所监控的redis集群的状态
# 绑定IP
#bind 0.0.0.0
# 后台运行
daemonize yes
# 默认yes,没指定密码或者指定IP的情况下,外网无法访问
protected-mode no
# 哨兵的端口,客户端通过这个端口来发现redis
port 26380
# 哨兵自己的IP,手动设定也可自动发现,用于与其他哨兵通信
# sentinel announce-ip
# 临时文件夹
dir "/developer/redis/tmp"
# 日志
logfile "/developer/redis/logs/sentinel-26380.log"
# sentinel监控的master的名字叫做mymaster,(redis的master服务器,哨兵需要通过这个master获取集群信息)初始地址为 172.26.40.224 6379,2代表两个及以上哨兵认定为死亡,才认为是真的死亡,即客观下线。
sentinel monitor mymaster 172.26.40.224 6379 2
# 发送心跳PING来确认master是否存活
# 如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了
sentinel down-after-milliseconds mymaster 1000
# 如果在该时间(ms)内未能完成failover操作,则认为该failover失败
sentinel failover-timeout mymaster 3000
# 指定了在执行故障转移时,最多可以有多少个从Redis实例在同步新的主实例,在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长(因为越多的从实例同步新主实例,新主实例的负载压力越大,对外提供的服务能力就越弱)
sentinel parallel-syncs mymaster 1
其实就是修改了 sentinel monitor mymaster 172.26.40.224 6379 2 ,
数字1改为2,是为了确保故障转移的客观性(详情了解主观下线与客观下线)。
IP地址的变换,是因为现在的master是172.26.40.224而已。
启动
只需要通过以下命令:
/developer/redis-5.0.3/src/redis-sentinel /developer/redis/conf/sentinel.conf依次启动多个哨兵实例(甚至可以在一台服务器上启动,那就需要修改哨兵配置中的端口号)
