MySQL
Posted 小田mas
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL相关的知识,希望对你有一定的参考价值。
数据库的分类

mysql简介

常用sql命令 desc显示表的结构
创建表 sql语句
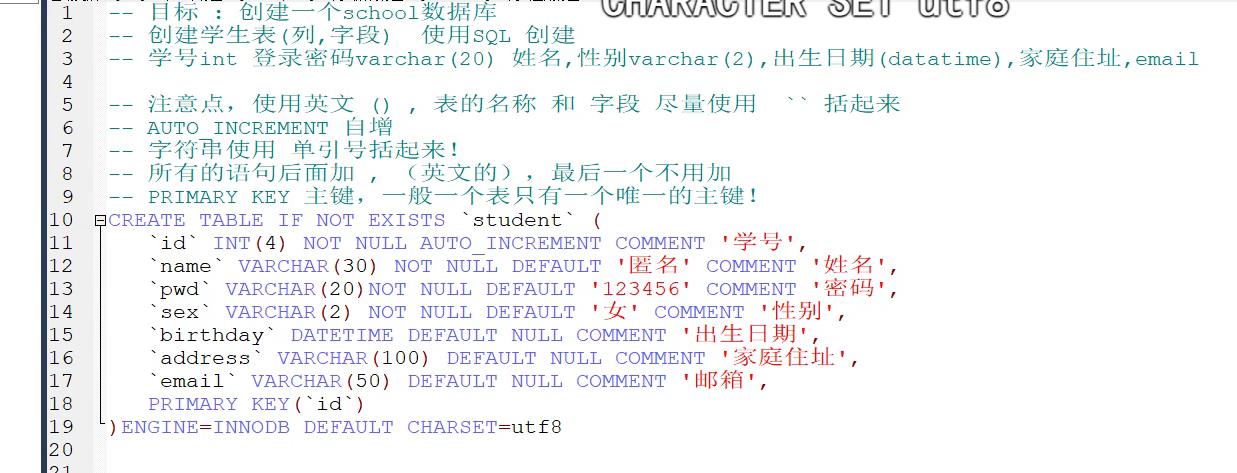
建表格式

列-null

拓展

列-时间日期

列-数值类型

列-字符串

命令

sc delete mysql--清空服务
字段名最好加上 飘

引擎
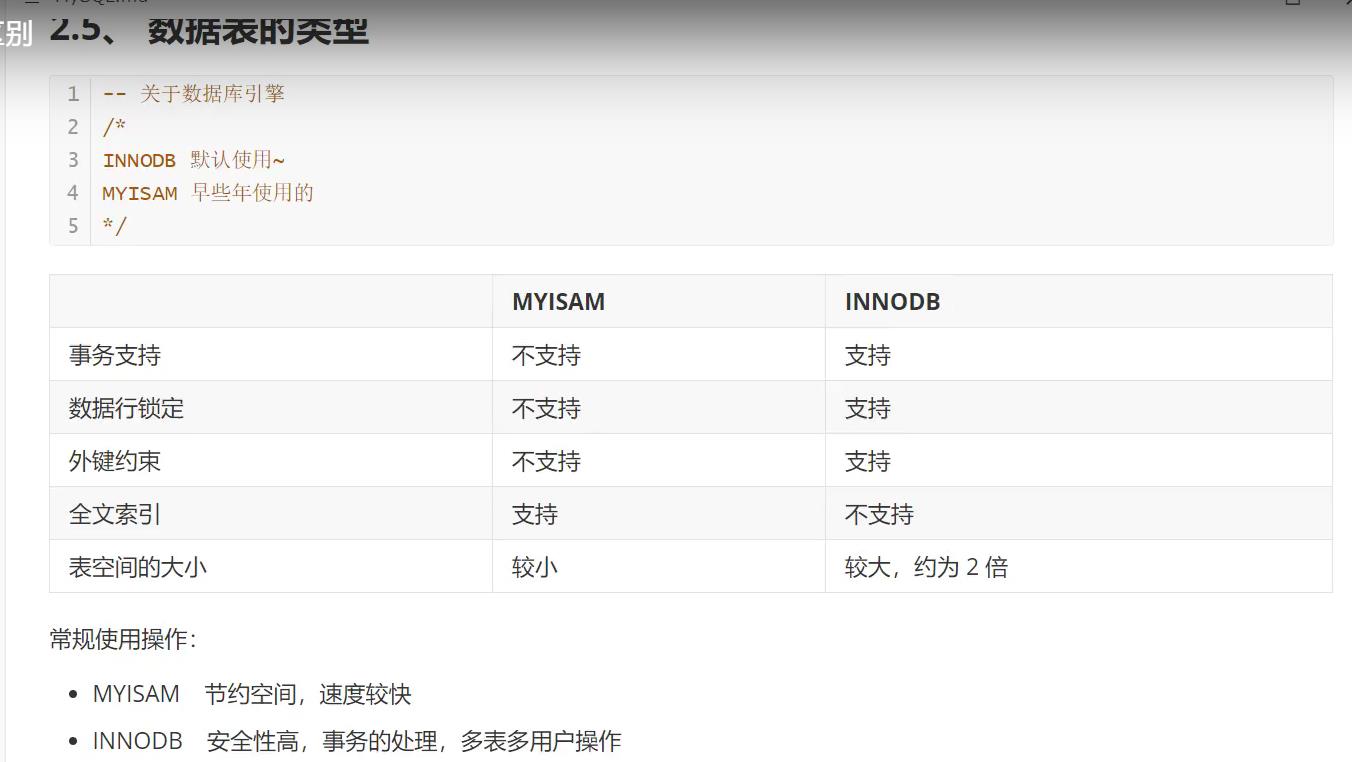
一些字段属性

一点小技巧
show create database student--查看创建数据库的语句
show create table student --查看创建表的语句
desc student --显示表的结构
所有的数据库文件都存在在data文件夹目录下,一个文件夹就对应一个数据库。
本质还是文件的存储。
MySQL引擎在物理文件下的区别:
- InnoDB在数据库表中只有一个*.frm文件。以及上级目录下的ibdata1文件
- MyISAM对应文件
- *.frm表结构的定义文件
- *.MYD数据文件
- -*.MYI 索引文件
设置数据库的字符集编码
- charset = utf8
- 不设置的话会是mysql的默认编码集,为Latin1,不支持中文。
- 在my.ini中配置默认的编码 char
在这里插入代码片acter-set-server = utf8 - 还是建议自己在建表的时候写
修改表名
- ALTER TABLE 旧表名 RENAME as 新表名
增加字段
- ALTER table 表名 add 字段名 列属性
alter student add age int(11)
修改表的字段(重命名,修改约束)
-
alter table teacher modify age varchar(11)--修改约束 -
alter table teacher change age age1 int(1)--字段重命名 -
change用来字段重命名,不能修改字段类型和约束;
-
modify不能用来字段重命名,只能能修改字段类型和约束。
删除表的字段
alter table teacher drop age --删除表的字段
删除表
drop table if exists teacher --如果表存在再删除
所有的创建和删除操作尽量加上判断,以免报错。
注意点
- 字段名使用 飘包裹
- 注释-- /**/
