Java核心组件IO流表层篇
Posted fntp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java核心组件IO流表层篇相关的知识,希望对你有一定的参考价值。
Java核心组件IO流(一)表层篇

在介绍Java的IO流之前先跟大家说明一下,本篇篇幅较长,涵盖整个JavaIO流基础,前小半节是在讲解File类,为后续的JavaIO打下基础,后续的所有篇幅都是在讲解JavaIO流。这是初始篇章,其实我更多的是在想如何能将File类的底层给大家讲清楚,今天难得有机会写写博客,我就将自己学过的Java-File的知识点串起来给大家好好讲讲IO流。JavaIO流的内容我与前面的内容一样,我划分为两个部分,一部分是知识点部分,一部分是底层原理部分,也就是Java的为什么系列。Java的为什么系列目前只写了一个初章:Java的Main方法,后续的话,我会将我所掌握的Java的所有底层细节以及大家所感兴趣的底层细节都拿出来聊一聊,首先,还是回到今天的正题:Java的核心组件IO流!
JavaIO的开端–File的降临
在正式学习JavaIO之前,我们先来看一下JavaIO流的API吧!:


根据上图我们可以很清晰的看到,想要系统性的学习一遍Java的IO海避免不了学习一下FIle类!因为其中的FileWriter与FileReader,FileInputStream与FileOutputStream基本与File有大大小小的关系,所以,我们有必要在学习JavaIO之前引入JavaFIle的概念!
什么是Java中File呢?
Java中的file是一个类称之为File类,File类可以用来实现创建文件,可以对文件进行删除、获取文件所在的目录等功能。以下对Java的File类做一个简单的补充:
在讲解JavaIO流之前,我们先来简单介绍一下,毕竟这是JavaIO流的基础—Java的File类:
Java文件也就是Java的File类,是在Java中描述文件对象的类,泛指存在于System上的文件,其中,file类以抽象的方式代表文件名和目
录路径名。该类主要用于文件和目录的创建、文件的查找和文件的删除等。File对象代表磁盘中实际存在的文件和目录。通过多种构造方
法可以实现创建一个File对象。如:File(File parent, String child);File(String pathname);File(String parent, String child) ;File(URI
uri) ;等,只有通过File类与系统中的文件建立起了关联后,才可以实际地去操作文件!由于这是介绍Java-IO的起点,因此我在此处不
做过多的描述,只做相关定义介绍以及API方法的演示。简单了解一下File类后,继续去了解Java-IO4
File类的相关API方法:
| 序号 | 方法描述 |
|---|---|
| 1 | public String getName() 返回由此抽象路径名表示的文件或目录的名称。 |
| 2 | public String getParent()****、 返回此抽象路径名的父路径名的路径名字符串,如果此路径名没有指定父目录,则返回 null。 |
| 3 | public File getParentFile() 返回此抽象路径名的父路径名的抽象路径名,如果此路径名没有指定父目录,则返回 null。 |
| 4 | public String getPath() 将此抽象路径名转换为一个路径名字符串。 |
| 5 | public boolean isAbsolute() 测试此抽象路径名是否为绝对路径名。 |
| 6 | public String getAbsolutePath() 返回抽象路径名的绝对路径名字符串。 |
| 7 | public boolean canRead() 测试应用程序是否可以读取此抽象路径名表示的文件。 |
| 8 | public boolean canWrite() 测试应用程序是否可以修改此抽象路径名表示的文件。 |
| 9 | public boolean exists() 测试此抽象路径名表示的文件或目录是否存在。 |
| 10 | public boolean isDirectory() 测试此抽象路径名表示的文件是否是一个目录。 |
| 11 | public boolean isFile() 测试此抽象路径名表示的文件是否是一个标准文件。 |
| 12 | public long lastModified() 返回此抽象路径名表示的文件最后一次被修改的时间。 |
| 13 | public long length() 返回由此抽象路径名表示的文件的长度。 |
| 14 | public boolean createNewFile() throws IOException 当且仅当不存在具有此抽象路径名指定的名称的文件时,原子地创建由此抽象路径名指定的一个新的空文件。 |
| 15 | public boolean delete() 删除此抽象路径名表示的文件或目录。 |
| 16 | public void deleteOnExit() 在虚拟机终止时,请求删除此抽象路径名表示的文件或目录。 |
| 17 | public String[] list() 返回由此抽象路径名所表示的目录中的文件和目录的名称所组成字符串数组。 |
| 18 | public String[] list(FilenameFilter filter) 返回由包含在目录中的文件和目录的名称所组成的字符串数组,这一目录是通过满足指定过滤器的抽象路径名来表示的。 |
| 19 | public File[] listFiles() 返回一个抽象路径名数组,这些路径名表示此抽象路径名所表示目录中的文件。 |
| 20 | public File[] listFiles(FileFilter filter) 返回表示此抽象路径名所表示目录中的文件和目录的抽象路径名数组,这些路径名满足特定过滤器。 |
| 21 | public boolean mkdir() 创建此抽象路径名指定的目录。 |
| 22 | public boolean mkdirs() 创建此抽象路径名指定的目录,包括创建必需但不存在的父目录。 |
| 23 | public boolean renameTo(File dest) 重新命名此抽象路径名表示的文件。 |
| 24 | public boolean setLastModified(long time) 设置由此抽象路径名所指定的文件或目录的最后一次修改时间。 |
| 25 | public boolean setReadOnly() 标记此抽象路径名指定的文件或目录,以便只可对其进行读操作。 |
| 26 | public static File createTempFile(String prefix, String suffix, File directory) throws IOException 在指定目录中创建一个新的空文件,使用给定的前缀和后缀字符串生成其名称。 |
| 27 | public static File createTempFile(String prefix, String suffix) throws IOException 在默认临时文件目录中创建一个空文件,使用给定前缀和后缀生成其名称。 |
| 28 | public int compareTo(File pathname) 按字母顺序比较两个抽象路径名。 |
| 29 | public int compareTo(Object o) 按字母顺序比较抽象路径名与给定对象。 |
| 30 | public boolean equals(Object obj) 测试此抽象路径名与给定对象是否相等。 |
部分重要API测试代码:
package com.sinsy.file;
import java.io.File;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
public class FileTest
public static void main(String[] args)
//首先文件的输入: 使用地址来对FIle对象进行构造 文件夹的验证
File file = new File("C:\\\\Users\\\\Administrator\\\\Desktop");
System.out.println("是否是一个文件夹?"+file.isDirectory());
System.out.println("是否是一个文件?"+file.isFile());
System.out.println("文件夹是否存在?"+file.exists());
System.out.println("--------------------------------华丽的分割线--------------------------------------");
//文件的验证
File file1 = new File("C:\\\\Users\\\\Administrator\\\\Desktop\\\\22.docx");
System.out.println("是否是一个文件夹?"+file1.isDirectory());
System.out.println("是否是一个文件?"+file1.isFile());
System.out.println("文件是否存在?"+file1.exists());
System.out.println("获得文件的名字:"+file1.getName());
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = new Date(file1.lastModified());
System.out.println("文件的最后一次修改时间:"+dateFormat.format(date));
System.out.println("文件的绝对路径:"+file1.getAbsolutePath());
System.out.println("获得文件构造时参数中给出的路径"+file1.getPath());
System.out.println("获得文件的父级目录:"+file1.getParent());
try
System.out.println("文件的绝对路径,但会去除[..]这样的符号"+file1.getCanonicalPath());
catch (Exception e)
System.out.println("获得文件是否可读的信息?可以读吗?"+file1.canRead());
System.out.println("获得文件是否可写的信息?可以写吗?"+file1.canWrite());
System.out.println("获得文件是否可解释的信息?可解释吗?"+file1.canExecute());
System.out.println("--------------------------------华丽的分割线--------------------------------------");
try
System.out.println(new File("C:\\\\Users\\\\Administrator\\\\Desktop\\\\abc.txt").createNewFile());
catch (Exception exception)
测试结果:

注意!文件夹类型的File如何处理?
我们经过上面的了解,已经基本上对File的APi有了一个基本的了解,那么我们再来看一下,如果File是一个文件夹呢?我们在上面提到的File都是File文件类型,如果是文件夹类型那么也就是目录类型Direction类型。我们都知道在Windows中文件都是存储在文件夹之中,那么,问题来了,我们如果在实际业务场景中需要去通过Java搜寻文件,那应该如何做到呢?其实很简单!在没有其他业务因素影响下,最直接的思想就是将遍历每一个File对象,如果是文件夹那么递归调用,如果不是文件夹,而是我们需要的目标文件并且是以指定后缀名结尾的文件我们就这个文件保存下来即可。如何通过Java去对他进行实现呢?其实也不难,代码如下:
首先:代码展示
package com.sinsy.file;
import java.io.File;
import java.io.FileFilter;
import java.util.ArrayList;
import java.util.List;
/**
* @author fntp
*/
public class FileDirTest
private static List<File> fileList;
static
fileList = new ArrayList<>();
public static void main(String[] args)
File file = new File("D:\\\\测试");
getAllFile(file);
System.out.println(fileList);
getMarkFile(file);
/**
* 获得一个文件夹内部所有的文件
* @param file
* @return
*/
public static File getAllFile(File file)
if (file.isDirectory()&&file.listFiles().length>0)
//如果是文件夹那么直接遍历即可
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++)
if (files[i].isDirectory())
getAllFile(files[i]);
else
fileList.add(files[i]);
return file;
/**
* 返回指定结尾的文件
* @param file
*/
public static void getMarkFile(File file)
FileFilter filter = (path) ->return path.getName().endsWith(".doc");;
if (file.isDirectory()||file.listFiles().length>0)
//如果是文件夹并且文件夹内部有文件
File []files = file.listFiles(filter);
for (File file2 : files)
System.out.println(file2);
我们来看看测试后的结果吧:

以上便是对Java的File类的一个简单讲解以及File类的基础使用以及注意事项的讲解!接下来,我们继续来看今日的真正主角:JavaIO流!
今日主角:Java核心组件IO流(一)表层篇