校验
启动后,通过以下命令验证各个哨兵实例:
/developer/redis-5.0.3/redis-cli -p 26380 info sentinel如果看到以下页面,则表示启动成功:

PS:页面中显示了哨兵监控的Redis集群master(哨兵可以监控多个Redis集群),对应Redis集群master0的相关信息(如name,状态,主服务器ip:port,以及从服务器数量,对应哨兵数量)等。
哨兵集群的应用
哨兵集群在应用中的使用与哨兵类似,不过这次需要在应用中配置哨兵集群(即配置多个哨兵地址)。
扩展
忍不住多说两句。
哨兵的持久化信息是保存在哨兵配置中的。
哨兵之间的通信是通过Redis的pubsub机制实现的(包括互相发现)。详见:基于pubsub机制的哨兵通信
分片集群(多主多从的混合架构)
前面哨兵说得再骚气,也逃不过一个瓶颈,那就是Redis写瓶颈。毕竟是一主多从的。
所以当写压力超过Redis单例上限时,就需要Redis分片集群了。毕竟多主可以多个Redis主实例进行写操作,所以可以突破主从架构的写瓶颈。
当然多主多从的混合架构,才是目前的主流(即每个主,都有从服务器用于确保可用性)。
而混合架构会比单纯的多主无从架构,复杂一些。所以这里直接上多主多从的混合架构。
配置修改
为了开启分片集群,需要修改每个Redis的配置(即之前的redis.conf)
# 配置文件进行了精简,完整配置可自行和官方提供的完整conf文件进行对照。端口号自行对应修改
#后台启动的意思
daemonize yes
#端口号(如果同一台服务器上启动,注意要修改为不同的端口)
port 6379
# IP绑定,redis不建议对公网开放,直接绑定0.0.0.0没毛病。这里直接外网测试吧,比较方便,生产环境不要这样。
#bind 0.0.0.0
# 这个文件会自动生成(如果同一台服务器上启动,注意要修改为不同的端口)。多台服务器,直接默认即可
#pidfile /var/run/redis_6379.pid
# 关闭保护模式(默认是开启的)
protected-mode no
# 新增配置
# 数据保存目录
dir /developer/redis/data
# 开启AOF
appendonly yes
# just for cluster
# 开启集群
cluster-enabled yes