- sql关键字大小写不敏感,建议写小写
MySQL数据管理
外键(了解)

删除有外键关系的表的时候,必须要删除引用别人的表(从表),再删除被引用的表(主表)。
创建表成功之后可以这样做。
以上的外键都是物理外键,数据库级别的外键,不建议使用!(避免数据库过多造成困扰)。
最佳实践
- 数据库就是单纯的表,用来存数据,只有行(数据)和列(属性、字段)
- 我们想使用多张表的数据,用程序去实现。
为什么不用外键?
- 每次做DELETE或者UPDATE都必须考虑外键,会导致开发的时候很痛苦,测试数据极为不方便。

DML(数据库管理语言)语言(增删改,要求全部记住)
数据库数据管理,数据操作。
- insert
- update
添加
insert into 表名([字段名1,字段名2,字段名3])values('值1',‘值2’,。。。)
insert int 'grade' ('gradename') values('大四')
--由于主键自增我们可以省略(如果不写表的字段,他就会一一匹配),一搬写插入语句,一定要将数据跟字段一一对应
--插入多个字段
insert into 'grade'('gradename') values('大二'),('大一')
insert into 'grade'('gradename','pwd') values('大二','aaaaaaa')

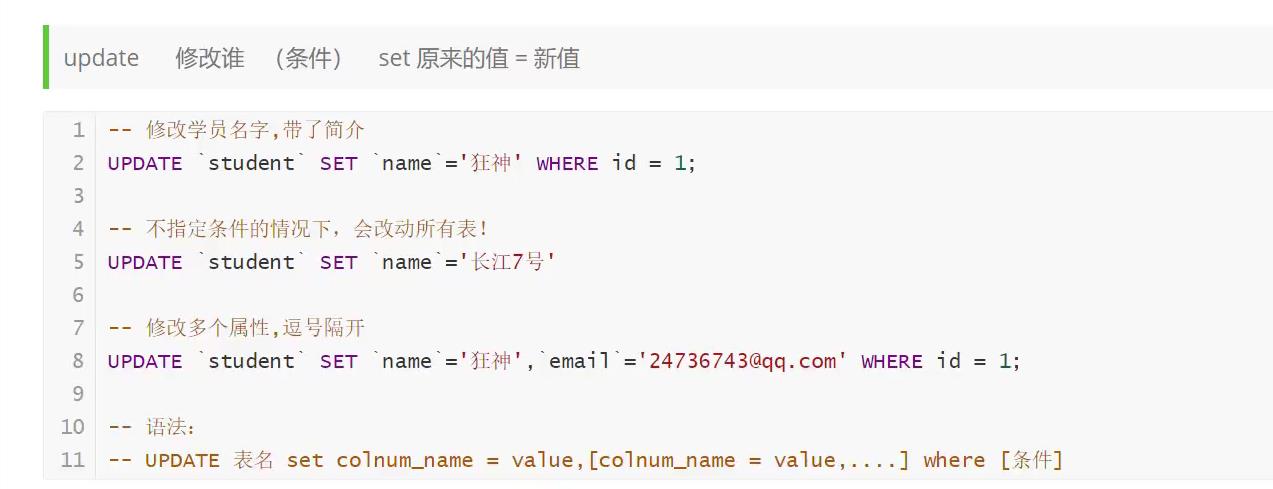
修改
Update 'student' set 'name' = 'saisia' where id =1;


删除
Delete from table where column = '1';--不会影响自增
TRUNCATE命令,TRUNCATE table 完全清空一个数据库表,表的结构和索引约束不会变--自增会归零
delete 和 TRUNCATE 区别
- 相同点:都能删除数据,都不会删除表结构
- 不同点:TRUNCATE 重新设置 自增列 计数器会归零
- TRUNCATE 不会影响事务
Delete删除的问题,重启数据库,现象
- InooDB 自增列会从一开始(存在内存当中的,断电即失)
- MyISAM 继续从上一自增量开始(存在文件中的,不会丢失)
- 好像是delete的问题,8.0已经解决了
DQL查询数据
指定字段查询
select contact('姓名:',studentname) as **新名字** from student
as给列名起别名
select distinct 'Studentid' from result
distinct 去重