JavaIO流重要API讲解图:
什么是IO流?
IO流在Java中扮演着一个很重要的角色,数据的输入输出,就是通过Java的IO流来进行实现的,所谓的I就是Input,输入的意思,举一个简单的例子,就是我们可以通过java将硬盘中的文件也就是File加载至内存中,来到内存之后,File内部的数据就都可以被Java读取到了,File加载至内存演变为Java中的数据的输入,这就是Input;O就是Output,I与O其实就是对立的,有in就有out,in是out的前提,你得有输入你才能有输出,你没有输入的话你拿什么去输出呢?这就好比我们熟悉的银行自动取款机ATM,我们不插入银行卡,取钱的时候他怎么给我们吐money呢?唉,对,一样的道理!有输入才有输出,原始的计算机就是这样,人机交互的前提也就是IO,计算机的必要设备就是IO,输入与输出。

知道了这些之后我们再来进一步了解,什么是IO:
IO:IO其实没有那么什么神秘就是Input和Output的缩写而已,即输入输出而已。(了解了吧)
NIO:NIO就是new IO,表层含义就是新的IO流,深层含义就是Non-Blocking I/O,也就是非阻塞IO,其实就是完成了IO的复用,旨在解决高并发,没什么别的意思,值得关注的是Channel,Buffer 和 Selector 三个核心的NIO的API组件除此之外也没有什么特别的,不要被这个称呼唬住了。
流:因为IO在程序内读写的时候,数据都传承一条线,抽象成水流一样,因而称之为流。先注意一个事情:流的英文翻译是:Stream。记住就行,因为后续一定会用到。
IO流的三种分类标准
-
读取数据量不同:一次读取一个字节:称之为字节流。一次读取一个字符:称之为字符流。一个字符等于两个字节。其实归根结底,最底层就是字节流。只不过区分的目的是:字节流可以读取任意类型的文件,而字符流自能读取文本文件(如txt文本等)。
-
读写方向不同:将文件加载进入内存属于读取文件的流程,此过程为输入流,将文件写出到本地硬盘的过程就输出流。
-
流的角色不同分为节点流和处理流:节点流主要指直接和输入输出源对接的流。而处理流主要指建立在节点流的基础之上的流也称之为包装流。在后续讲到Buffer的时候就会提及到。
**你不觉得奇怪吗?为什么字符流就只能读取文本文件,而字节流可以读取任意格式的文件?再有就是,为什么字节流已经这么强大了,还要字符流干嘛,不显得der吗?**我们先留下这个问题,后面再来解释!
JavaIO的体系结构:

主要概念-抽象基类:

我们都知道抽象类是为所有子类创建模板或者说叫规范,这样一来,子类继承了父类之后,子类需要去重写的还得去重写,这样对所有的子类都有一定的约束力。在JavaIO中的抽象基类一共是以下几种:InputStream,OutputStream,Reader,Writer。我们会发现,一组In与Out代表着输入与输出,一组Read与Write代表着读取与写入。In与Out这组在IO流中称之为字节流,也就是说,不管是In还是Out,他们所操作的数据都是字节流,都是在字节层面去处理数据。而Reader与Writer所操作的数据是字符流,不管是读还是写都是在字符层面去操作的数据。关于在字节层面与字符层面有什么优缺点我们也在后续的文章中会加以体现。那么接下来,正式开始讲解Java核心组件IO流的核心API!
一家独秀:字符流(FileWriter与FileReader)的的圣坛纷争
两家家族族谱
我们在前面讲过了将文件加载进入内存,也就是读取文件有两种方法,一种是直接使用FileInputStream字节流按照一个字节一个字节的方式去读取文件,将文件加载至内存中,这种方法称之为字节流,还讲了一种字符流的方法,这种字符流的读取文件的方式是一次读取一个字符,直到读完整个文件。接下来我们来看一下FileReader与FileWriter之间的具体关联。
要想解读FIleReader类与FileWriter类的实际用法,其实最简单的方法,最直接的方法就是去查看FIleReader与FileWriter的类结构!


我们可以清晰地看见,目标类FileReader继承至InputStreamReader,由于InputStreamReader继承于Reader,继而FileReader间接继承于Reader,Reader是一个抽象类,Reader实现了Readable与Closeable接口,Closeable接口又直接继承于AutoCloseable。所以FileReader类的家族关系一目了然,FileReader的所有API方法来直接来自于InputStreamReader。在下图中也得到了了证实。了解了FileReader的方法都是从哪里来的之后,接下来我们就开始使用FileReader的具体API方法,不过在此之前,请先记住,FileReader的直接父类是InputStreamReader!这点非常重要!
而FileWriter则是直接继承于OutPutStreamWriter这个类,OutputStreamWriter又直接继承于Writer类,很明显,Writer类是一个抽象类,这个Writer又实现了三个接口,分别是Appendable,Closeable,与Flushable。其中Closeable接口又直接继承于AutoCloseable接口,这个上面将FileReader的时候已经提过了。好的,这个类任然一样我们需要大致记得,他的直接父类是OutPutStreamWriter。
下图我列出FileReader与FileWriter的API方法来源:


看完上面这些图我们大致可以得出一些猜想:两个目标类FileWriter与FileReader的API方法肯定与他们的父类脱不了干系!如果更有兴趣的喜欢研究源码的童鞋肯定能发现,其实我们的猜想是正确的,这些类的API方法都是出自父类之手!下图为证:(以FileReader做为例子)
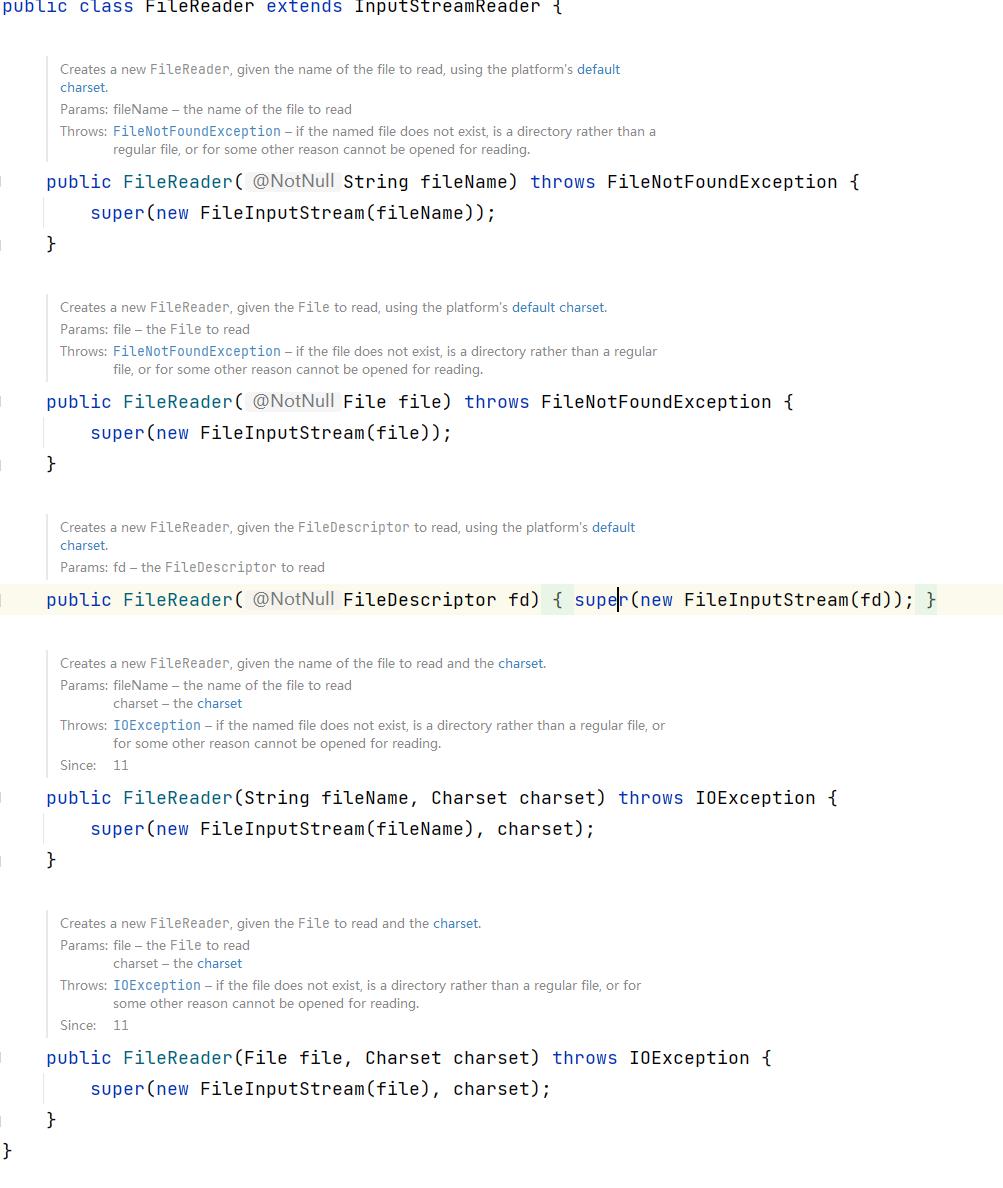
FileWriter与FIleReader的主要API具体实际用法:
(1)正所谓Reader嘛,不就是读吗?FileReader不就是文件读吗?简单一翻译,不就是读取文件吗?怎么读?我哪知道?看源码便知!
/**
* Reads characters into a portion of an array.
*
* @param cbuf Destination buffer
* @param offset Offset at which to start storing characters
* @param length Maximum number of characters to read
*
* @return The number of characters read, or -1 if the end of the
* stream has been reached
*
* @throws IOException If an I/O error occurs
* @throws IndexOutOfBoundsException @inheritDoc
*/
public int read(char cbuf[], int offset, int length) throws IOException
return sd.read(cbuf, offset, length);
哦,原来是字符流的方式去读取的,明着眼都看见了该方法使用了一个字符数组参数,间接告诉你,就是使用的是字符流去进行的读取,如果你还不放心,没关系,继续跟进源码:在InputStreamReader里面创建了一个StreamDecoder的对象sd,然后调用了该对象的read方法:
private final StreamDecoder sd;
//具体方法
public int read(char cbuf[], int offset, int length) throws IOException
int off = offset;
int len = length;
synchronized (lock)
ensureOpen();
if ((off < 0) || (off > cbuf.length) || (len < 0) ||
((off + len) > cbuf.length) || ((off + len) < 0))
throw new IndexOutOfBoundsException();
if (len == 0)
return 0;
int n = 0;
if (haveLeftoverChar)
// Copy the leftover char into the buffer
cbuf[off] = leftoverChar;
off++; len--;
haveLeftoverChar = false;
n = 1;
if ((len == 0) || !implReady())
// Return now if this is all we can produce w/o blocking
return n;
if (len == 1)
//使用字符数组,像 read() 一样对待单字符数组读取
int c = read0();
if (c == -1)
return (n == 0) ? -1 : n;
cbuf[off] = (char)c;
return n + 1;
return n + implRead(cbuf, off, off + len);
这下清楚了吧,为什么说他是字符流,因为底层使用的是字符的方法去加载FIle。那么如何使用呢?接下来我们根据字符流的底层原理,我们来实现不同的读取方式:
1.直接读取,装载进入字符数组
public static void read()
try
//创建FileReader对象,关联目标待读取文件
FileReader reader = new FileReader("D:\\\\a.txt");
//创建字符数组,做为待存储对象
char [] arr = new char[5];
//使用刚刚查看过的read方法进行读取 传入的是一个数组,读取的开始位置,读取的长度。
int ren = reader.read(arr,0,5);
//返回的ren是int类型的,其实代表的是读取到的字符个数 也就是5 最后将数组打印输出
//这里的数组就是File加载之后,我们将FIle中的数据按照字符的方法读取进入字符数组,存储指定长度的字符在字符数组中,然后打印字符数组
System.out.println(Arrays.toString(arr));
catch (IOException e)
e.printStackTrace();
finally
最后测试一下结果,验证一下我们的猜想:结果很完美,就是这么回事