# 集群配置会自动生成在上述的data目录
cluster-config-file cluster_node_00.conf
# 集群节点失联时长判断
cluster-node-timeout 5000
# 如果是在单台集群部署集群,需要设置pidfile。这里由于每个服务器都只有一个实例,故采用默认设置(6379)上述新增配置,均有注释。这里简单提一下,这个配置只是令单个Redis实例有了成为Redis集群实例的资格。当这些Redis实例构成集群时,集群的配置信息会由集群生成,并由每个Redis实例保存至配置中设置的目录中。
这里简单展示一下,集群生成的配置(切记,这个配置只有集群启动后才有。这里只是提前展示一下):
node0
2e1714431f76910db0e1808ce3a3a9b645d2c38f 172.26.40.225:6379@16379 master - 0 1577441663610 7 connected 0-99 10923-16383
cf755c2ca1757c1828b8da972fc7841305b9b41f 172.26.40.224:6379@16379 master - 0 1577441665000 2 connected 5461-10922
29c4fc9d4807c1e25a56b1cc0c9387ba1e6f5831 172.26.40.226:6379@16379 slave 45c1607ecf3d80f08cf6056d53f73a529ffc17de 0 1577441664000 1 connected
7aaa3b4a7dc9ad6c2348f9d6227c4c555e24f3fb 172.26.40.228:6379@16379 slave 2e1714431f76910db0e1808ce3a3a9b645d2c38f 0 1577441665615 7 connected
24c8fefdb293087adb40eaa45cd9213a8d7d5191 172.26.40.227:6379@16379 slave cf755c2ca1757c1828b8da972fc7841305b9b41f 0 1577441664613 5 connected
45c1607ecf3d80f08cf6056d53f73a529ffc17de 172.26.40.223:6379@16379 myself,master - 0 1577441664000 1 connected 100-5460