where
注意not条件的使用

not 示范
select 'StudentNo' from student where not 'StudentNo' = 1000;
like+ %(0到任意一个字符)+ _ (1个字符)
select 'StudentNo' from student where 'Studentname' like '刘%'--可以查询出姓刘的同学的学号
select 'StudentNo' from student where 'Studentname' like '刘_'--可以查询出姓刘的同学并且姓名为2个字的学号
in多选
select 'StudentNo' from student where 'StudentNo' in (1001,1002,1003)--可以查询出姓刘的同学并且姓名为2个字的学号
Mysql 7种join
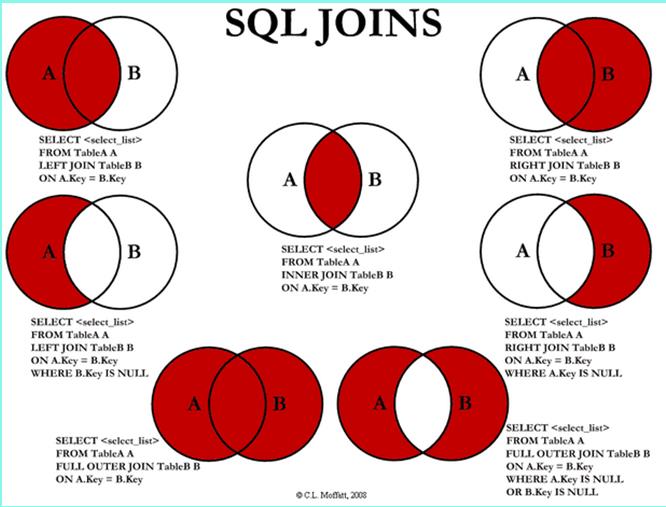
right join,left join,inner join



- 注意,左右表的区分是在写的时候的看把表写在了左边还是右边。
- join (连接的表) on (判断的条件) --连接查询
- where --等值查询
自连接
- 在同一个表中出现诸如父类、子类的内容,然后将表进行分割
分页和排序
关键词 order by、limit
-
排序 ,ASC升序,DESC降序

-
分页,为了缓解数据压力,给人更好的体验。但也有瀑布流诸如图片搜索,痘印等。
语法:
- limit (n-1)*pagesize,pagesize 表示第n页。
-
只是单纯的爱狂神罢了。
子查询
我的理解就是where里面套where。

连接、子查询的区别

梦回大二

MySQL常用函数
1. ABS() 求绝对值
2. Ceiling() 向上取整
3. FLoor() 向下取整
4. Rand() 返回0到1之间的随机数
5. Sign() 返回一个数的符号,整数返回1,负数返回-1,0是0
6. char_length() 字符串长度
7. concat() 拼接字符串
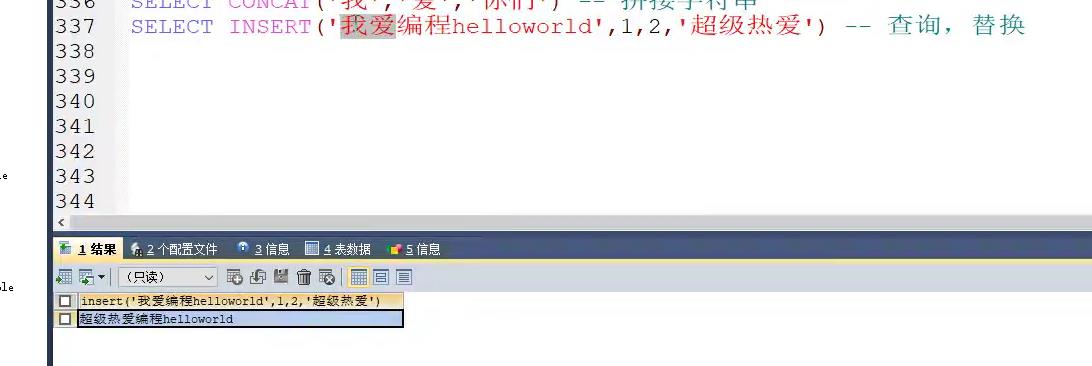
8. insert() 插入,替换
insert(str,pos,len,str1);--将str中pos位置开始长度为len的字符串替换为str1.
9. upper() lower() 转换大小写
10. instr(str,char) 返回字符出现在字符串中的位置
11. replace (str,str1,str2) 替换指定出现的字符串
12. substr(源字符串,截取的位置,截取的长度)截取字符串
13. reverse(str) 反转字符串
聚合函数
- count()
- avg()
- sum()
要求明确
- count(1),count(),count(字段名)的区别?
- count(列名),会忽略所有的null值;
- count(*),不会忽略null,本质是计算行数;
- count(1),不会忽略所有的null值,本质是计算行数。
- 对于主键的时候,用count(字段名)更快。
where后的表达式不允许聚合函数
分组和过滤
group by 和 having
- where 是过滤之前筛选,having是过滤之后筛选
示例:

数据库级别的MD5加密算法
MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。
在插入的时候就要加密
insert into tempalte values('1','243',MD5('123456'));
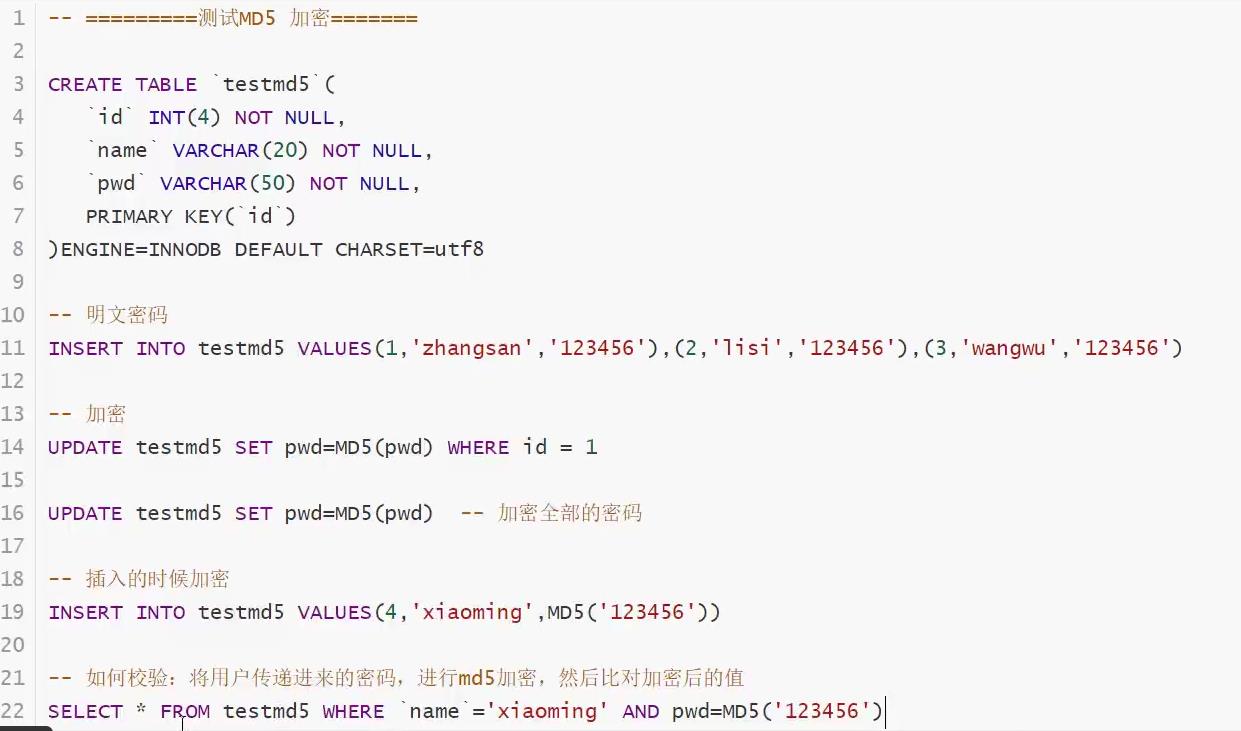
主要就是需要校验。
select小结
- 在书写语句的时候一定要注意顺序: select 去重 from 表(表和字段可以采用as取别名) left/inner/right
join 要连接的表 on 等值判断 where 具体的值,判断 group by 指定结果按哪几个字段来分组 having
过滤分组的记录满足的次要条件 order by 指定查询记录按一个或多个进行排序 limit
将记录按起始位置,指定页数来进行分页
ACID
ACID数据库事务正确执行的四个基本要素的缩写
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
- 原子性(Atomicity)要么都成功,要么都失败。
- 一致性(consistency)事务前后的数据完整性要保持一致。
- 隔离性(Isolation)多个用户访问数据库时,数据库为每一个用户开启的权限不能被其他事务所干扰。
- 持久性(durability)事务一旦提交不可逆,被持久化到数据库中。
隔离导致的一些问题: - 脏读 指的是一个事务读取了其他事务未提交的数据。
- 不可重复读 在一个事务内读取表的某行数据,多次读取的结果不同。(这个不一定是错误,可能是某些场合不对)。
- 虚度(幻读)指在一个事务内读取到了别的事物插入的数据,导致前后读取不一致。

decibal(9,2)表示数值为9位数,其中小数位是两位。
可以从这里理解一下自增的含义,在最后插入数据的时候可以不需要插入相应的值,会自增。
- 关闭自动事务的提交
- 开始一个事务
- 具体操作,执行一组事务。
- 成功提交
- 失败回滚
- 回复自动事务的提交

其中navicat中还需要flush privilege才可以执行相应的操作。
并且需要一个一个地执行。
索引
索引是帮助MySQL高校获取数据的数据结构。
索引的分类
- 主键索引 唯一的标识,主键不能重复,只能有一个列作为主键,表中只能有一个主键索引
- 唯一索引 unique,避免重复的数据出现,例如个人账号,一个表中可以有多个列作唯一索引
- 常规索引 key/index ,默认的
- 全文索引 fulltext,在特定的数据库引擎下才有,以前
show index from student--显示索引
alter table school.student add fulltext index 'schoolname'('schoolname')--(索引名)列名
通过explain分析语句的执行情况

创建索引

索引的原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表不需要加索引
- 索引一般加载常用来查询的字段上
索引的数据结构
Btree:InnoDB的默认数据结构
%表示所有的ip都可以访问这个主机