2.直接读取,一个字符一个字符读取
public static void defaultRead()
try
//读数据关联文件
FileReader reader = new FileReader("D:\\\\a.txt");
// 声明方法体内部局部变量
int ren = 0;
//对变量再次赋值转换,将方法返回值直接做为读取判断依据
while ((ren=reader.read())!=-1)
//打印字符
System.out.print(((char) ren));
catch (IOException e)
e.printStackTrace();
finally
这里的read方法无参数,也就是默认的读取方法,不需要参数,实际上这个默认的read方法底层仍旧使用的是read的含参数方法,read(char cbuf[], int offset, int length),只不过默认的length是2,也就是默认一次读取的长度为2,可以比较一下,上面第一个直接读取方法中我们一次读取的长度为5。然后我们将这个方法进行打印测试:打印的结果为:(注意哦,为了缩减篇幅,打印使用的是pint()而非println())

FileWriter的加入:文件的写入操作
在讲解完这两种方法去使用字符流读取文件之后我们再来学习一下,如何使用FileWriter类进行写操作:
public static void writeFile(File file1,File file2)
FileReader fileReader = null;
FileWriter fileWriter = null;
try
//关联文件
fileReader = new FileReader(file1);
//判断文件是否可读?
System.out.println("文件是否可读?"+fileReader.ready());
System.out.println("file1的文件编码格式是:"+fileReader.getEncoding());
if (fileReader.ready())
//读取文件的初始化准备
int len = 0 ;
//创建写入的文件,对写操作进行文件关联
fileWriter = new FileWriter(file2);
//执行文件关联之后 开始进行文件写
while ((len=fileReader.read())!=-1)
//一边读一边写
fileWriter.write((char)len);
System.out.println("写入成功!");
catch (IOException e)
e.printStackTrace();
finally
try
fileWriter.flush();
fileReader.close();
fileWriter.close();
catch (IOException e)
e.printStackTrace();
也可以在第一个FIleReader的方法基础之上一边读一边写。这里就不做过多的描述了…贴一下测试结果:

多嘴一句:
你觉得这种字符流能读取图像文件和音频文件吗?来,我们看看吧:
public static void readImg(File imgFile,File file2)
FileReader reader = null;
FileWriter writer = null;
try
reader = new FileReader(imgFile);
int len = 0;
writer = new FileWriter(file2);
while ((len = reader.read())!=-1)
writer.write(len);
catch (IOException e)
e.printStackTrace();
finally
try
reader.close();
writer.flush();
writer.close();
catch (IOException e)
e.printStackTrace();
执行结果:看到了吧。字符流的读取和写入操作只能只针对于文本类型的文件才能执行成功!
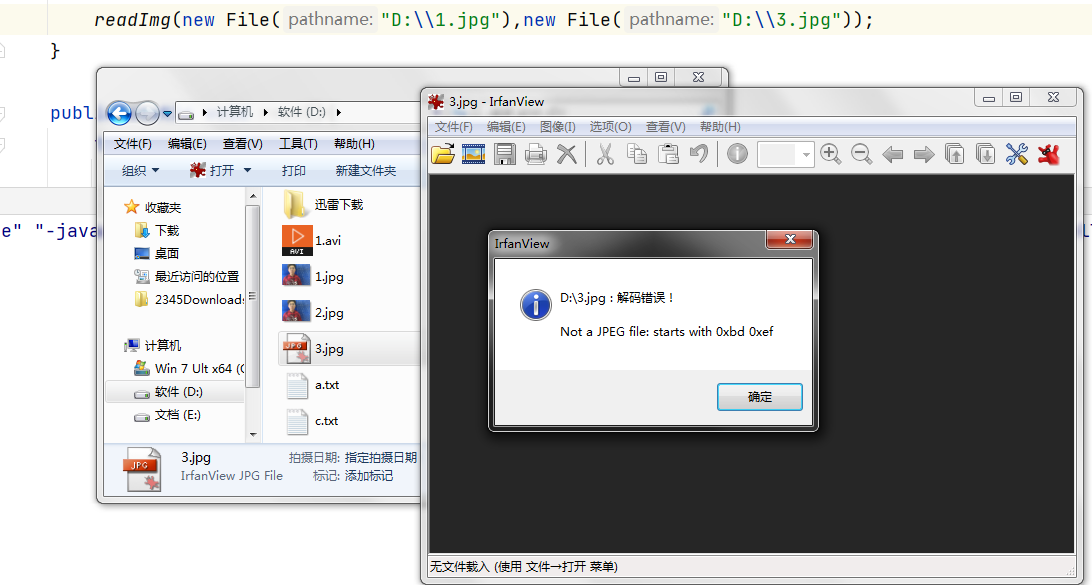
介绍了FileWriter与FileReader的基本使用(基本常用的API这里都提及了,涉及到底层的原理知识的这里只是粗略讲了一点,后续在第二篇里面会继续讲解底层原理),但是在开头的手我们说操作Java中的文件不仅仅只有一个FileWriter与FileReader这么简单,毕竟我们也说了操作文件可以用字符流也可以用字节流,况且字节流是支持所有文件类型的,而字符流只支持文本类型的数据,那么如何去使用字节流呢?字节流的操作文件的方法又有哪些呢?接下来我们可以通过简单的API使用来比较一下他们之间的区别!
重拳出击:FileInputStream组队FileOutPutStream与FileReader和FileWriter之间的PK