vars currentEpoch 7 lastVoteEpoch 0node1
2e1714431f76910db0e1808ce3a3a9b645d2c38f 172.26.40.225:6379@16379 master - 1577441665696 1577441663000 7 connected 0-99 10923-16383
45c1607ecf3d80f08cf6056d53f73a529ffc17de 172.26.40.223:6379@16379 master - 0 1577441664000 1 connected 100-5460
29c4fc9d4807c1e25a56b1cc0c9387ba1e6f5831 172.26.40.226:6379@16379 slave 45c1607ecf3d80f08cf6056d53f73a529ffc17de 0 1577441664687 1 connected
24c8fefdb293087adb40eaa45cd9213a8d7d5191 172.26.40.227:6379@16379 slave cf755c2ca1757c1828b8da972fc7841305b9b41f 0 1577441664000 5 connected
7aaa3b4a7dc9ad6c2348f9d6227c4c555e24f3fb 172.26.40.228:6379@16379 slave 2e1714431f76910db0e1808ce3a3a9b645d2c38f 1577441665696 1577441663000 7 connected
cf755c2ca1757c1828b8da972fc7841305b9b41f 172.26.40.224:6379@16379 myself,master - 0 1577441663000 2 connected 5461-10922
vars currentEpoch 7 lastVoteEpoch 0node5
7aaa3b4a7dc9ad6c2348f9d6227c4c555e24f3fb 172.26.40.228:6379@16379 myself,slave 2e1714431f76910db0e1808ce3a3a9b645d2c38f 0 1577441661000 6 connected
