二叉搜索树
Posted 北川_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉搜索树相关的知识,希望对你有一定的参考价值。
目录
二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
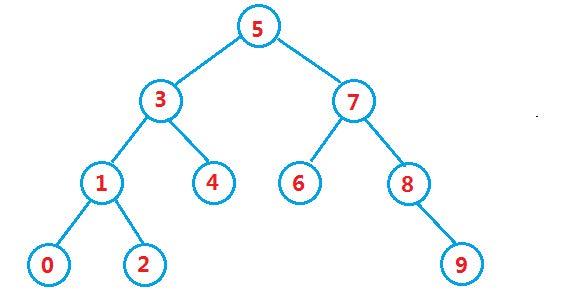
下图即为二叉搜索树
二叉搜索树节点的定义
template<class K>
struct BSTreeNode
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
BSTreeNode(const K& key)
:_left(nullptr)
, _right(nullptr)
, _key(key)
;
template<class K>
class BSTree
typedef BSTreeNode<K> Node;
private:
Node* _root = nullptr;
左右指针用来指向节点的左孩子和右孩子,_key用来存储节点的值,构造函数构造新节点。
搜索树的实现类给出根节点,完整代码中有实现类的具体代码。
二叉搜索树的插入
如果树为空则直接插入,如果树不为空,根据二叉搜索树性质查找插入位置,插入新节点。
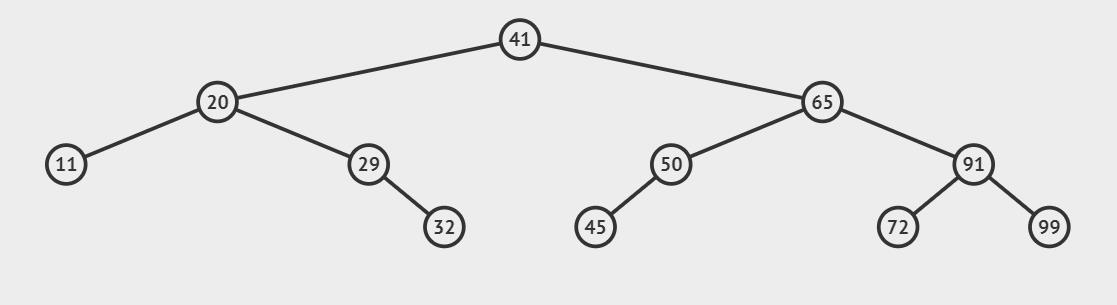
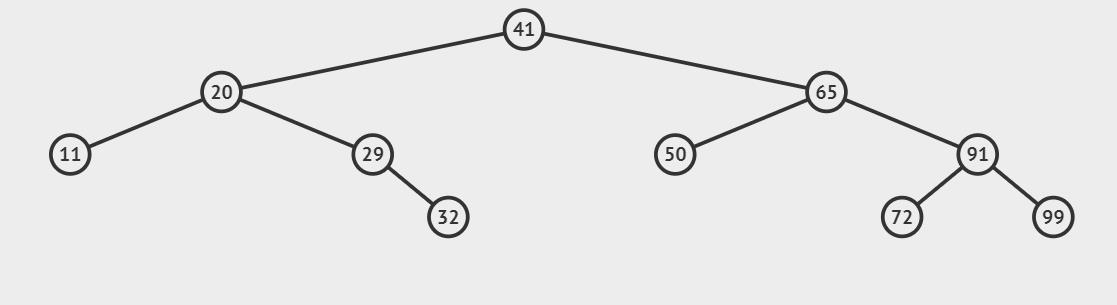 例如要在上面的二叉搜索树中插入一个值为45的节点,根据二叉搜索树的性质查找插入位置:
例如要在上面的二叉搜索树中插入一个值为45的节点,根据二叉搜索树的性质查找插入位置:
与根节点的值进行比较,41 < 45,插入的位置应该在根节点的右边,
与右子树65进行比较, 65 > 45,插入的位置应该在65的左边,
与65的左树50进行比较,50 > 45,插入的位置应该在50的左边
50的左树为空,这就是45应该被插入的位置。
二叉搜索树插入代码实现:
bool Insert(const K& key)
// 根为空
if (_root == nullptr)
_root = new Node(key);
return true;
// 根不为空
// 用parent节点记录要插入节点的父节点
Node* parent = nullptr;
Node* cur = _root;
while (cur)
// 根节点的值小于要插入位置的值,去右边找
// 同时记录父节点方便找到插入位置后链接新节点
if (cur->_key < key)
parent = cur;
cur = cur->_right;
// 根节点的值大于要插入位置的值,去左边找
else if (cur->_key > key)
parent = cur;
cur = cur->_left;
else
// 要插入的值已经存在
return false;
cur = new Node(key);
// 将新节点链接
// 如果新节点的值比父节点的值大,根据二叉搜索树性质,它应该在父亲的右边
// 反之在父亲的左边
if (parent->_key < cur->_key)
parent->_right = cur;
else
parent->_left = cur;
二叉搜索树的查找
根据二叉搜索树的性质进行查找,
如果根节点的值等于要查找的值,找到了,
