pandas根据列数据的值范围计数?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas根据列数据的值范围计数?相关的知识,希望对你有一定的参考价值。
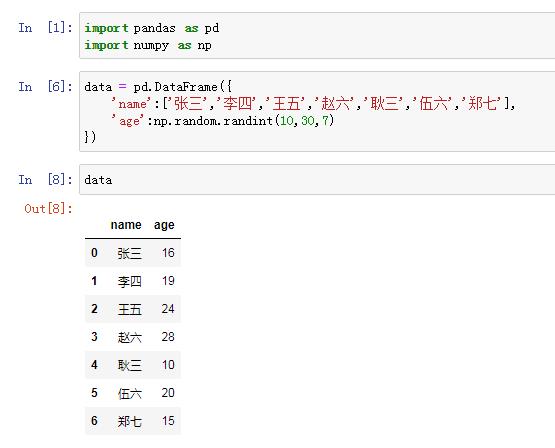
假设有这么一个DataFrame数据:有两列,name列为姓名,age列为年龄,其中年龄为随机生成,如下图:
我们可以使用loc来得到age>20的行:
data.loc[条件]
其中条件为data['age']>20
即:data.loc[data['age']>20]
这样就会得到age>20的所有行数据(包括所有列)。

如果我们并不需要所有所有列,那可以再指定要保留的列:
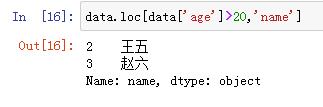
data.loc[data['age']>20,'name']
这样就会得到age>20的所有行的数据(只包括name列)。
data.loc[条件]其中条件为data['age']>20即:data.loc[data['age']>20]这样就会得到age>20的所有行数据(包括所有列)。如果我们并不需要所有所有列,那可以再指定要保留的列:data.loc[data['age']>20,'name']这样就会得到age>20的所有行的数据(只包括name列)。 参考技术B
统计数据表格中‘状态’列中有哪几类状态,每个状态出现了多少次上述代码段 aggfunc='count',表示对状态列中出现的每个值计数。
根据 Pandas 中另一列中的值范围聚合一列的内容
【中文标题】根据 Pandas 中另一列中的值范围聚合一列的内容【英文标题】:Aggregate contents of a column based on the range of values in another column in Pandas 【发布时间】:2020-09-24 14:13:58 【问题描述】:我正在根据给定列中的值范围聚合数据框的内容。我的df 如下所示:
min max names
1 5 ['a','b']
0 5 ['d']
6 8 ['a','c']
3 4 ['e','a']
预期的输出是
对于min=0 和max=5,获取聚合值,因此名称值为['a','b','d','e','a']
对于min=5和max=10,获取聚合值,名称值为['a','d']
感谢任何帮助。
【问题讨论】:
是否应该将其转换为列?你能发布预期的输出吗 预期的输出是列表。 【参考方案1】:最直观的方法是过滤然后聚合。为了解决您的具体问题,我会这样做:
>> df = pd.DataFrame("min": [1, 0, 6, 3],
"max": [5, 5, 8, 4],
"value": [['a','b'], ['d'], ['a','c'], ['e','a']])
>> print(df)
min max value
0 1 5 [a, b]
1 0 5 [d]
2 6 8 [a, c]
3 3 4 [e, a]
>> sum_filtered_values = df[(df["max"]<=5) & (df["min"]>=0)].value.sum()
>> print(sum_filtered_values)
['a', 'b', 'd', 'e', 'a']
>> sum_filtered_values = df[(df["max"]<=10) & (df["min"]>=5)].value.sum()
>> print(sum_filtered_values)
['a', 'c']
【讨论】:
以上是关于pandas根据列数据的值范围计数?的主要内容,如果未能解决你的问题,请参考以下文章