cf755c2ca1757c1828b8da972fc7841305b9b41f 172.26.40.224:6379@16379 master - 1577441665165 1577441663696 2 connected 5461-10922
2e1714431f76910db0e1808ce3a3a9b645d2c38f 172.26.40.225:6379@16379 master - 0 1577441663000 7 connected 0-99 10923-16383
45c1607ecf3d80f08cf6056d53f73a529ffc17de 172.26.40.223:6379@16379 master - 0 1577441664000 1 connected 100-5460
24c8fefdb293087adb40eaa45cd9213a8d7d5191 172.26.40.227:6379@16379 slave cf755c2ca1757c1828b8da972fc7841305b9b41f 0 1577441664665 5 connected
29c4fc9d4807c1e25a56b1cc0c9387ba1e6f5831 172.26.40.226:6379@16379 slave 45c1607ecf3d80f08cf6056d53f73a529ffc17de 0 1577441664163 1 connected
vars currentEpoch 7 lastVoteEpoch 0启动Redis实例
在配置完成后,需要将每个组成Redis集群的实例,通过以下指令,分别启动。
/developer/redis-5.0.3/src/redis-server /developer/redis/conf/redis.conf当然,集群启动后,也还是可以动态增删节点的。所以不必太过担心。
这里的启动与验证,与之前Redis启动是一样的,这里不再赘述。
创建集群
在集群基本构成的各个Redis实例节点都正常启动后,接下来就是将它们串联起来,构成Redis集群。
通过以下指令,构建集群(该指令只适用于5.0+版本):