如果根节点的值小于要查找的值,去它的右子树查找,
如果根节点的值大于要查找的值,去它的左子树查找。
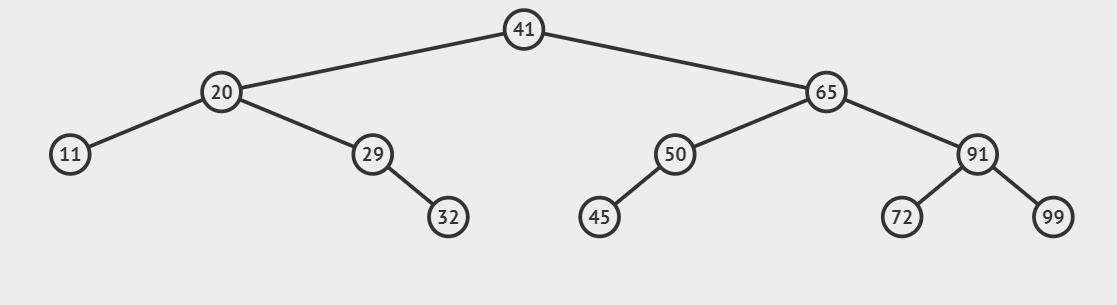
例如在二叉搜索树中查找72
二叉搜索树查找代码实现:
Node* Find(const K& key)
Node* cur = _root;
while (cur)
if (cur->_key < key)
cur = cur->_right;
else if (cur->_key > key)
cur = cur->_left;
else // 找到了返回该节点
return cur;
// 没找到返回空
return nullptr;
二叉搜索树的删除
删除操作较为复杂。
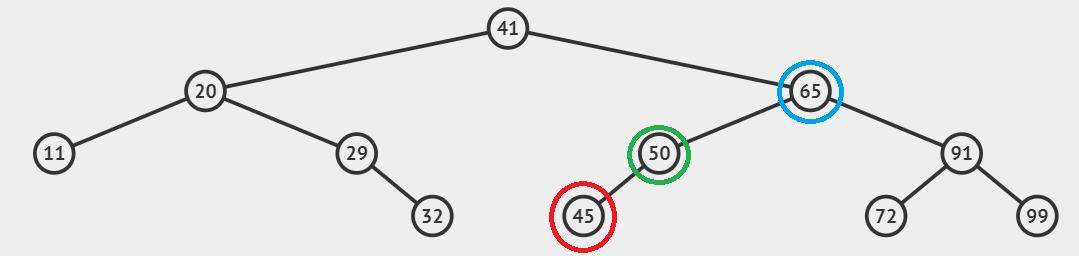
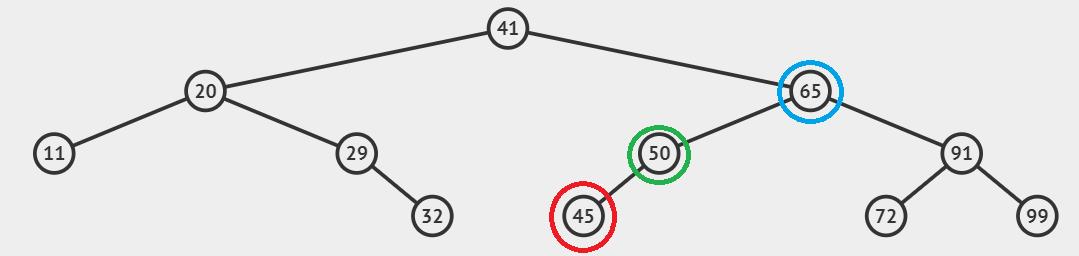
二叉搜索树中的节点无非就三种情况:
叶子节点(红色),
只有左孩子或只有右孩子的节点(绿色),
左右孩子都有的节点(蓝色)。
所以删除也分这三种情况:
1.叶子节点
2.只有一个孩子
3.两个孩子都有
先找到要删除的节点
不同的节点进行不同的删除操作
如果要删除的节点为叶子节点,让它的父亲指向空即可
例如删除叶子节点45
如果要删除的节点有一个左孩子或有一个右孩子(同时说明它的左右指针其中有一个指向空),找到要删除的节点,如果它在父亲的左边,让父亲的左指针指向它的孩子,如果它在父亲的右边,让父亲的右指针指向孩子,把它删除
例如节点50
叶子节点和只有一个孩子节点这两种情况可以算作一种,因为只有一个孩子节点,那它的左或者右指向空,而孩子节点的左右指针都指向空,可以把叶子节点和只有一个孩子的节点用一种逻辑处理。
最后左右孩子都有的节点(例如要删除蓝色65)
根据二叉搜索树的性质节点65的左边一定比65小,节点65的右边一定比65大。可以用左边的最大节点或者右边的最小节点替代它。
因为根据二叉搜索树的性质,左子树小右子树大,
左边的最大节点一定没有右孩子,不然它就不是最大的。
右边的最小节点一定没有左孩子,不然它就不是最小的。
用这两个节点代替要删除的节点,都满足二叉搜索树左子树比根小,右子树比根大的性质
所以这里删除65选择用它的右子树里最小的72代替它。
替代操作在写代码的时候就是把节点72的值赋值给节点65,然后删除节点72。
二叉搜索树删除代码实现:
bool Erase(const K& key)
// 记录下要删除节点的父节点
Node* parent = nullptr;
Node* cur = _root;
while (cur)
// 找到要删除的节点
if (cur->_key < key)
parent = cur;
cur = cur->_right;
else if (cur->_key > key)
parent = cur;
cur = cur->_left;
else
// 要删除的节点只有右孩子或者叶子节点,左边为空
if (cur->_left == nullptr)
if (cur == _root)
_root = cur->_right;
else
// 如果要删除的节点在父亲的左边,让父亲的左边指向它的右
// 如果要删除的节点在父亲的右边,让父亲的右边指向它的右
if (cur == parent->_left)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