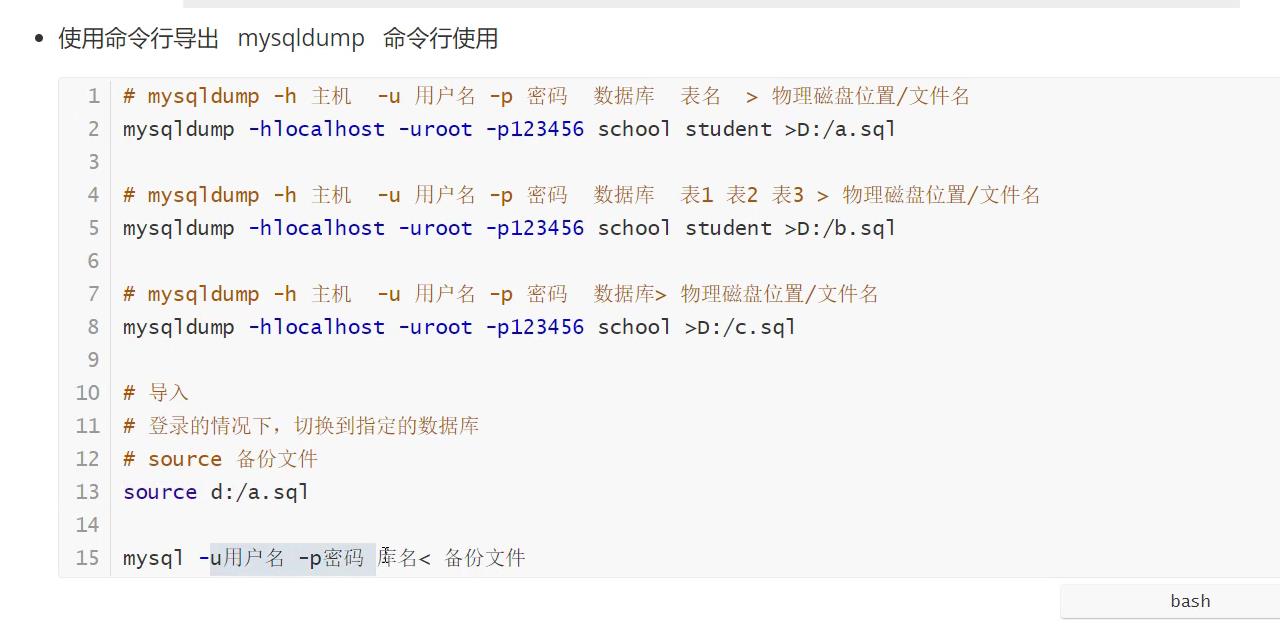
数据库的备份
规范数据库的设计
数据库三大范式
-
第一范式(1NF) : 列不可再分;
通常一个字段包含多个内容时,不符合第一范式。 -
第二范式(2NF):满足第一范式的基础上,属性完全依赖于主键,不存在对主键的部分依赖;
容易出现在联合主键的情况下,比如订单号和产品为主键,而订货量只取决于订单号,与产品无关。 -
第三范式(3NF):满足前两个范式的基础上,属性不依赖于其它非主属性 属性直接依赖于主键,不存在传递依赖。
比如学生信息中有可能会存在,教师姓名,教师年龄,教师住址,此时就出现了传递依赖,教师年龄,教师住址通过教师姓名确认,而不通过学生学号这一主键确认。拆拆拆,量力而行!!!
规范化与性能的问题
关联查询的表不能超过三张表。
- 在考虑商业话的目标时,数据库的性能就更为重要
- 在规范性能问题的时候,需要适当的考虑一下规范性
- 故意给表增加一些冗余的字段,使之从多表查询变为单表查询
- 故意增加一些计算列,select count时,相应的数据就加一,从大数据量降低为小数据量的查询,索引树比较占问题。
JDBC和数据库驱动

