Flink内核原理学习内存模型
Posted oahaijgnahz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink内核原理学习内存模型相关的知识,希望对你有一定的参考价值。
Flink内核原理学习之 内存模型
文章目录
一、JVM内存管理的缺点
目前,大数据计算引擎主要用 Java 或是基于 JVM 的编程语言实现的,Java 语言的好处在于程序员不需要太关注底层内存资源的管理,但同样会面临一个问题,就是如何在内存中存储大量的数据 (包括缓存和高效处理)。JVM的内存管理具有以下的缺点:
- Java 对象存储密度低:Java 的对象在内存中存储包含 3 个主要部分:对象头、实例数据、对齐填充部分。例如,一个只包含 boolean 属性的对象占 16byte:对象头占 8byte, boolean 属性占 1byte,为了对齐达到 8 的倍数额外占 7byte。而实际上只需要一个 bit(1/8 字节)就够了。
- Full GC 会极大地影响性能:尤其是为了处理更大数据而开了很大内存空间的 JVM 来说,GC 会达到秒级甚至分钟级(堆内存占用内存大,老年代垃圾回收耗时)。
- OOM 问题影响稳定性:OutOfMemoryError 是分布式计算框架经常会遇到的问题, 当 JVM 中所有对象大小超过分配给 JVM 的内存大小时,就会发生 OutOfMemoryError 错误, 导致 JVM 崩溃,分布式框架的健壮性和性能都会受到影响。