delete cur;
else if (cur->_right == nullptr) // 只有左孩子,右边为空
if (cur == _root)
_root = cur->_left;
else
if (cur == parent->_left)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
delete cur;
else // 左右孩子都有
Node* minRightParent = cur; //记录右子树最小节点的父节点
Node* minRight = cur->_right; //记录右子树最小节点
while (minRight->_left) // 找到右子树最小节点
minRightParent = minRight;
minRight = minRight->_left;
// 将右子树最小节点的值赋值给要删除节点的值
cur->_key = minRight->_key;
// 改变最小节点的父节点指针指向
if (minRight == minRightParent->_left)
minRightParent->_left = minRight->_right;
else
minRightParent->_right = minRight->_right;
// 删除右边最小节点
delete minRight;
return true;
// 没有要删除的节点
return false;
二叉搜索树的应用
1.K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
- 以单词集合中的每个单词作为key,构建一棵二叉搜索树
- 在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
2.KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。 该种方式在现实生活中非常常见:比如英汉词典就是英文与中文的对应关系, 通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;再比如统计单词次数, 统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。
比如:实现一个简单的英汉词典dict,可以通过英文找到与其对应的中文,具体实现方式如下:
- <单词,中文含义>为键值对构造二叉搜索树,注意:二叉搜索树需要比较,键值对比较时只比较Key
- 查询英文单词时,只需给出英文单词,就可快速找到与其对应的key
二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
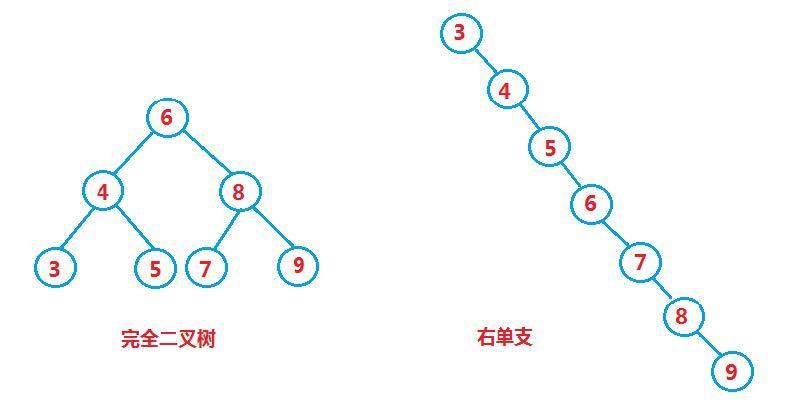
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:
log
2
N
\\log_2N
log2N
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:
N
2
\\fracN2
2N
完整代码
二叉搜索树实现
完整代码包括k模型,kv模型的实现,插入、删除、查找的递归实现。
以上是关于二叉搜索树的主要内容,如果未能解决你的问题,请参考以下文章