/developer/redis-5.0.3/src/redis-cli --cluster create 172.26.40.223:6379 172.26.40.224:6379 172.26.40.225:6379 172.26.40.226:6379 172.26.40.227:6379 172.26.40.228:6379 --cluster-replicas 1简单解释一下这个指令,前半部分就是通过redis-cli调用集群模式(--cluster)下的create指令,将上述6个Redis实例构成集群(通过ip:port定位,所以可以单机部署集群,虽然非常鸡肋就是了)。最后部分,就是通过--cluster-replicas参数设定这个集群每个master都有1个slave实例。这里可以设置多个slave实例,并且slave实例还可以设置自己的slave实例。
成功运行后,可以见到如下页面:
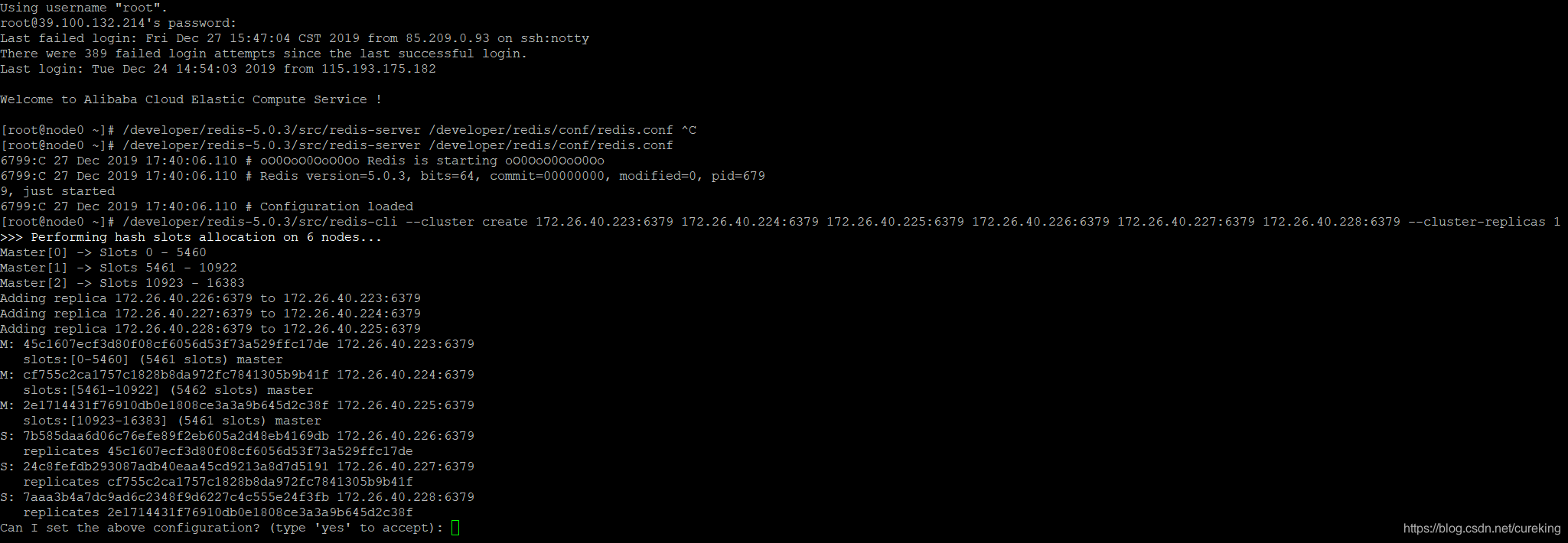
这时候,直接yes确认即可,如果需要修改,可以后续调整。
确认后,可以看到如下图片:
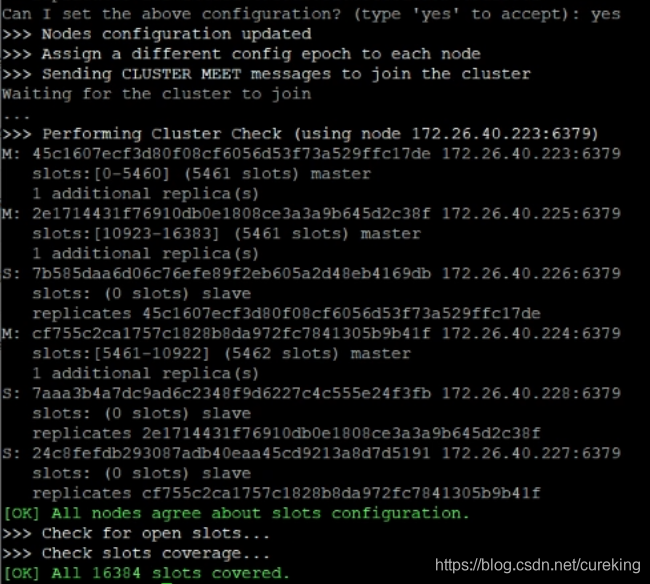
这个时候就已经完成了分片集群的搭建。
集群校验
通过以下命令,可以确认redis集群槽点分布的信息:
/developer/redis-5.0.3/src/redis-cli -c -p 6379 cluster nodes如果看到以下画面,表示槽点分片OK:

集群测试
为了确认Redis分片集群的功能,我们来做一个简单的测试。
就是进入node2的redis实例(主实例),保存a=1数据。然后看是否可以通过node0(主实例,也可以从实例)来获取a对应的值。
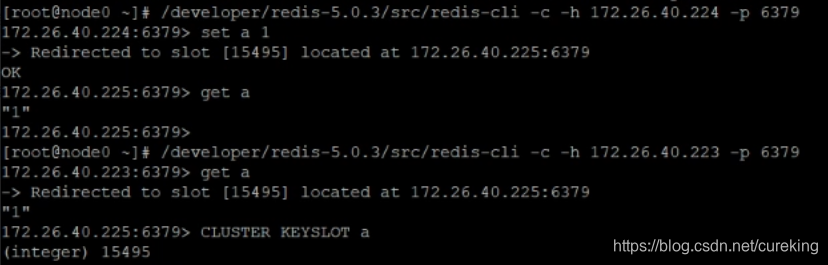
上述图片中,还通过
CLUSTER KEYSLOT a来确认key=a的数据所在槽点,确实是node0重导向的15495槽点位。
集群操作
前面已经完成了Redis分片集群的安全与确认,这里简单说一下集群操作,不感兴趣的朋友,可以直接跳过。
槽点整理
由于数据倾斜与访问倾斜问题,新master入集群(新master进入集群时是不会分配槽点的)等问题,可能我们对于原先的槽点分布并不满意,所以需要将一个master实例上的槽点,移动一定数量到另一个master槽点。
可以通过以下指令实现:
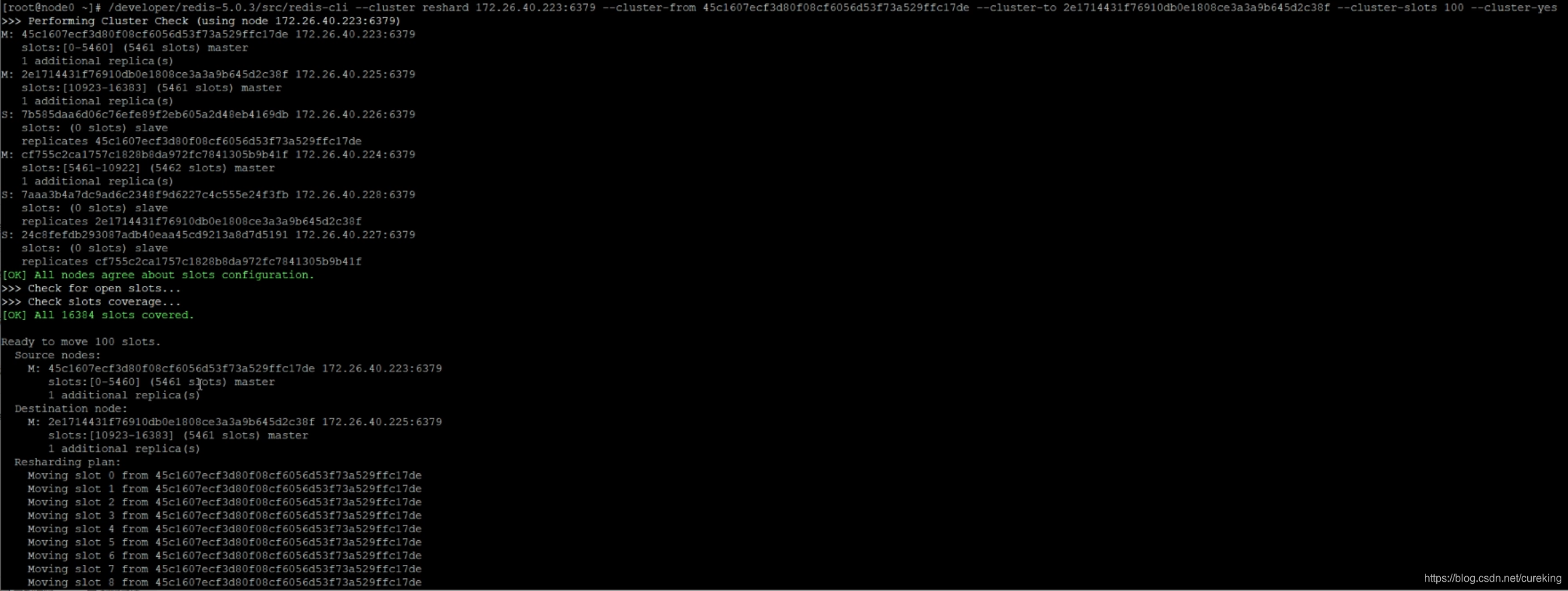