应用程序和数据库之间的“连接”
1、JDBC
SUN公司为了简化开发人员(对数据库的统一)操作,提供了一个规范(java操作数据库的规范) JDBC,这些规范的实现由具体的厂商去做。
对于开发人员来说,掌握JDBC的接口的操作即可。
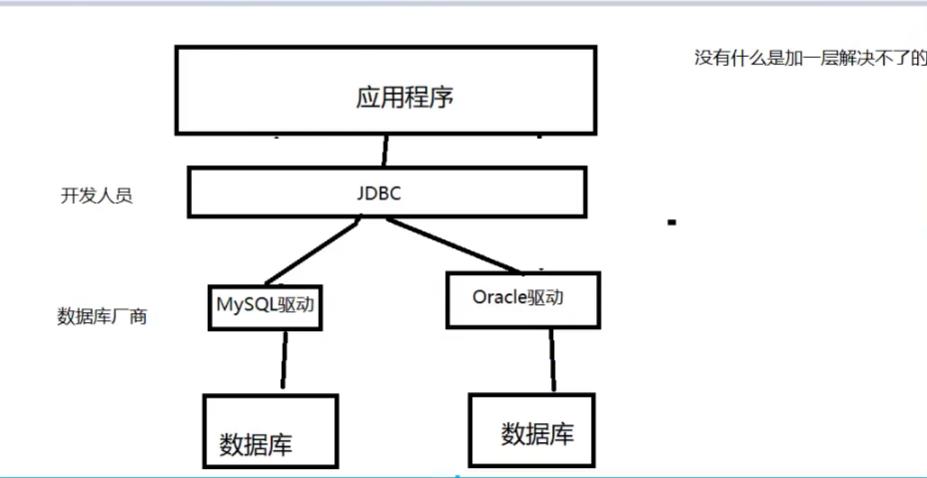
用到java.sql、javax.sql、还要用到数据库驱动包mysql-connector-java-$.1.47.jar。
想要包按小数点分开的展开,点击项目栏的齿轮的compact middle packages
mysql8.0的写法 Class.forName(“com.mysql.cj.jdbc.Driver”);
package com.kuang.study;
import java.sql.*;
//第一个JDBC程序
public class JDBC
public static void main(String[] args) throws ClassNotFoundException, SQLException
//1.加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");//固定写法加载驱动
//2.用户信息和URl
String url = "jdbc:mysql://localhost:3306/mysql?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8";
String username = "root";
String password = "123456";
//3.连接成功,数据库对象 connection代表数据库
Connection connection=DriverManager.getConnection(url,username,password);
//4.执行sql的对象 statement 执行sql的对象
Statement statement = connection.createStatement();
//5.执行sql的对象 去 执行 sql,可能存在结果,查看返回结果
String s = "SELECT * from user";
ResultSet resultSet = statement.executeQuery(s);//返回的结果集,结果集中封装了我们全部的查询出来的结果
while(resultSet.next())
System.out.println("Host="+resultSet.getObject("Host"));
System.out.println("User="+resultSet.getObject("User"));
System.out.println("Select_priv="+resultSet.getObject("Select_priv"));
//System.out.println("id="+resultSet.getObject("id"));
//6.释放连接
resultSet.close();
statement.close();
connection.close();
步骤总结:
1、加载驱动
2、连接数据库DriverManager
3、获得sql执行的对象 Statement
4、获得返回的结果集
5、释放连接
DriverManager
Class.forName("com.mysql.cj.jdbc.Driver");//固定写法加载驱动
Connection connection=DriverManager.getConnection(url,username,password);
//connection代表数据库
//数据库设置自动提交 connection.setAutoCommit();
//事务提交 connection.commit();
//事务回滚 connection.rollback();
URL
String url = "jdbc:mysql://localhost:3306/mysql?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8"
//mysql端口号默认是3306
//jdbc:mysql://主机地址:端口号/数据库名?参数1&参数2&参数3
//oracle端口号默认是1521,oracle 里面全是表
//jdbc:oracle://thin:@localhost/1521:sid
Statement执行sql的对象,PrepareStatement执行sql的对象
String s = "SELECT * from user";//编写sql
statement.executeQuery();//查询操作,返回ResultSet
statement.execute();//执行任何sql,效率低
statement.executeUpdate();//更新、插入、删除都是用这个,返回一个受影响的行数
ResultSet查询的结果集:封装了所有的查询结果
获得指定的数据类型
resultSet.getObject();//在不知道列类型的情况下使用
resultSet.getString();//如果知道列的类型就使用指定的类型
resultSet.getArray();
。。。
resultSet.beforeFirst();//移动到最前面
resultSet.afterLast();//移动到最后面
resultSet.next();//移动到下一个数据
resultSet.previous();//前一行
resultSet.absolute(row);//移动到指定的row行
释放资源
resultSet.close();
statement.close();
connection.close();//不要浪费资源
Statement对象
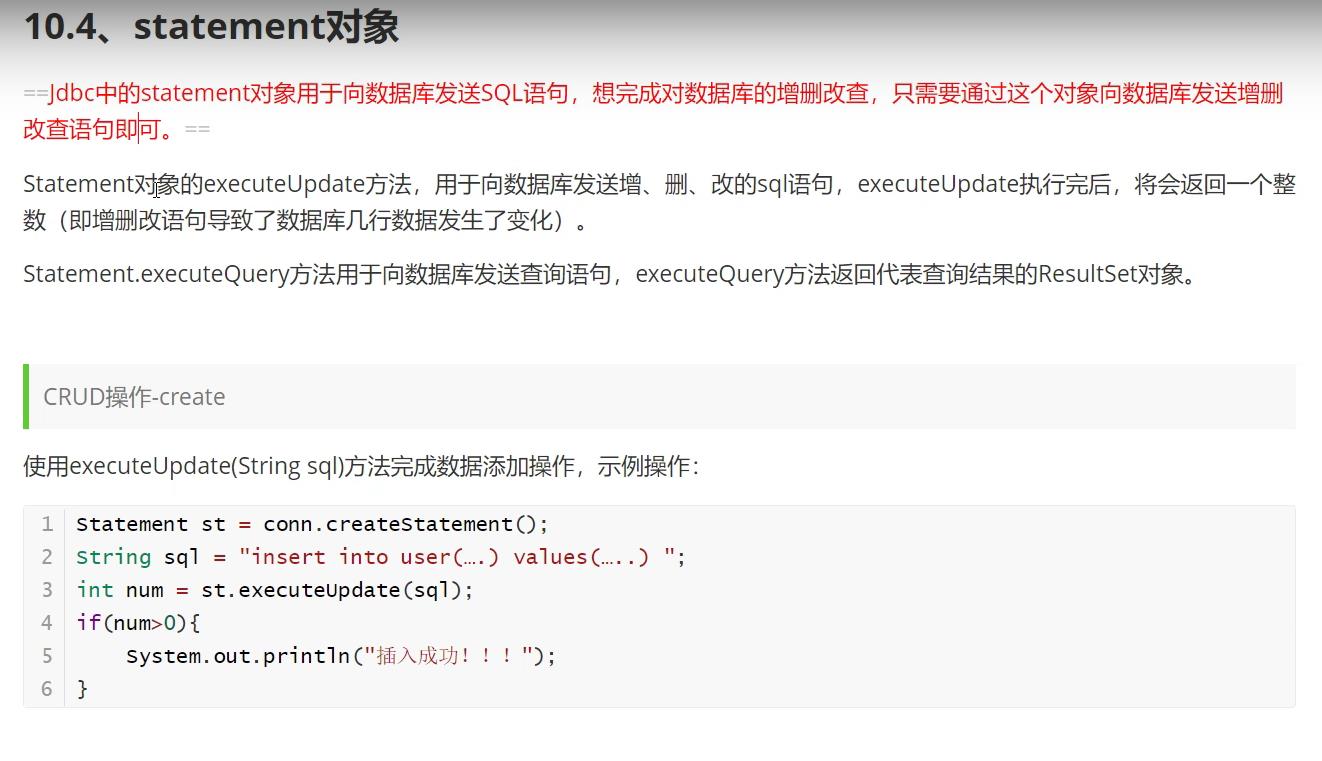


