NNI 示例 BatchTuner
Posted 甘木甘木
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NNI 示例 BatchTuner相关的知识,希望对你有一定的参考价值。
NNI 小白入门
使用最简单的BatchTuner进行演示
参考本博客前,需要先浏览过NNI的官网,了解大致流程
GridSearch 参考另一篇 https://blog.csdn.net/weixin_44110392/article/details/113257885
运行代码框架
-
a simple implement of linear regression
不用在意线性回归的实现
-
假如需要调参的是 batch_size, epochs_number, learning_rate
-
为了方便演示,假设上面三个参数从给定的范围中选取,所以使用BatchTuner
-
参数范围:
epochs = [i for i in range(10, 20)] batch_sizes = [i for i in range(10, 20, 5)] learning_rates = [i*0.001 for i in range(1,3)]
-
-
-
NNI配置
config.yml
NNI 环境配置
- trialConcurrency: 并发数量
- maxTrialNum: 调参的参数组的总数。例如上面给出的10*2*2=40
- Trail-command: 每一次执行程序的命令
authorName: default
experimentName: example_Linear_Regression
trialConcurrency: 5
maxExecDuration: 1h
maxTrialNum: 40
#choice: local, remote, pai
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
builtinTunerName: BatchTuner
trial:
command: python3 linear_regression.py
codeDir: .
gpuNum: 0
search_space.json
参数的搜索空间
本例中使用BatchTuner,所以就是不同的参数组成的list
- 下面的写法是固定的,默认batchTuner只能这样写,能更改的只有_value中的内容(类型必须是list)
- 下面value中的list省略了一些参数(太长不好看)
"combine_params":
"_type": "choice",
"_value": ["epochs": 10, "batch_size": 10, "learning_rate": 0.001, "epochs": 10, "batch_size": 10, "learning_rate": 0.002, "epochs": 10, "batch_size": 15, "learning_rate": 0.001"learning_rate": 0.002]
执行文件
- main函数
- log是为了方便debug
- nni.get_next_parameter()得到tuner中的下一组参数
- 由于我写的参数是用dict的形式存储,所以我先生成了一组默认参数然后用读取到的参数update
- train函数
- 要在开始的时候用读入的参数初始化parameters
- 最后要report_final_reault(),这里读入的数值会在最终的交互界面上画图
- 其余函数与NNI无关
import torch as t
import numpy as np
import random
import nni
import logging
LOG = logging.getLogger('linear_regression')
np.random.seed(1)
random.seed(1)
def generate_date(true_w, true_b, num_examples):
'''
generate synthetic data
'''
x = np.random.normal(0, 1, (num_examples, len(true_w)))
y = np.dot(x, true_w) + true_b
# add noise
y += np.random.normal(0, 0.01, y.shape)
return t.Tensor(x), t.Tensor(y)
def data_iter(batch_size, features, labels):
'''
reading data iteration by iteration
'''
num_examples = len(labels)
indices = list(range(num_examples))
# examples are read at random
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = np.array(indices[i:min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
def loss_func(y_hat, y):
'''
square loss
'''
return (y_hat - y)**2 / 2
def sgd(params, lr, batch_size):
'''
minibatch stochastic gradient descent
'''
with t.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
def linreg(X, w, b):
"""The linear regression model."""