/developer/redis-5.0.3/src/redis-cli --cluster reshard 172.26.40.223:6379 --cluster-from 45c1607ecf3d80f08cf6056d53f73a529ffc17de --cluster-to 2e1714431f76910db0e1808ce3a3a9b645d2c38f --cluster-slots 100 --cluster-yes该指令,将从id为45c1607ecf3d80f08cf6056d53f73a529ffc17de的master实例,划分100个槽点到id为2e1714431f76910db0e1808ce3a3a9b645d2c38f的master实例。
PS:master-id可以通过前面的cluster nodes等指令查看。
可以看到以下画面:
然后,通过
/developer/redis-5.0.3/src/redis-cli --cluster check 172.26.40.223:6379检查集群的槽点状态,可以看到以下画面:
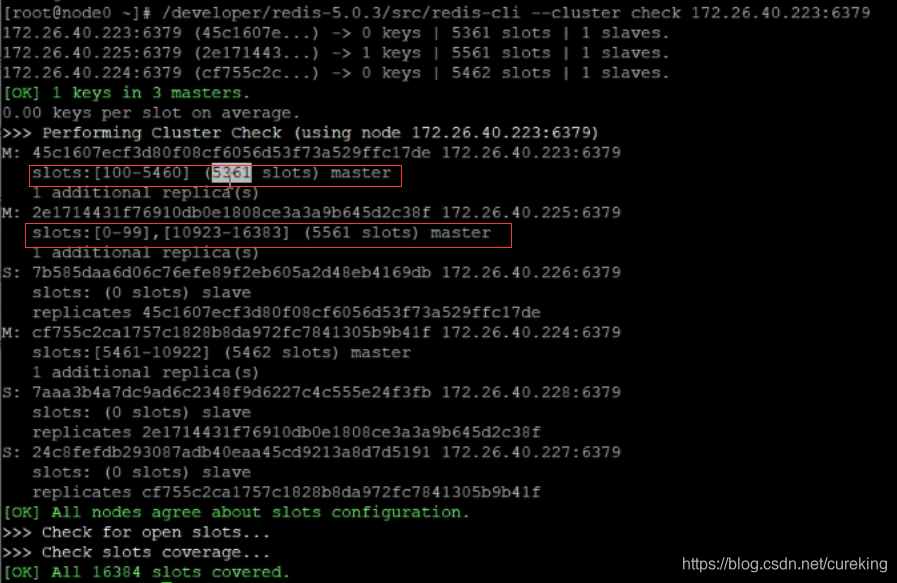
可以明显看到槽点整理的结果。
删除节点
接下来都比较简单,我就简单放上图片了。需要的地方,我会提示一下。
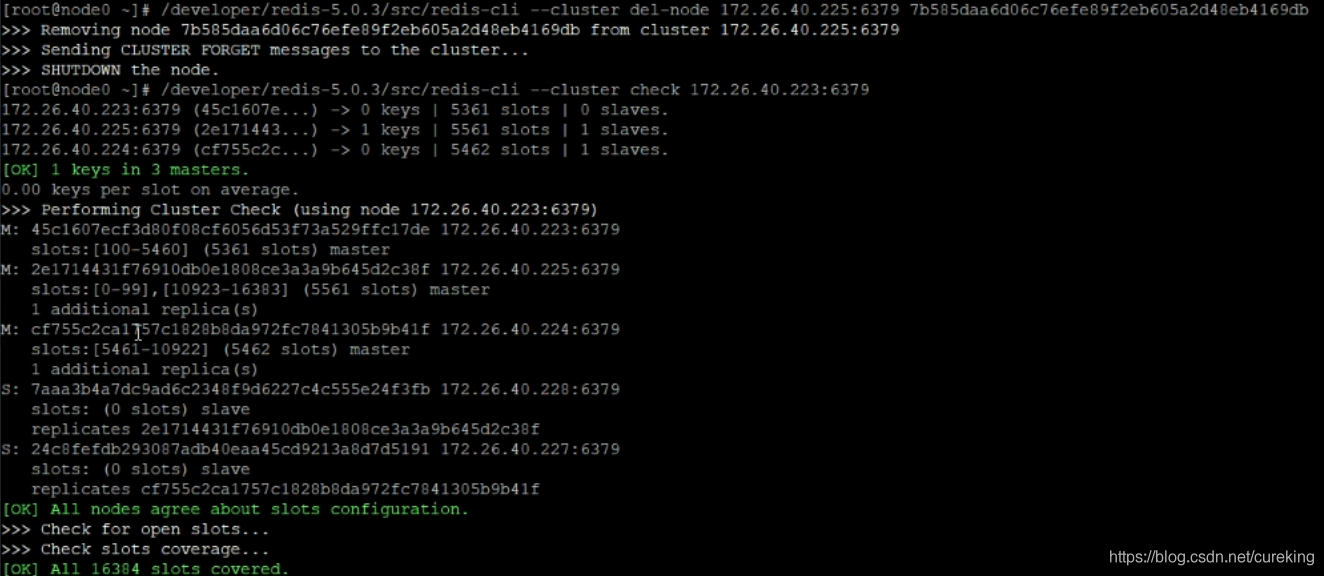
PS:删除节点时,该实例不仅从当前集群移除,并且会被shutdown。
增加节点
首先,启动对应节点。这里不再赘述。
其次,通过以下指令,实现节点添加:
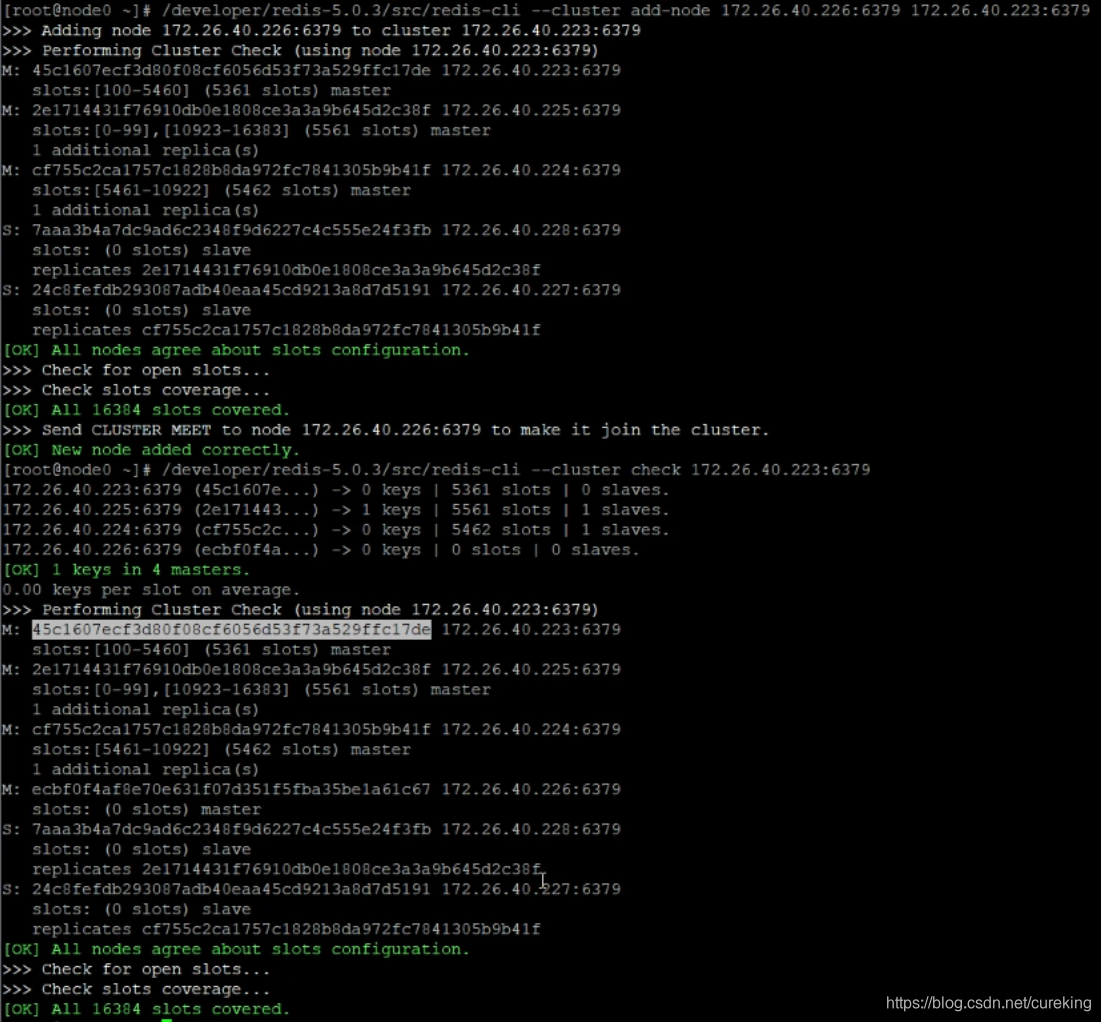
/developer/redis-5.0.3/src/redis-cli --cluster add-node 172.26.40.226:6379 172.26.40.223:6379PS:上面两个连接信息,前者表示需要添加的新节点信息,后者表示集群中存在的节点信息(表示由该节点执行节点添加操作)。
PS:如果添加的节点是之前存在过集群中的节点,则会出现以下报错:
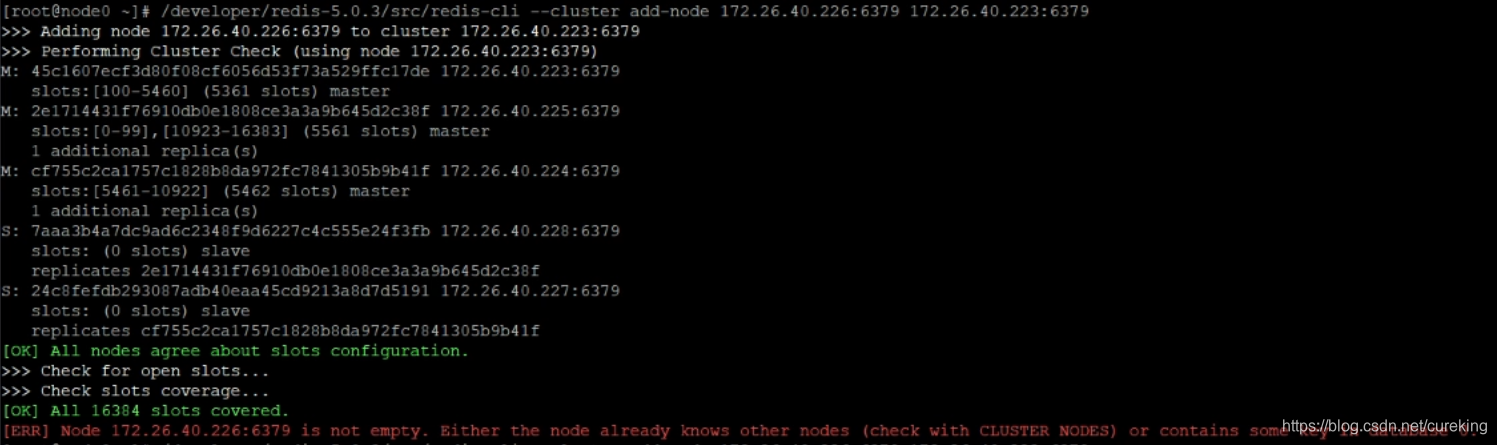
这个时候,根据报错信息,删除redis配置相关信息即可。即删除之前配置的 /developer/redis/data/目录下的三个文件:

然后启动目标实例(如果已经启动,请重启),即可成功运行,看到以下画面:
另外,资料中也有提到,可能在某些情况下,还需要进行db清除操作(但是我这里并不需要)。
增加从节点
可以明显看出,上述的节点添加后,该节点直接成为了master节点。而我们往往需要添加从节点。
通过以下命令,我们可以为集群添加从节点:
/developer/redis-5.0.3/src/redis-cli --cluster add-node 172.26.40.226:6379 172.26.40.223:6379 --cluster-slave运行后,可以看到如下画面:
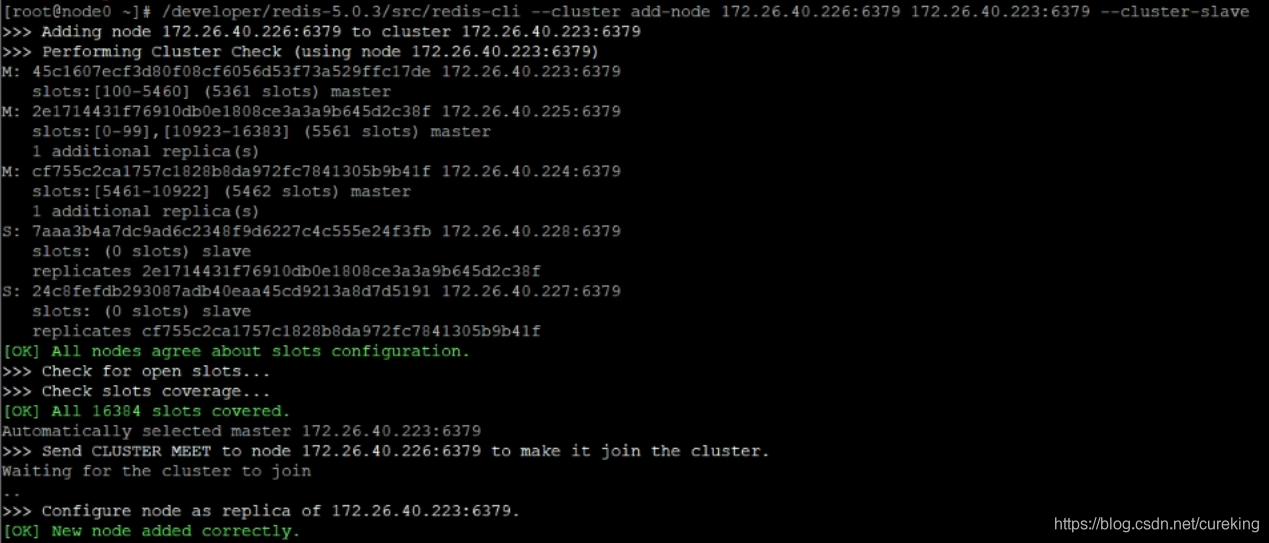
紧接着,校验一下:
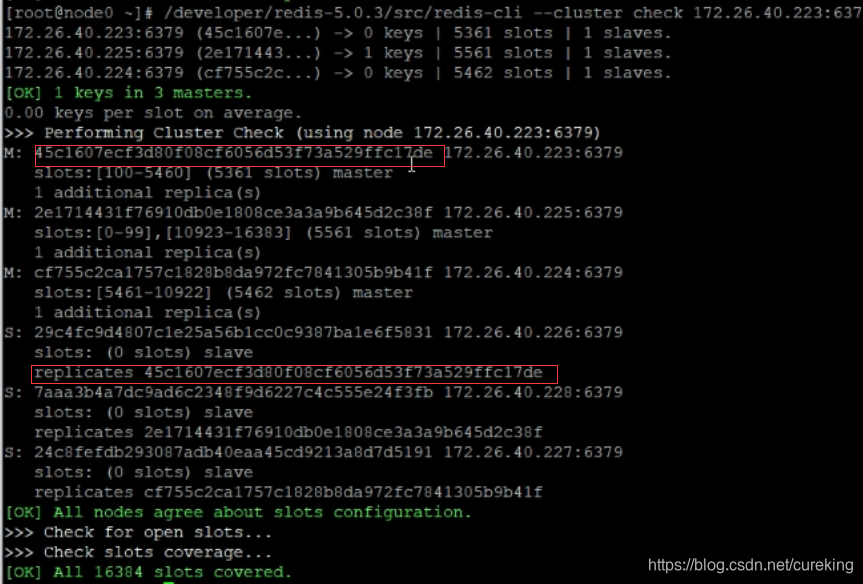
这里默认是将新增从节点,分配给从节点数最少的主节点。
如果希望将新增从节点分配给指定的主节点,则需要以下指令:
/developer/redis-5.0.3/src/redis-cli --cluster add-node 172.26.40.226:6379 172.26.40.223:6379 --cluster-slave --cluster-master-id <master-id>具体执行其实都是类似的,这里不再赘述。
补充
- 虽然分片集群有16384个槽点,理论可以支撑16384个Redis主实例,但是官方推荐是最多1000个实例(毕竟集群间通信等,还是存在瓶颈的)
- redis集群的每个节点使用TCP连接有其它每个节点连接(这也算解释了前面一条)
- 数据倾斜与访问倾斜问题,需要通过调整key的策略,以及slot迁移实现。
这里剽窃一下网易云给出的迁移流程:
- 在迁移目的节点执行cluster setslot
IMPORTING 命令,指明需要迁移的slot和迁移源节点。 - 在迁移源节点执行cluster setslot
MIGRATING 命令,指明需要迁移的slot和迁移目的节点。 - 在迁移源节点执行cluster getkeysinslot获取该slot的key列表。
- 在迁移源节点执行对每个key执行migrate命令,该命令会同步把该key迁移到目的节点。
- 在迁移源节点反复执行cluster getkeysinslot命令,直到该slot的列表为空。
- 在迁移源节点和目的节点执行cluster setslot
NODE ,完成迁移操作。
总结
至此,Redis相关的各类安装操作,以及一些安装问题就全部说完了。
有什么问题,或者需要补充的,可以私信或@我。
觉得不错的话,可以帮忙点个推荐,以及分享给自己的小伙伴。
以上是关于阿里云redis集群数据集中在db0未分散到所有节点问题解决的主要内容,如果未能解决你的问题,请参考以下文章