我们上文中讲到了使用FileReader类对文本文件进行读取,使用FileWrite类对字符流数据进行写入,通过实验我们发现,字符流操作工具类API无法完成对图像类文件数据的读取与写入,因此我们开始更换思路~使用FileInputStream与FileOutPutStream来对文件进行读写操作,特别是针对于图像类文件!
首先,为了方便使用,我将所有将会使用到的成员变量做一个简单的抽取:
private static FileInputStream inputStream = null;
private static FileOutputStream outputStream = null;
然后,我们开始讲解在IO字节流的基础之上,不依靠字节缓冲的方法,直接读取一个图像类型(图像类型的文件的后缀为多为:.JPG .PNG .BMP .GIF .JPEG)的文件。申明一个int类型的变量,这个变量保存的是inputSream流读取到的字节的个数,与内容无关哈,只是返回的是每一个原子读取的实际读取到的字节数,其实返回的是读取到的大小~我知道兄弟们说我口说无凭,我们还是让java来解释一下吧!我们采用反证法,如果打印出来是正常数据,那么我只需要采用响应的编码就可以将其转为我们能看得懂的数据,故此就有了下面这段代码:

于是,我们可以看到,将ren不在转为char类型的字符,而是直接将每次读取出来的流数据对应的int类型的数据直接打印出来,打印的结果是:全部是数字,这也间接证明了我们对返回值的一个简单理解,就是一次读取到的字节数,这里一定要与字符流相区别,为什么呢?因为字符流打印的时候我们是不是做过了实验,将读取到的每一次字符都可以由ASC码转成字符,**而这里,注意了啊!!!**不是字符了!为什么?

因为执行的目标文件是图像类型的了!我记得在某位博主的文章里曾经读到过,他讲字节流里面读取的所有数据,根据Read方法得到的返回值还是ASC,这不对啊,这就错了啊!这不是ASC,这是读取到的字节数,知道吧,这可不是ASC码啊,前面我们就讲过了,我还叫大家注意,FileReader与FileWriter的直接父类是InputStreamReader与OutputStreamWriter,他们的read与write方法都是直接继承于这两个父类的,所以执行的返回的结果就是来自于父类的。这两个类只能操作文本文件,对吧?再且父类中,按照字符的方式去读取加载文件内容的,如果是无参构造,那么返回的是每次读取到的字符的ASC,也就是对应的int类型的值,将这个值返回了,那如果是含参数的构造方法呢?那就不是了,那返回的就是读取到的字符个数了。知道了吧!?**要知道,read方法是有重载的哦!**所以你得看你执行的目标文件类型是什么类型,如果是文本那在读取的时候根据read方法的调用返回值只有长度与ASC码如果不是文本文件,那就是字节数和长度啦~

有人质疑不是字符的ASC吗?不信吗?可以鸭,我们来试验一下,我们将保存的读取到的编码值转为char类型的数据后打印:
try
inputStream =new FileInputStream(file);
outputStream = new FileOutputStream(new File(targetFileNameAndPath));
int ren = 0;
String a = "";
System.out.println("正在疯狂输出...");
while ((ren=inputStream.read())!=-1)
a+=(char)ren;
outputStream.write(ren);
System.out.println(a);
catch (IOException e)
e.printStackTrace();
结果为:

我们发现打印输出的结果乱码了!!!当然会乱码啊,至于为什么打印出来的结果乱码,我将会在后续的博客中去详细解释JPG位图与PNG等元素位图文件的组成原理以及java中的char编码范围等知识点,目前的话,在这里我们只需要知道,操作的文件是图像文件,并非文本文件。所以这里做了read方法的执行后返回的是每次读取流的个数,我们说read方法读取返回的是实际读取到的字节数,这些字节数目也间接代表了读取到的内容只是这种内容无法转成字符类型,懂了吧!所以不要跟文本文件的数据混淆哦!一定注意哦!
在实际测试后,我们发现,虽然字节流可以对字符流处理不了的图片类型的文件进行读写操作,但是缺始终无法做到快速,快速,这本是计算机处理问题的特点,到这里反而不行了,这是为什么呢?、
我们再来分析一下,当时我们是while循环,一次一次读,每次读取到的字节数不一致,有的多有的少,哦!!!原来是这样吗?是因为我们一次读取的字节数太少了,没法固定一个常量级别的范围,一次读取一个大范围内的字节数目,这样啊,那么我们
懒人思维,缓冲的挺进!
什么是缓冲?缓冲,这词在前几年可谓是各位老司机耳熟能详的词,在各种在线小影院随处可见缓冲二字,我们那个时候可能还没想到缓冲是什么玩意,经常看小电影的熊迪肯定不陌生啦,缓冲就是创建一个目标待加载空间,等待数据加载完毕,在执行播放…当然了这些对于大家来说都是简单的概念,哈哈,其实,缓冲不仅仅出现在小电影加速的场景中,在字符读取与字节读取的时候,其实也是可以通过缓冲来实现加快读取与写入的!废话不多说,今天借此机会来将缓冲引入IO流中!
方法总览:
/**
* 不使用缓冲区直接拷贝的直接方法 字节流缓冲
* @param file
* @param targetFileNameAndPath
*/
public static void copyImage(File file,String targetFileNameAndPath)
try
inputStream =new FileInputStream(file);
outputStream = new FileOutputStream(new File(targetFileNameAndPath));
int ren = 0;
System.out.println("正在疯狂输出...");
while ((ren=inputStream.read())!=-1)
outputStream.write(ren);
catch (IOException e)
e.printStackTrace();
finally
try
if (null!=inputStream)
inputStream.close();
if (null!=outputStream)
outputStream.close();
catch (Exception e)
e.printStackTrace();
(1)注意事项:读写操作非原子化进行:

首先字节输入流(所谓输入流嘛就是将需要读取的文件读取进入内存,这一步也称之为文件数据的加载)先加载数据,然后指定一个文件输出流的对象,该对象使用File类的实例进行的初始化,FIle类中还使用了含参数的构造方法对实例进行初始化,这个含参数的构造方法对FIle类的文件制定了文件名以及路径,至于路径是相对路径还是绝对路径取决于调用者的赋值。我们继续分析,当文件输入流赋值完毕后,开始读取目标文件,然后读取完毕后,开始进入输出,注意,我们是一边读取一边输出写出到本地文件。这个步骤并不是同步的,在宏观上看似两个动作同时进行,实则不然,这两个动作仍旧是分开的,先是进行的读,读完第一次之后,读的对象仍旧处于执行状态,并未关闭,此时写的对象进入工作状态,开始将刚刚读取到的数据进行写入。有人说,此时读与写都没有使用sychronied加锁,都是线程不安全的…真的是这样吗?我们吧底层代码贴出来看看:(以FileInputStream为例:)
(1)第一步:找到FileInputStream的继承关系,继承于直接父类:InputStream

(2)第二步:找到read()方法:第一次跟踪read()方法:

(3)第三步:找到read0()方法:发现是native修饰的方法,沃日,直接看看不了源代码…可真是失策,没事我们换一个类FIleReader吧!

我会在后续的过程中再去详细讲解为什么native修饰后方法无法直接查看,今天不能偏离主题了,就只讲IO流!
(4)找到FileReader的继承关系:

(5)找到相关的read()方法:

(6)找到最原始的方法:
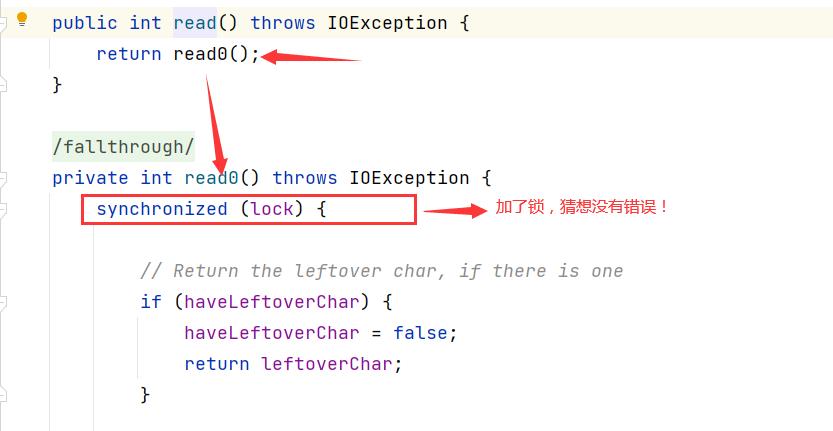
很多人容易将两次操作说成是线程不安全的操作,为什么?因为在直接父中没有看见使用synchronized关键字修饰方法,其实这是一个非常大的误区!为什么这么说,虽然读取到数据后立马将其写入本地文件中看似读取-写入两个步骤没有加锁但也有序进行,其实,读取的操作里面还有许多的流程,并且底层都使用sychronized锁关键字加以控制,无法直接看出这一一个的操作都是原子性操作,真实情况下,只有等读取这个大的流程结束了,才会轮到写操作,正因为操作是原子性的,并且此时我们已经知道了每次读到了多少字节,我们在写的时候我们就知道写多少字节,所以这么一看,看似同时进行的操作实际上是分开的,这就是隐含其中的原子性操作。这也同时证明了一点:分析问题不能只看表面!切记!切记!
什么是原子性:
原子性更多的出现在数据库中,指一次事务的所有操作要么不间断地全部被执行,要么一个也没有执行。
简单来理解:某一天,你躺在寝室里,悠闲自在地在某宝上买肥宅快乐水,在你选择好商品参数信息后,选择付款,进入付款页面,进入输入密码的时候,这个时候,突然蹭你热点的好室友为了下载小电影把你的流量耗光还超额了,就在这个时候,你正在输入密码,原本输入了正确密码,手机却突然停机了,这个时候,你付款的操作被意外终止了,这样,由于你没能付款成功,订单会意外挂起,在挂起十分钟过后资源进行了释放,这个过程中,购物就是一个原子性操作,因为受到网络的干扰,导致你的购物流程遭到意外打断,导致最后你要买的商品的数量数量又恢复了原始数量。
相信通过上面的例子,你很快就知道了什么是原子性,没错,对应到购物场景中,就是取决你有没有支付成功,成功了就是成功了,没成功就是没成功。一旦付款操作没有顺利结束,那么原始订单数据就会回滚,回滚至原始状态,付款成功与商品数量是想关联的,要么一起成功,付款成功,商品数量减一,付款失败,商品数量不变。
inputStream =new FileInputStream(file);
outputStream = new FileOutputStream(new File(targetFileNameAndPath));
int ren = 0;
System.out.println("正在疯狂输出...");
while ((ren=inputStream.read())!=-1)
outputStream.write(ren);
我们注意到,执行完毕这段代码后,关闭输入输出流的时候,会有一个异常需要抛出:原因其实很简单,是因为在关闭流的时候,调用了close方法,而这个close方法会抛出一个异常,所以我们需要抛出一个异常!

对于这种异常的处理,在我的《Java中的Exception异常机制(一)》中提到了如何去处理这种异常,这里就不做过多的赘述。
处理完异常之后,我们观察执行结果:
(1)D盘下的文件列表:

(2)执行转后的结果为:帅气的照片被复制了一份,成了两份。(这里有一个小的误差,应该先关闭FileOutPutStream的对象在关闭FileInputStream的对象)

关于文件复制的缓冲思考:
我们在执行文件复制操作的时候,经过试验,发现这种字节输入输出流的方法,同时进行读写操作的文件复制行为,对于小文件来说,几MB的图片或者是几十KB的文本文件,处理起来速度已经不是很快了,随着这种读写方法支持所有类型的文件,但是总不能让所有的读写操作都来使用这一种操作的方法吧!所以,我们需要追求更高效的方法,使用缓冲的概念来执行读写文件!
我们说,要复制一个文件,我们首先得出这个文件的总大小,然后创建一个与文件大小一致的文件缓冲区,在读写文件的时候,我们直接将文件的数据写入到这个数组中,然后在想数组中的数据全部写入到本地文件中,这样就完成了数据的复制。
/**
* 使用缓冲区直接拷贝的第一种直接方法:使用与文件大小一致的文件缓冲区
* @param file
* @param targetFileNameAndPath
*/
public static void copyVideo(File file,String targetFileNameAndPath)
try
inputStream =new FileInputStream(file);
outputStream = new FileOutputStream(new File(targetFileNameAndPath));
byte arr[] = new byte[inputStream.available()];
int len = inputStream.read(arr);//返回的是读取的内容大小,也就是装在进入缓冲区的内容大小
System.out.println(len);
System.out.println("正在疯狂输出...");
outputStream.write(arr);
catch (IOException e)
e.printStackTrace();
finally
try
if (null!=inputStream)
inputStream.close();
if (null!=outputStream)
outputStream.close();
catch (Exception e)
e.printStackTrace();
问题他又来了!理想很丰满,现实很骨感!
是的,这么创建缓冲的确是可以解决问问题。但是如果在公司了这么写,每次都这样搞,根据所要操作的文件的大小来创建相应的大小的缓冲空间,而每一次都这样申请,万一等待操作的文件几十个GB那还不晕倒,卷铺盖卷走人了就,真这么写就恭喜了!喜提离职Offer…不用缓冲不是,用了缓冲更不行,那到底应该怎么做呢?

我们说,用缓冲是肯定的,但是怎么用我们还有讲究!我们仔细思考一下,为什么上面的做法欠妥?还不是因为每一次申请那么大的空间浪费了资源吗,既然一要快速,二要节省资源,那我们就需要对缓冲再做一下细化!如何细化?我们开始做的缓冲设计的缓冲数组空间大小是待处理数据的大小,现在不能根据待处理数据大小来定义,应该设
以上是关于Java核心组件IO流表层篇的主要内容,如果未能解决你的问题,请参考以下文章