return t.matmul(X, w) + b
def train(ARGS, features, labels):
lr = ARGS['learning_rate']
num_epochs = ARGS['epochs']
net = linreg
loss = loss_func
batch_size = ARGS['batch_size']
w = t.Tensor([1, 1])
w.requires_grad_(True)
b = t.Tensor([0])
b.requires_grad_(True)
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # Minibatch loss in `X` and `y`
# Compute gradient on `l` with respect to [`w`, `b`]
l.sum().backward()
sgd([w, b], lr,
batch_size) # Update parameters using their gradient
# with t.no_grad():
# train_l = loss(net(features, w, b), labels)
# print(f'epoch epoch + 1, loss float(train_l.mean()):f')
res_loss = loss(net(features, w, b), labels)
# print(w, b)
loss_mean = res_loss.mean()
nni.report_final_result(float(loss_mean))
def generate_default_params():
"""
Generate default hyper parameters
"""
return "epochs": 10, "batch_size": 10, "learning_rate": 0.003
if __name__ == "__main__":
# generate data
true_w = [2, -3.4]
true_b = 4.2
features, labels = generate_date(true_w=true_w,
true_b=true_b,
num_examples=200)
# get parameters from tuner
RECEIVED_PARAMS = nni.get_next_parameter()
LOG.debug(RECEIVED_PARAMS)
PARAMS = generate_default_params()
PARAMS.update(RECEIVED_PARAMS)
# train
train(PARAMS, features, labels)
结果
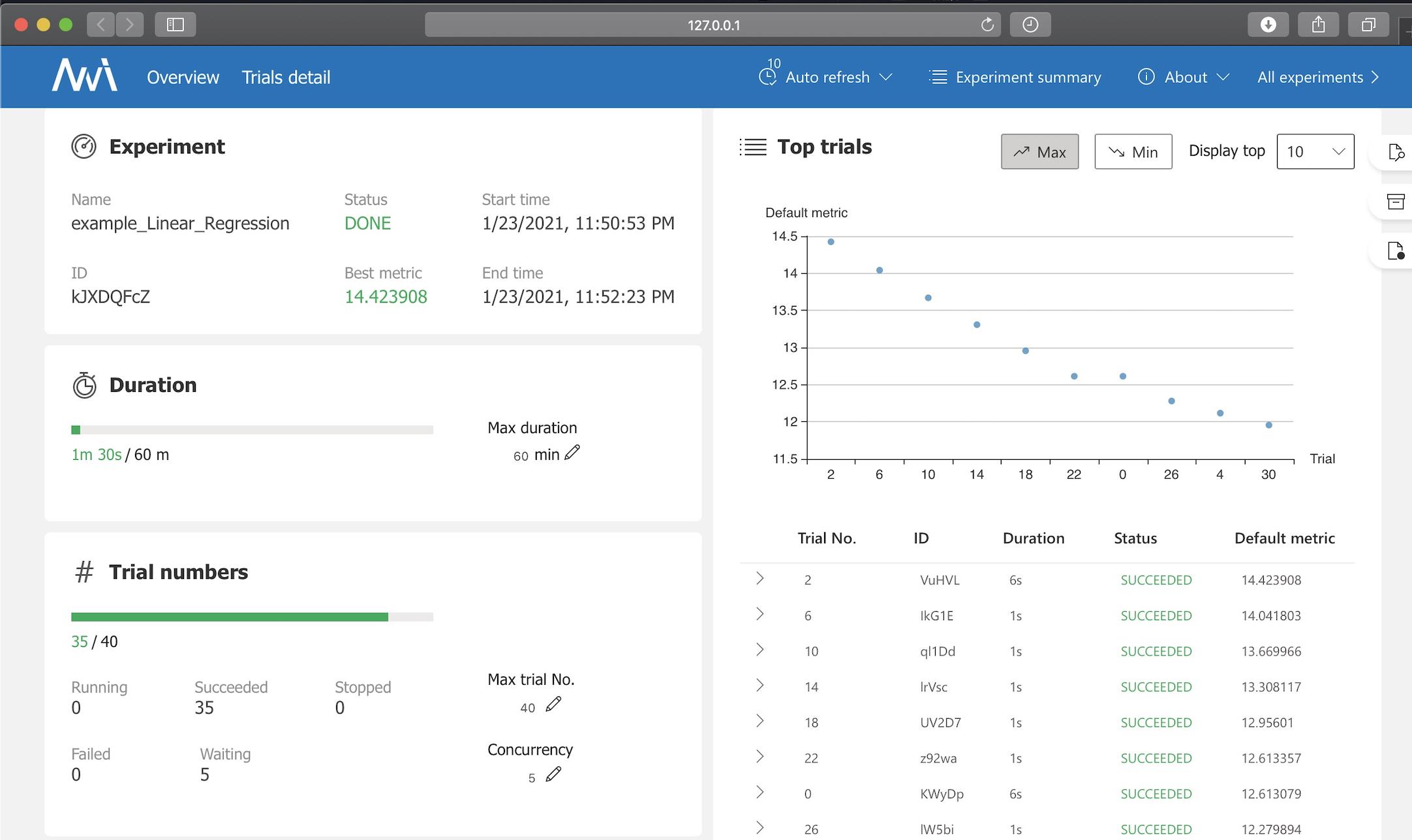
以上是关于NNI 示例 BatchTuner的主要内容,如果未能解决你的问题,请参考以下文章