- 缓存未命中问题:CPU 进行计算的时候,是从 CPU 缓存中获取数据。现代体系的 CPU 会有多级缓存,而加载的时候是以 Cache Line 为单位加载。如果能够将对象连续存储, 缓存命中概率就高。使得 CPU 集中处理业务,而不是空转。而Java 对象在堆上存储的时候并不是连续的,所以从内存中读取 Java 对象时,缓存的邻近的内存区域的数据往往不是 CPU 下 一步计算所需要的,这就是缓存未命中。此时 CPU 需要空转等待从内存中重新读取数据,如此会降低CPU执行效率。
因此,Flink大量采用JVM直接内存,将对象序列化到预分配的一块或多块内存块上(MemorySement)作为FIink中的最小内存分配单元,并提供高效的读写方法,很多运算也能直接操作二进制数据。
二、TaskManager内存模型
Flink 1.10 对 TaskManager 的内存模型和 Flink 应用程序的配置选项进行了重大更改,让用户能够更加严格地控制其内存开销jobmanager.memory.process.size: 1600m。这里就需要引出其内存模型。
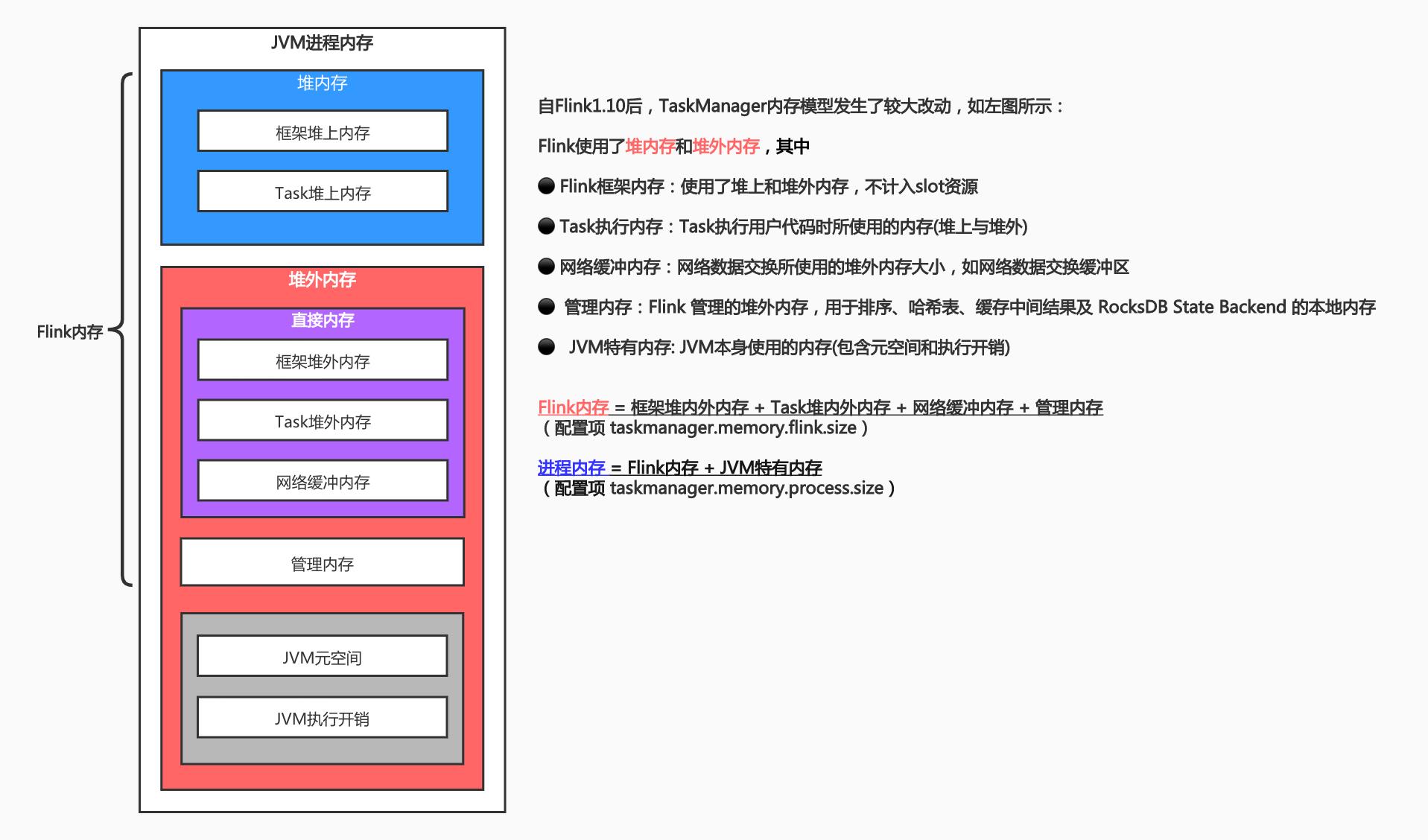
另外JobManager也是使用堆内存、堆外内存,并在1.11版本后与TM统一了配置
三、内存数据结构
- 内存段
内存段在 Flink 内部叫 MemorySegment,是 Flink 中最小的内存分配单元,默认大小32KB。它既可以是堆上内存(Java 的 byte[]),也可以是堆外内存(基于 Netty 的DirectByteBuffer),同时提供了对二进制数据进行读取和写入的方法。
以一个Tuple3<Integer,Double,Person>对象的存储为例来理解对象序列化到内存段的过程:
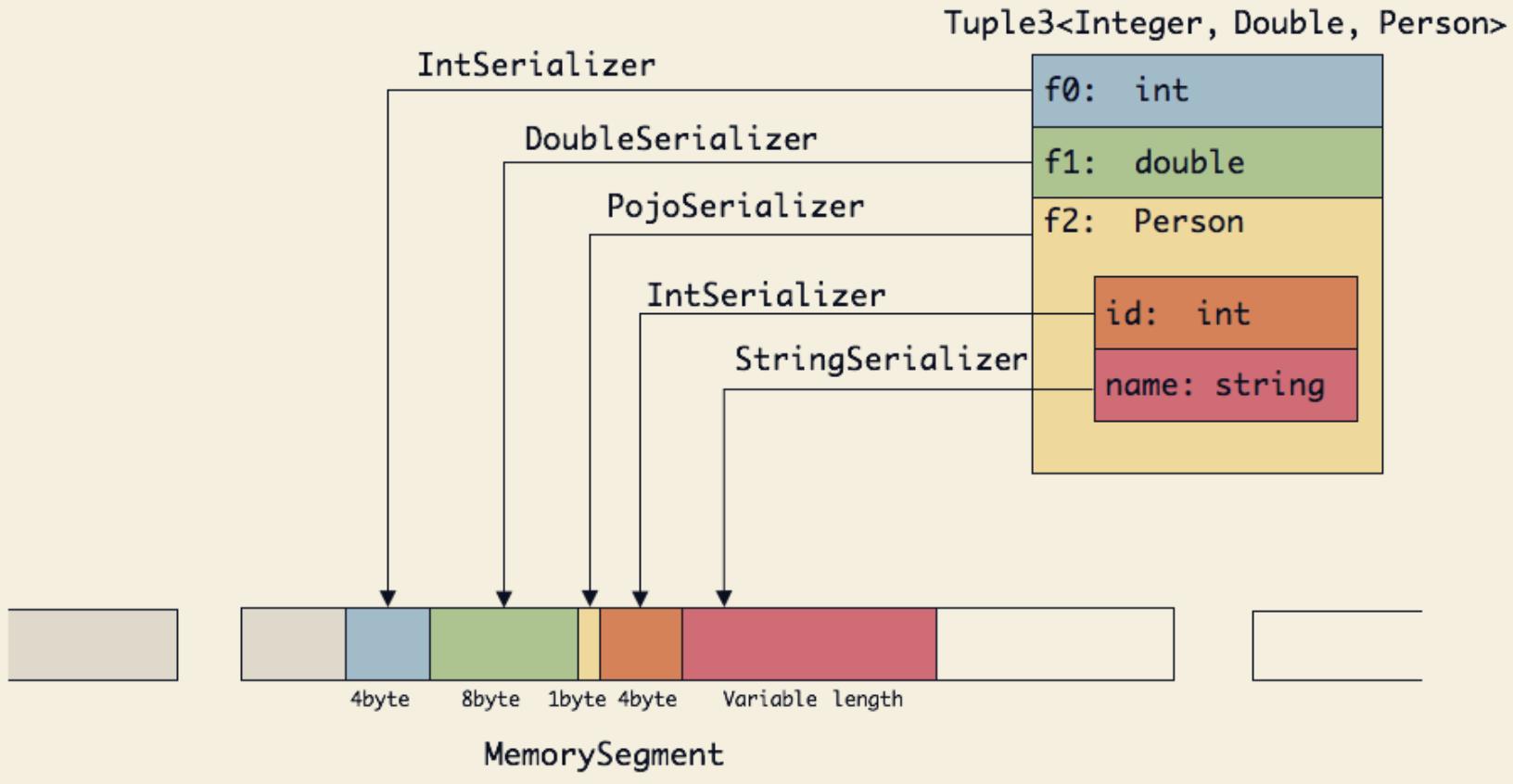
可以看出这种序列化方式存储密度是相当紧凑的。其中 int 占 4 字节,double 占 8 字节,POJO 多个1字节的 header。PojoSerializer 只负责将 header 序列化进去,并委托每个字段对应的 serializer 对字段进行序列化。
- 内存页
内存页是 MemorySegment 之上的数据访问视图,数据读取抽象为 DataInputView, 数据写入抽象为 DataOutputView。使用时就无需关心 MemorySegment 的细节,会自动处理跨 MemorySegment 的读取和写入(可以理解为多个内存段封装成了页面,用户只需要知道在哪个页面,剩下的内容查找就可以让内存页去完成)。
- Buffer
Task 算子之间在网络层面上传输数据,使用的是 Buffer,申请和释放由 Flink 自行管理,实现类为 NetworkBuffer。一个 NetworkBuffer 包装了一个 MemorySegment。同时继承了 AbstractReferenceCountedByteBuf(Netty 中的抽象类)。
public class NetworkBuffer
extends AbstractReferenceCountedByteBuf
implements Buffer
/** The backing @link MemorySegment instance. */
private final MemorySegment memorySegment;
... ...