增、删、改都是使用的对应的update语句。

注意的是查,用的query()语句。
代码实现,提取工具类
package com.kuang.lesson2.utils;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class Jdbcutils
private static String driver = null;
private static String url = null;
private static String username = null;
private static String password = null;
//读取配置文件
static
try
InputStream in = Jdbcutils.class.getClassLoader().getResourceAsStream("db.properties");
Properties properties = new Properties();
properties.load(in);
driver = properties.getProperty("driver");
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
//1.驱动只用加载一次
Class.forName(driver);
catch (IOException | ClassNotFoundException e)
e.printStackTrace();
//获取连接
public static Connection getConnection() throws SQLException
return DriverManager.getConnection(url,username,password);
//释放连接
public static void release(Connection conn, Statement st, ResultSet rs) throws SQLException
if(rs!=null)
rs.close();
if(st!=null)
st.close();
if(conn!=null)
conn.close();
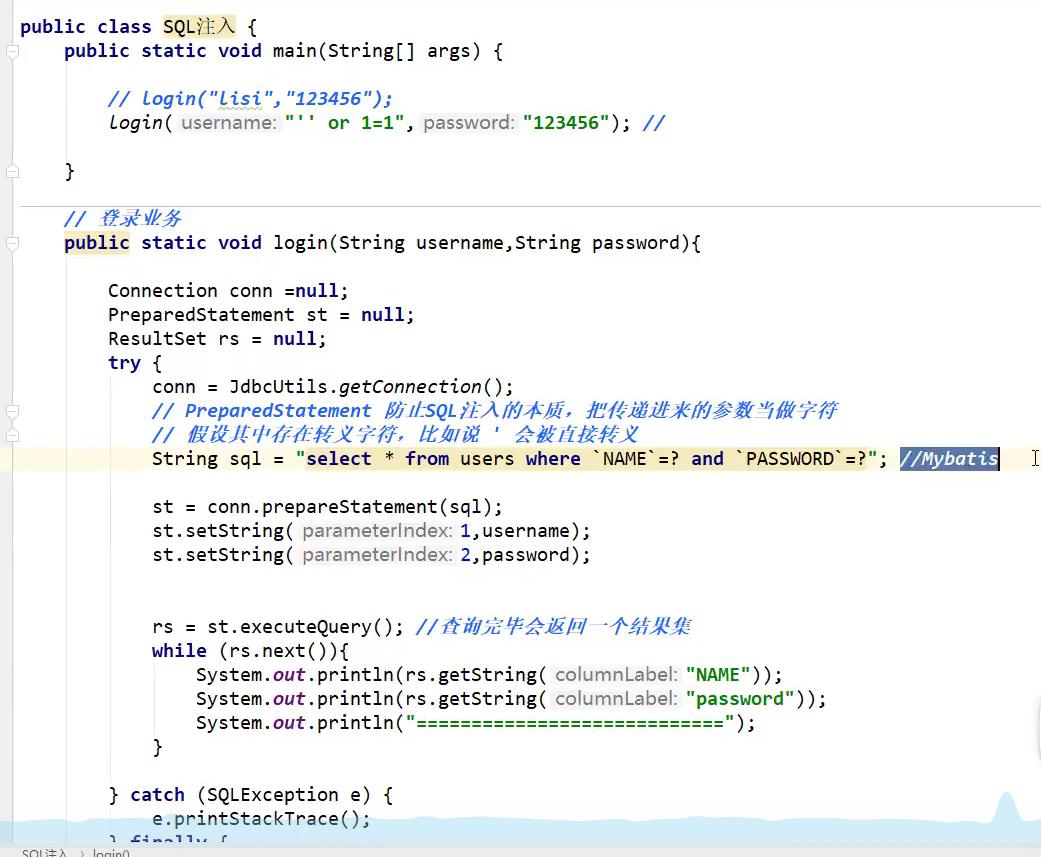
SQL注入问题
sql存在漏洞,会被攻击导致数据泄露,or

