scrapy爬取数据时,为啥总是302
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy爬取数据时,为啥总是302相关的知识,希望对你有一定的参考价值。
参考技术A 爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发出新的请求。请看: item1 = Item()yield item1item2 = Item()yield item2req = Request(url='下一页的链接', callback=self.parse)yield req 注意使用yield时不要用return语句。 参考技术B 说明被重定向到首页了,在yield scrapy.request里面设置meta属性dont_redirect为true 参考技术C 爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发出新的请求。请看: item1 = Item()yield item1item2 = Item()yield item2req = Request(url='下一页的链接', callback=self.parse)yield req 注意使用yield时不要用return语句。 参考技术D 2种方法:1 在seting.py 中添加
REDIRECT_ENABLED = False
HTTPERROR_ALLOWED_CODES = 302
2,在setting.py中添加
DOWNLOADER_MIDDLEWARES_BASE =
'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400,
'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500,
'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550,
#'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600,
'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750,
'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 800,
'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850,
'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900,
Python爬虫实战,Scrapy实战,爬取并简单分析知网中国专利数据

前言
今天我们就用scrapy爬一波知网的中国专利数据并做简单的数据可视化分析呗。让我们愉快地开始吧~
PS:本项目仅供学习交流,实践本项目时烦请设置合理的下载延迟与爬取的专利数据量,避免给知网服务器带来不必要的压力。
开发工具
Python版本:3.6.4
相关模块:
scrapy模块;
fake_useragent模块;
pyecharts模块;
wordcloud模块;
jieba模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
数据爬取
我们需要爬取的数据例如下图所示:

即包括以下这些内容:

爬取思路:
我们可以很容易地发现每个专利的详情页url都是类似这样的:
http://dbpub.cnki.net/grid2008/dbpub/Detail.aspx?DBName=SCPD年份&FileName=专利公开号&QueryID=4&CurRec=1
因此,只要改变专利公开号即可获得对应专利的详情页url(经测试,即使年份对不上也没关系),从而获得对应专利的信息,具体而言代码实现如下:

All done~完整源代码详见个人简介相关文件。
PS:代码运行方式为运行main.py文件。
数据可视化
为避免给知网服务器带来不必要的压力,这里我们只爬了2014年的一部分知网中国专利数据(就跑了一个多小时吧),对这些数据进行可视化分析的结果如下。
我们先来看看申请专利的省份分布呗:
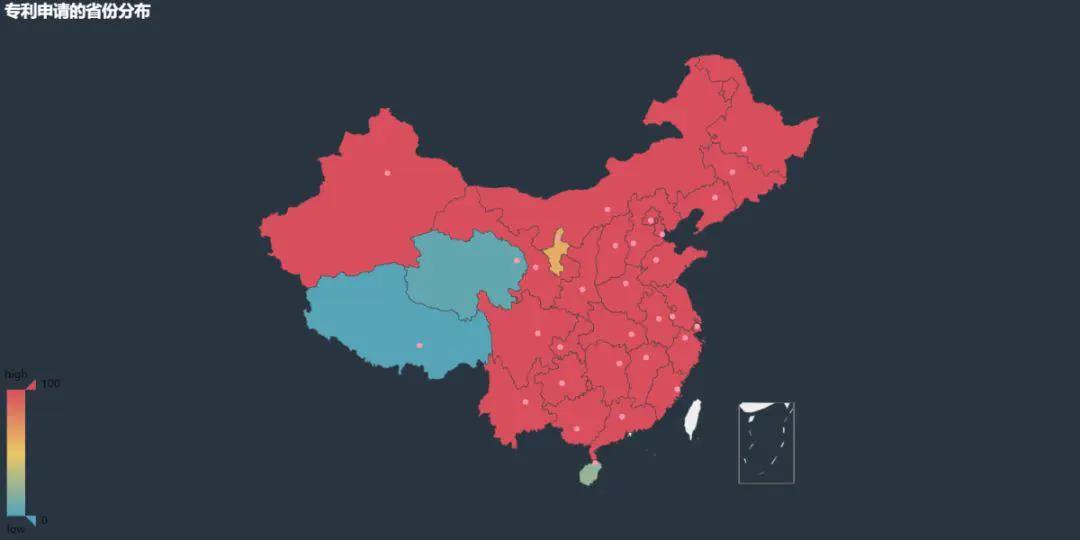
然后再来统计一下专利代理机构?

最后再来看看所有专利摘要做成的词云呗:

还有所有专利标题做成的词云呗:

文章到这里就结束了,感谢你的观看,关注我每天分享Python系列爬虫,下篇文章分享Python爬虫知乎表情包。
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
All done~完整源代码+干货详见个人简介或者私信获取相关文件。。
以上是关于scrapy爬取数据时,为啥总是302的主要内容,如果未能解决你的问题,请参考以下文章