补充下Netty的ByteBuf的特点:双指针读写分离、动态扩容、零拷贝机制(只是应用层面的零拷贝,ByteBuf直接引用数组内存地址的内容)、pooledByteBuf还有内存复用。
- Buffer资源池
BufferPool 用来管理 Buffer,包含 Buffer 的申请、释放、销毁、可用 Buffer 通知等,实现类是 LocalBufferPool,每个 Task 拥有自己的 LocalBufferPool(一般是多个 )。
BufferPoolFactory 用来提供 BufferPool 的创建和销毁,唯一的实现类是 NetworkBufferPool,每个 TaskManager 只有一个 NetworkBufferPool。同一个 TaskManager 上的 Task 共享 NetworkBufferPool,在 TaskManager 启动的时候创建并分配内存。
四、网络传输中的内存管理
4.1 网络IO内存管理
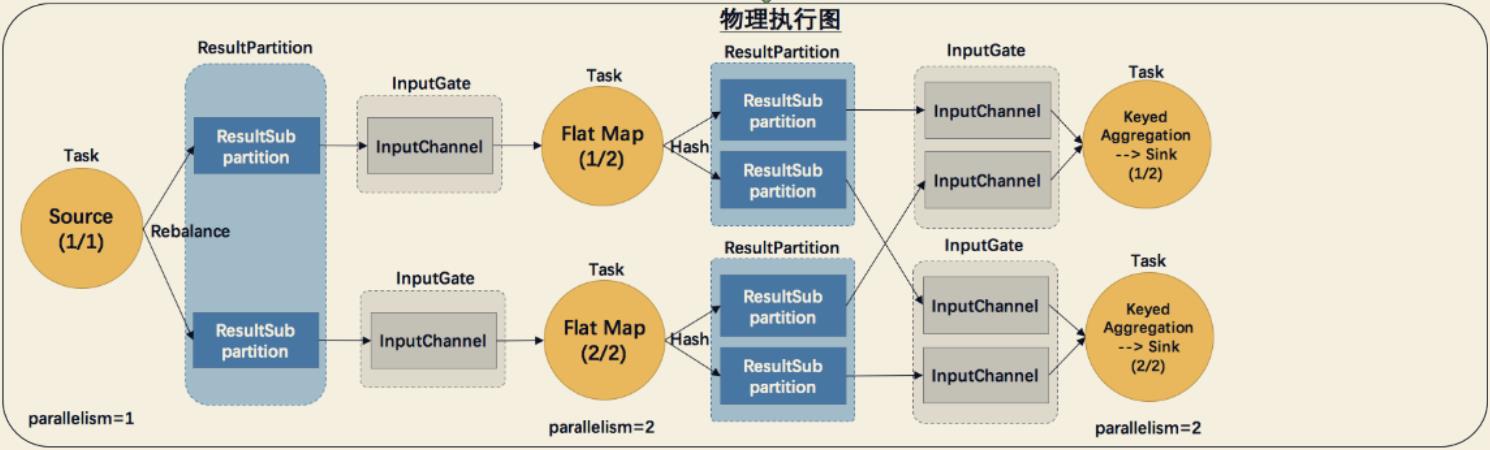
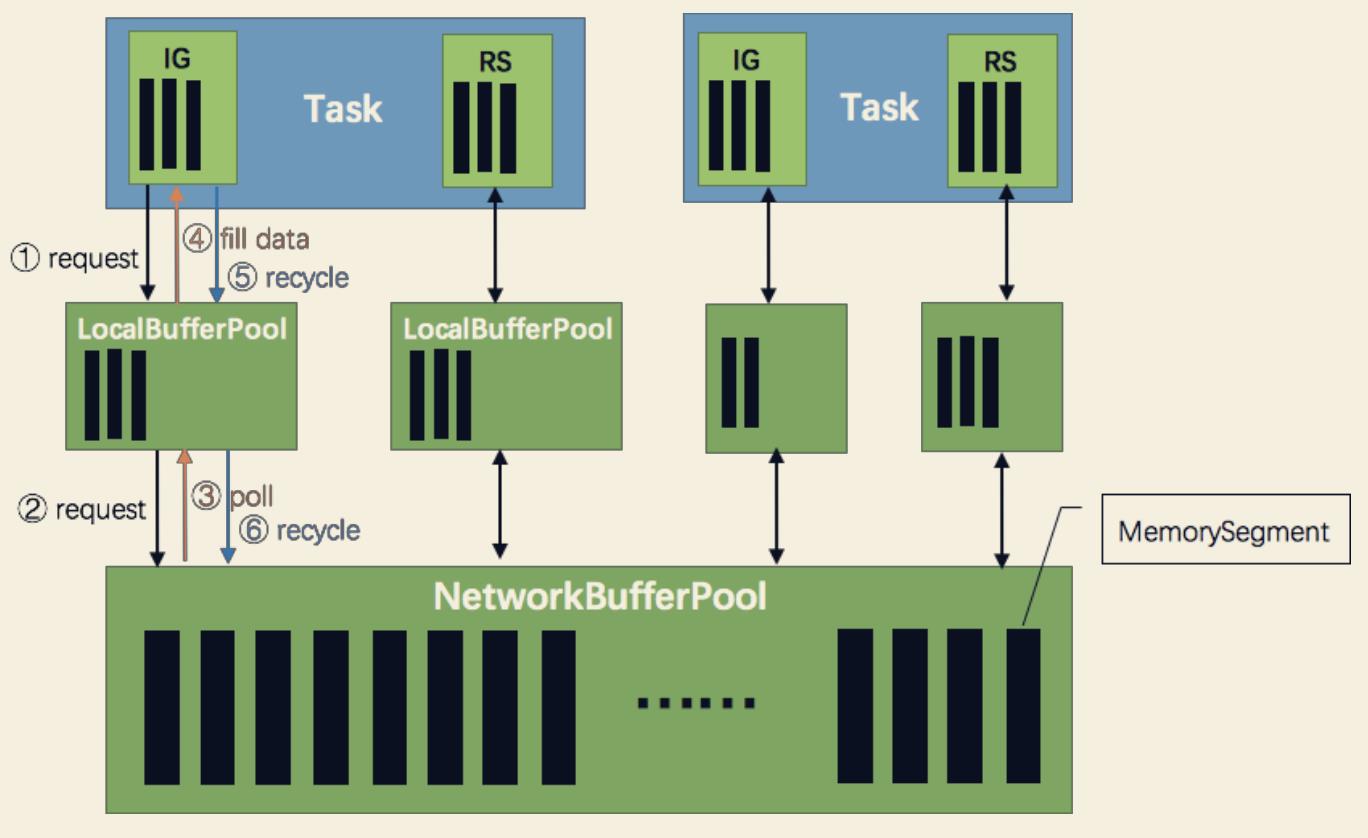
网络传输的过程需要与物理执行图对照理解:
网络上传输的数据会写到 Task 的 InputGate(IG)中,经过 Task 的处理后,再由 Task 写到ResultPartition(RS) 中。每个 Task 都包括了输入和输入,输入和输出的数据存在 Buffer 中(都是字节数据)。Buffer 是 MemorySegment 的包装类。
-
TaskManager(TM) 在启动时,会先初始化 NetworkEnvironment 对象,TM 中所有与网络相关的东西都由该类来管理(如 Netty 连接),其中就包括 NetworkBufferPool。根据 配置,Flink 会在 NetworkBufferPool 中生成一定数量(默认 2048)的内存块 MemorySegment,内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共享的,每个 TM 只会实例化一个。
-
Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG) 和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment数量(IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存块数量与 RP 中的 ResultSubpartition 数量一致)。
不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬时压力(如GC),充分利用那部分闲置的内存块,不会频繁地进入反压状态。
-
在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中,InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的②)并交给 InputChannel 填上数据(上图中的③和④)。当 Task 线程通过 ResultPartition 写数据到缓存时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
如果缓冲池已申请的数量达到上限或者 NetworkBufferPool 也没有可用内存块了呢?