PrepareStatement对象,最重要的区别是防止sql诸如并且效率更高。
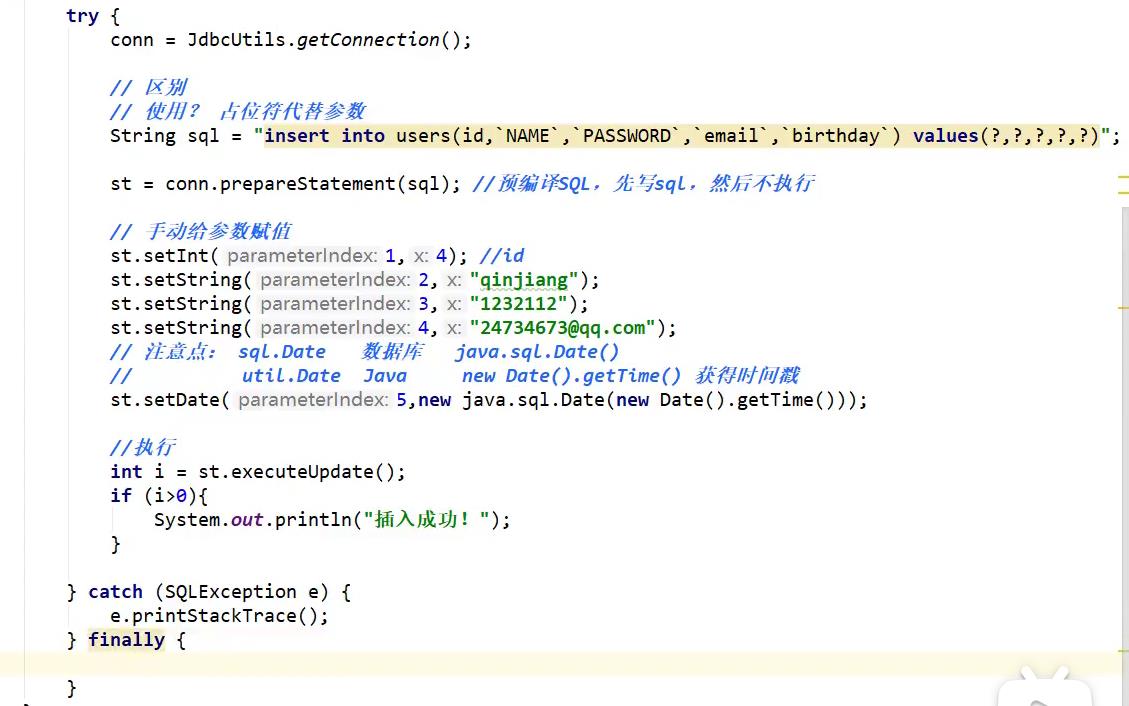
prepareStatement防注入,会把’这样式的字符转义
JDBC操作事务
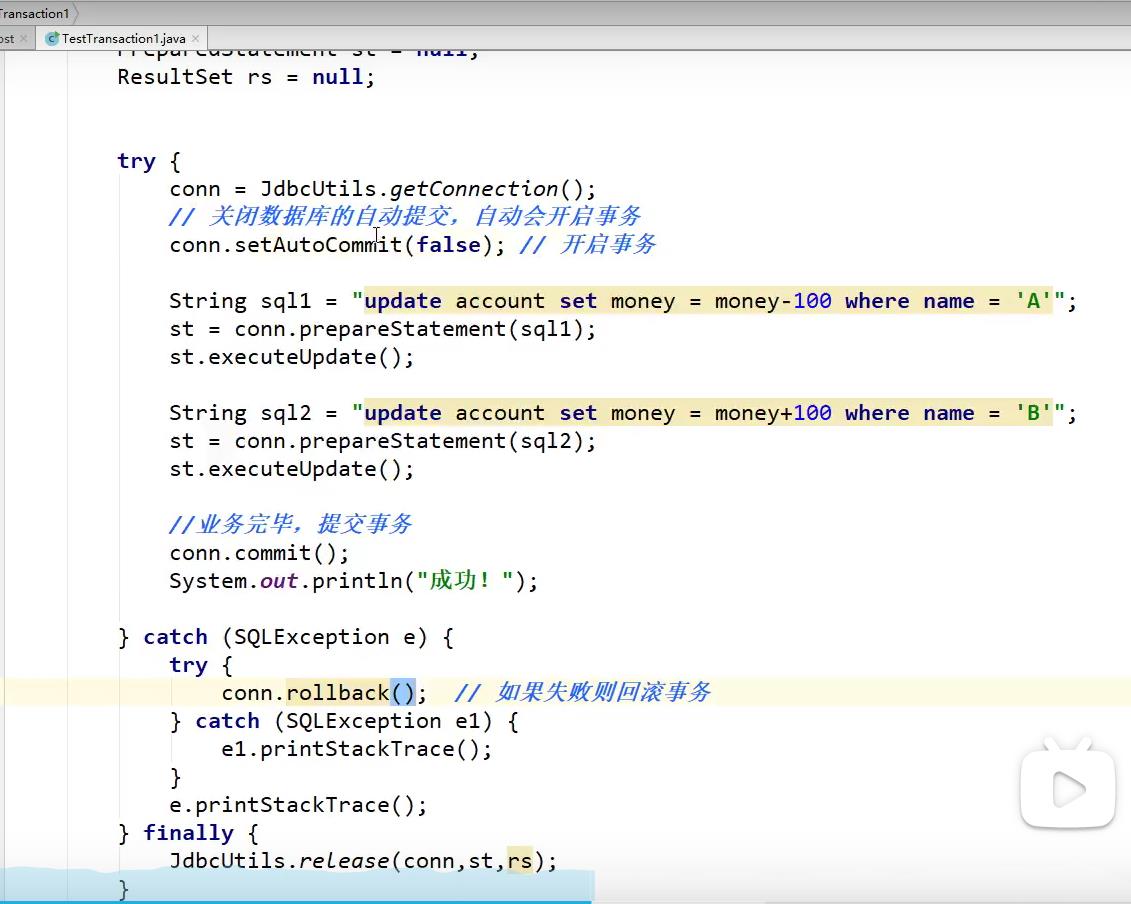
如果失败,自动回滚,不需要写语句。
其中prepareStatement没有用占位符,setAutocommit(true)也没有写。
代码实现

数据库连接池
数据库的连接-释放是非常耗费资源的。
池化技术:预先准备一些资源,来了就连接准备好的。
举个栗子,银行开门-服务-关门,池化技术相当于在开门后加了几个业务员,然后业务员就相当于准备好的资源。
最小连接数:
最大连接数:
等待超时:
编写连接池,实现一个接口DataSource
开源数据源实现
DBCP
C3P0
Druid:阿里巴巴
使用了这些数据库连接池之后,我们在项目开发中就不需要编写连接这些数据库的代码了!(我的内心os:????)
DBCP
#连接设置 这里面的名字是DBCP定义好的
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8
username=root
password=123456
#!-- 初始化连接 --
initialSize=10
#最大连接数量
maxActive=1000
#!-- 最大空闲连接 --
maxIdle=20
#!-- 最小空闲连接 --
minIdle=5
#!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 --
maxWait=60000
#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:【属性名=property;】
#注意:user 与 password 两个属性会被明确地传递,因此这里不需要包含他们。
connectionProperties=useUnicode=true;characterEncoding=UTF8
#指定由连接池所创建的连接的自动提交(auto-commit)状态。
defaultAutoCommit=true
#driver default 指定由连接池所创建的连接的只读(read-only)状态。
#如果没有设置该值,则“setReadOnly”方法将不被调用。(某些驱动并不支持只读模式,如:Informix)
defaultReadOnly=
#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。
#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
defaultTransactionIsolation=READ_UNCOMMITTED
package com.kuang.lesson2.utils;
import org.apache.commons.dbcp.BasicDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.*;
import java.util.Properties;
public class Jdbcutils_DBCP
private static DataS以上是关于MySQL的主要内容,如果未能解决你的问题,请参考以下文章