这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止发送,拓扑会进入反压状态。 -
当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了, 在输出端是指内存块中的字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上图中的⑤)。如果 LocalBufferPool 中当前申请的数量超过了池子容量(上文提到的动态容量,可能由于新注册的 Task 导致该池子容量变小),则 LocalBufferPool 会将该内存块回收给 NetworkBufferPool(上图中的⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
4.2 反压机制
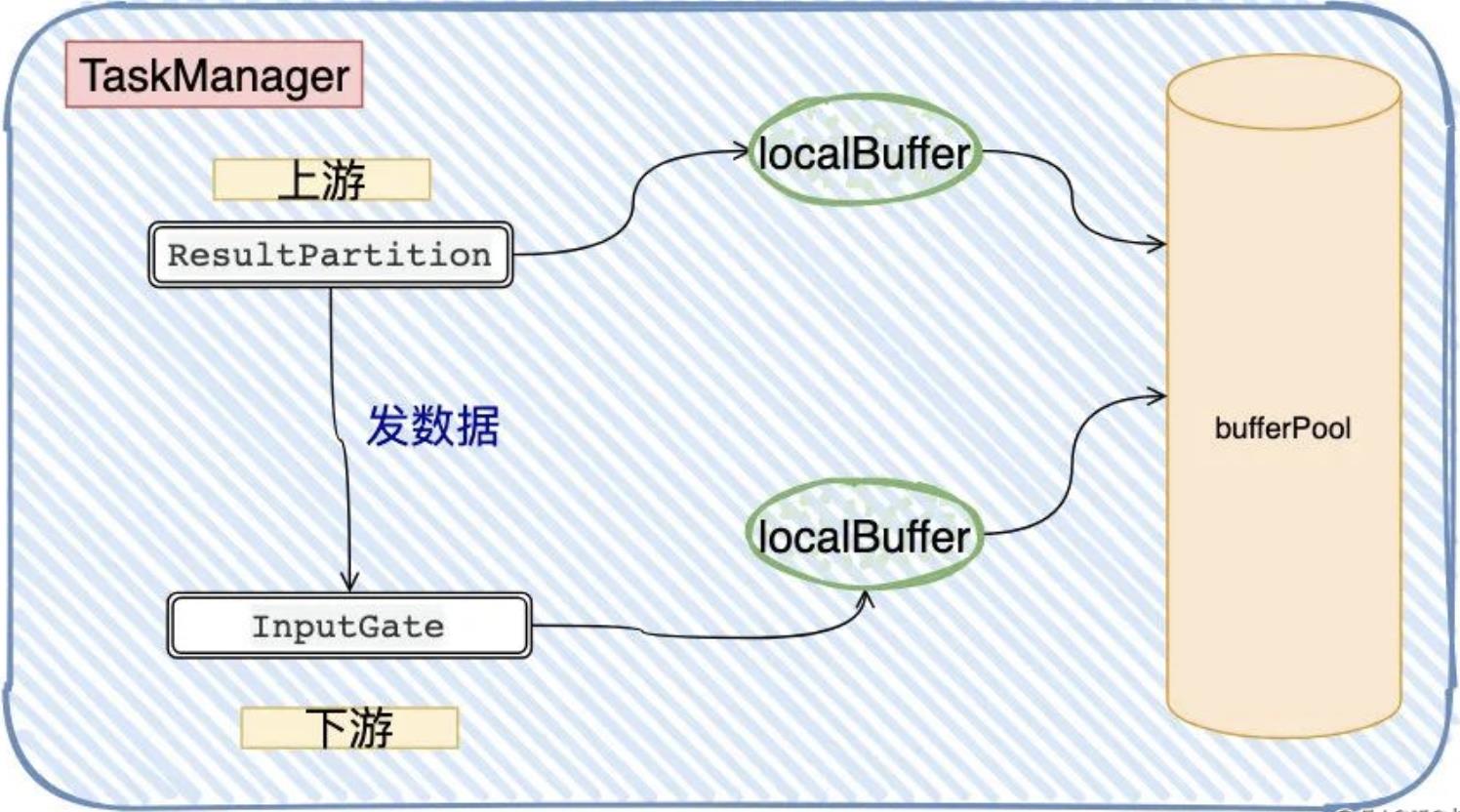
以上图为例,假设下游处理不过来,那 InputGate 的 LocalBuffer 被填满了,ResultPartition 没办法往InputGate发送数据,而 ResultPartition 没法发的话,它自己本身的LocalBuffer 也迟早被填满,依照这个逻辑,压力一直传导到Source,Source就不会拉数据。这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。
从上面我们看到的Flink所实现的反压,宏观上就是直接依赖各个Buffer是否满了,如果满了则无法写入/读取导致连锁反应,直至Source端。
而基于credit机制,实际上可以简单理解为以「更细粒度」去做流量控制:每次 InputGate 会告诉 ResultPartition 自己还有多少的空闲量可以接收,让 ResultPartition 看着发。如果 InputGate 告诉 ResultPartition 已经没有空闲量了(credit == 0),那 ResultPartition 就不发了。
以上是关于Flink内核原理学习内存模型的主要内容,如果未能解决你的问题,请参考以下文章